
一种基于EVDO 分组域可视电话业务源模型
2013-12-14 01:36孙瑞杰
重庆邮电大学学报(自然科学版) 2013年3期
明 艳,李 强,孙瑞杰
(重庆邮电大学信号与信息处理重庆市重点实验室,重庆400065)
0 引言
移动可视电话业务作为3G的特色业务,实现了移动用户端到端的音视频双向实时通信,给用户带来了全新的视听感受。因此,该业务备受电信运营商和手机制造商的青睐。移动可视电话业务在TD-SCDMA和WCDMA中是通过电路域来实现,而在EVDO(evolution-data optimized)中则是通过分组方式来实现的。在分组域中,可视电话业务的控制信息、音频数据和视频数据是通过3个不同的服务质量(quality of service,QoS)流进行传输[1],并且在传输数据之前,必须进行QoS流的激活。这个激活的过程包括了资源的预留、确定接入网和核心网接口的映射关系等。
业务模型的建立是分析网络性能、科学规划网络的基础。传统的电路业务主要是用泊松(Poisson)模型进行描述[2]。由于数据业务具有突发性,汇聚的业务流又表现出自相似的特点,因此有必要建立分组业务的源模型。本文根据EVDO网络分组域可视电话业务的实现方式和业务性质,对音频流和视频流分开建立源模型。首先,根据会话类业务用户行为的特点,用Poisson模型来描述会话层。然后,根据音频流和视频流的业务特性和传输特性,采用合理的参数对突发层和数据包层进行描述。最后,对模型参数及分布进行求取和拟合。
1 分组域可视电话业务源模型的建立
1.1 移动可视电话业务用户行为模型
EVDO分组域可视电话业务属于实时会话类业务。该业务用户的呼叫到达过程可以用Poisson过程进行描述,即用呼叫到达间隔时间和单用户平均呼叫时长来描述。而这2个参数均服从指数分布[3],指数分布概率密度函数为

1.2 音视频源性质
在EVDO中,由于可视电话业务的音频流和视频流采用了不同的压缩协议,具有不同的业务流性质,因此,本文对这2种多媒体流分开进行研究。
对于音频流,EVDO移动终端采用EVRC(enhanced variable rate codec)和EVRC-B(enhanced variable rate codec B)的压缩编码标准。EVRC编码器把一个经过8 kHz采样、16 bit量化的20 ms帧压缩成4种不同速率的输出码流:全速率8.8 kbit/s,1/2速率4.0 kbit/s,1/4 速率2.0 kbit/s和1/8 速率0.8 kbit/s。通常对语音压缩编码采用全速率或1/2速率编码[4]。由于人的语音通话可分为讲话期和听话期,即激活期和静默期。在激活期,音频源以固定速率发送数据包。而在静默期,没有数据包发送。因此,可以用ON/OFF模型对其进行描述。
对于视频信号,EVDO终端支持H.263,MPEG-4和H.264/AVC视频压缩编码协议。对于H.264/AVC编码分为 3个档次:Baseline,Extended和Main。Baseline主要用于实时的视频交互,如视频会议和可视电话等业务。Extended主要用于网络的视频流业务,如视频点播等。Main主要用于电子应用,如数字电视广播、数字视频存储等[5]。在Baseline中,只包含帧内编码I帧和单向预测帧间编码P帧,并不编码双向预测B帧。该档次虽提高了编码实时性,但视频质量一般。而在Extended和Main中,要编码B帧,虽提高了视频传输的抗误码性能,但编码实时性较差。在移动可视电话业务中,一般选择Baseline。视频帧之间虽然存在很大的相关性,但是,当图像背景发生变化时,如在移动中进行视频通信时,编码输出数据量较大,这时需通过缓冲和调整各帧量化参数来缓解编码速率的增大,以保持业务输出速率的恒定。
1.3 协议对数据包大小的影响
在传输音视频数据流时,EVDO采用了如图1所示的RTP/UDP/IP(real-time protocol/user datagram protocol/internet protocol)分层协议结构[6]。

图1 数据流传输分层协议结构Fig.1 Date stream transmission layer protocol structure
由于IPv4(internet protocol version 4)的固定头部占用20 Byte,UDP的头部信息占用8 Byte,RTP的头部占用12 Byte,而IP数据包的有效负荷长度不超过1 400 Byte。采用IPv4的RTP/UDP/IP协议总头部信息就要占用40 Byte,在传输音频数据时,一般每20 ms发送一个分组,这样包头的数据速率就达到了16 kbit/s,这严重影响了数据包的传输效率。因此,采用ROHC(robust header compression)协议对包头信息进行压缩,以提高带宽利用率。
1.4 音视频的RTP打包
对于音频流来说,考虑系统带宽的利用效率,采用把全速率20 ms的一个音频帧打包成RTP包的方式。这样在激活期,音频帧数据包就以固定的速率被发送出去,每个数据包的大小、发送每个RTP包的间隔时间也是固定的。
由于视频流的数据量较大,在IP层需进行分段,把超过1 380 Byte的 NAL(network abstraction layer)单元进行分片,把每个分片打包成一个RTP包,每个分片的RTP包的时间戳相同。把每个不超过1 380 Byte的NAL单元打包成一个RTP包,每发送一个此类RTP包,时间戳都增加相应的量。
下面选取300帧QCIF格式的视频测试序列salesman,用Baseline压缩档按照IPPPPPPPPP的压缩模式进行压缩,即每隔10帧编码一帧I帧。把压缩后的码流按照上述RTP打包方法进行打包和传输,用软件解析出的RTP包的具体信息如图2所示。从图2可以看出,无论是I帧还是P帧,都打包成6个数据包,并且每个RTP包的时间戳都不相同,说明压缩后码流中的NAL单元并没有进行分片。

图2 解析出的RTP信息Fig.2 Extracted RTP information
1.5 音视频源分层建模
通过上述分析,对音频流采用3层模型进行建模。第1层用会话层来描述用户的行为,第2层用突发层来描述音频流的激活期和静默期,第3层用数据包层来描述激活期产生数据包的具体情况。模型结构如图3所示。对于视频流,由于用户会话期间一直有数据包的产生,采用如图4所示的2层模型对其进行描述。第1层和音频模型一样用来描述用户的行为,第2层的数据包层用来描述视频流具体数据包传送情况。
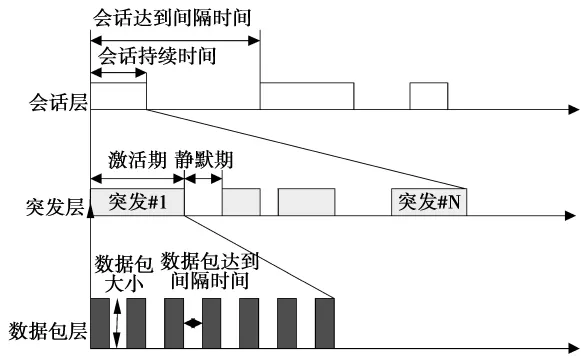
图3 音频源3层模型Fig.3 Audio source three-layer model
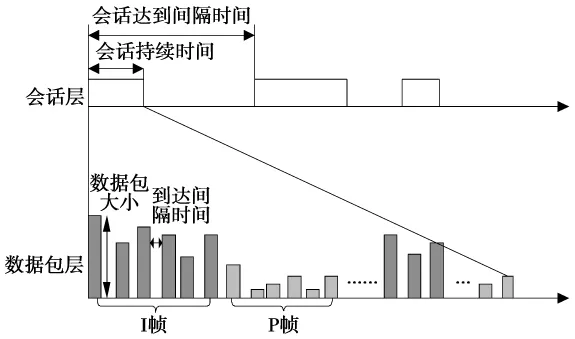
图4 视频源2层模型Fig.4 Video source two-layer model
分组可视电话业务源模型的建立,关键要选取合适的模型参数来描述每种业务流。本文根据各媒体流压缩标准以及传输协议,选取的参数如下。
1)用户行为:选取会话到达间隔时间和会话持续时间2个参数。
2)音频数据流:采用激活期平均占用时长、静默期平均占用时长、激活期数据包到达间隔时间和激活期数据包大小4个参数。
3)视频数据流:由于I帧和P帧编码后输出数据量不同,所以要对I帧和P帧分开进行描述。首先是帧率的选择,帧率一般都是定值;然后是I帧和P帧所包含的数据包个数以及所包含的数据包的大小;最后是视频帧数据包的到达时间间隔。
2 模型参数的估计
模型参数确立后,根据实际数据,统计和计算参数的取值范围,拟合出参数服从的分布。用户达到过程用Poisson模型进行拟合,会话到达间隔时间和会话平均持续时间都服从指数分布。对于音频流模型,可以参考VoIP源模型的参数取值和分布,即静默期和激活期都服从负指数分布,数据包大小为定值,数据包到达间隔时间为定值[7]。对于视频流模型,由于移动可视电话用户通话可能处在两种不同的场景下:静止场景和移动场景。因此,本文选择salesman和silent序列模拟用户在静止场景下的情况,选择carphone和coastguard序列模拟用户在移动场景下的情况。测试序列图像如图5所示。通过对RTP包的统计,得到这4个序列数据包大小的概率密度函数如图6-图10所示。
从图6-图9可以看出,对于不同类型的视频序列,P帧数据包大小所服从的分布基本上一致,均可用截断的Pareto分布[8]进行拟合,不同之处是概率密度函数的坡度不一样。因此,2种场景下的P帧数据包大小的分布函数可用不同特征参数值下的截断Pareto进行描述。从图10可以看出,对于I帧来说,由于采用帧内编码方式,输出码流与图像的细节信息密切相关。无论是静止场景还是移动场景,I帧数据包都可以用截断的正态分布进行拟合。经统计,I帧数据包的最小值取90 Byte,最大值取1 100 Byte。而数据包的达到间隔时间可用截断的Pareto分布进行拟合。分组域可视电话业务源模型参数取值及分布拟合如表1所示,两种不同场景下的P帧数据包大小的参数取值及分布如表2所示。

图5 测试序列图像Fig.5 Images of testing sequences

图6 salesman P帧数据包大小的概率密度函数Fig.6 PDF of P frame data package of salesman
分组域可视电话业务的源模型建立后,可根据模型参数及其取值,产生该业务源的输出。如果能得传输该业务的网络指标,如时延、抖动、误码率以及吞吐量等,即可分析系统的性能,估算出系统的容量。因此,该业务源模型可用于网络仿真。但在实际应用前,需对建网后的实际数据进行统计分析,并对该模型参数进行修正。
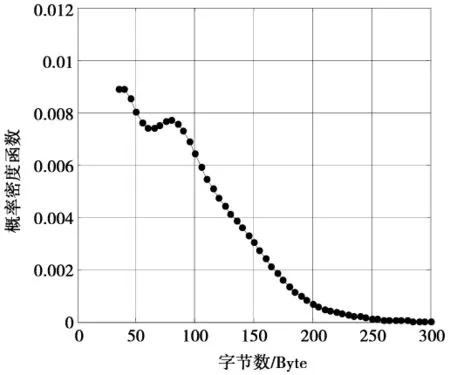
图8 carphone P帧数据包大小的概率密度函数Fig.8 PDF of P frame data package of carphone

图9 coastguard P帧数据包大小的概率密度函数Fig.9 PDF of P frame data package of coastguard
拟合的I帧数据包大小的概率密度函数曲线和2种场景下P帧数据包大小的概率密度函数曲线分别如图11和图12所示。
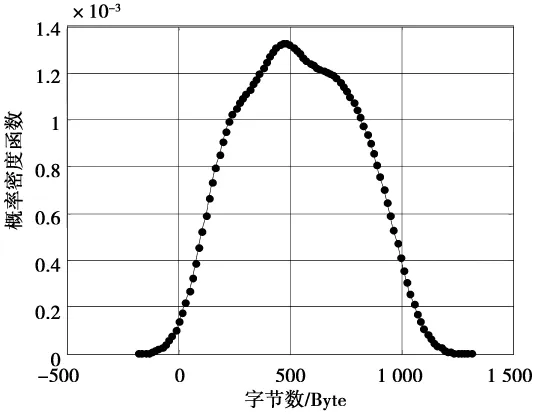
图10 I帧数据包大小的概率密度函数Fig.10 PDF of I frame data package
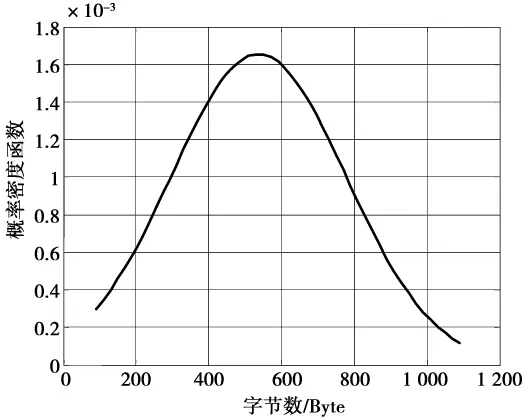
图11 I帧数据包大小的概率密度函数拟合曲线Fig.11 Fitting curve of PDF of I frame data package

表1 分组域可视电话业务模型参数及取值Tab.1 Parameters and their values for traffic source model of packet-switched videophone

表2 2种场景下的P帧数据包大小参数取值Tab.2 P frame data package parameters under two scenes

图12 2种场景下P帧数据包大小的概率密度函数拟合曲线Fig.12 Fitting curve of PDF of P frame data package under two scenes
3 结束语
本文通过分析EVDO分组域可视电话业务的实现,并根据分组交换业务的性质,建立了分组域可视电话业务的源模型。通过对用户行为特性的描述,提出了会话层的模型参数;通过对音视频源的压缩协议和数据传输协议的分析,提出了数据包层的模型参数;并通过对获取数据包的统计和分析,拟合出了各参数取值范围和分布。此模型对网络仿真和3G网络建设具有一定的参考价值。
[1]严斌峰,张智江,张范.基于cdma2000 1x EV-DO的可视电话系统的实现难点[J].电信技术,2006,16(9):102-105.YAN Binfeng,ZHANG Zhijiang,ZHANG Fan.Implement difficulties of videophone system in cdma2000 1x EV-DO[J].Telecommunications Technology.2006,16(9):102-105.
[2]李强,孙瑞杰.一种基于TD-SCDMA电路域会话类业务呼叫到达模型[J].重庆邮电大学学报:自然科学版,2012,24(2):164-168.LI Qiang,SUN Ruijie.A call arrival model of circuitswitched conversational services based on TD-SCDMA[J].Journal of Chongqing University of Posts and Telecommunications:Natural Science Edition,2012,24(2):164-168.
[3]李强,于游.TD-SCDMA集群系统语音业务模型分析[J].通信技术,2010,11(43):69-71.LI Qiang,YU You.Analysis on voice traffic model of TDSCDMA trunking system[J].Communications Technology,2010,11(43):69-71.
[4]KRISHNAN V,RAJENDRAN V,KANDHADAI A,et al.EVRC-Wideband:The New 3GPP2 Wideband Vocoder Standard[C]//IEEE International Conference on Acoustics,Speech and Signal Processing,Honolulu,Hawaii,USA:IEEE Press,2007:333-336.
[5]毕厚杰.新一代视频压缩编码标准-H.264/AVC[M].北京:人民邮电出版社,2005:87.BI Houjie.New Generation Video Frequency Compress Coding Standard-H.264/AVC[M].Beijing:The people post and Telecommunications Press,2005:87.
[6]THOMAS S,MISKA M,THOMAS W.H.264/AVC in Wireless Environments[J].IEEE Transactions on Circuits and Systems for Video Technology,2003,7(13):657-673.
[7]张锦春,胡谷雨.宽带多媒体业务的业务量模型[J].电视技术,2002.36(11):16-19.ZHANG Jinchun,HU Guyu.Traffic model of broadband multimedia service [J].Video Engineering,2002,36(11):16-19.
[8]LIU S G,WANG P J,QU L J.Modeling and simulation of self-similar data traffic[C]//Proceeding of 2005 International Conference on Machine Learning and Cybernetics,Guangzhou,Guangdong:IEEE Press,2005:3921-3925.
猜你喜欢
广西民族大学学报(自然科学版)(2022年1期)2022-05-18
计算机与数字工程(2022年3期)2022-04-07
电脑与电信(2021年9期)2021-12-21
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
网络安全和信息化(2018年4期)2018-11-09
当代旅游(2018年8期)2018-02-19
数学学习与研究(2018年2期)2018-02-09
电子制作(2017年9期)2017-04-17
人间(2015年8期)2016-01-09
