
一种密度预测与服务分级的MAC退避算法*
2013-12-07 06:18:46苏海武程良伦苏新凌孙志敬
电子技术应用 2013年10期
苏海武,程良伦,高 锐,苏新凌,孙志敬
(广东工业大学 自动化学院,广东 广州 510006)
中高速无线传感器网络[1]用于包括环境检测、视频多媒体等多种混合类型业务,网络负载通常很大,区域节点密度差异大,区域负载波动大。传统无线传感器网络的MAC协议竞争窗口滑动缓慢,对于负载波动大的业务会造成过渡时间长以及资源浪费等,不能满足数据复杂的中高速无线传感器网络[2]。目前出现了针对无线传感器网络MAC协议的多种有效的退避算法,典型退避算法有:(1)二进制指数退避算法BEB(Binary Exponential Backoff)[3],其特点是发生冲突时竞争窗口按二进制指数增长,发送成功时则降至最小值。其缺点是总是有利于最近发送成功的节点而公平性差,且随着节点数增加而碰撞概率急剧增大,造成网络性能迅速下降。(2)倍数增加线性递减退避算法MILD(Multiplicative Increase Linear Decrease)[4],当网络节点数较多时,MILD由于竞争窗口变化较平滑,其吞吐率性能略优于BEB。但当网络有中等数目的节点时,则由于竞争窗口线性递减而显得缩小相对较慢,使节点竞争窗口值往往大于合理值。(3)CIMLD(Conic Increase Multiplicative Linear Decrease)算法[5]采用分段二次曲线计算倍乘退避因子来调节退避窗口,能够在不同区域中以不同速率解决信道冲突,但流封锁信道问题还没有完全解决。(4)PTTL(Preferentially Transmitting and Different Traffic Levels)退避算法[6]根据网络流量判定的级别来改变退避窗口大小,赋予转发节点一定的信道接入优势来提高前传效率而减少时延,但对网络流量变化适应性较弱。
这些退避算法各具优势,但在负载波动变化急剧、数据复杂的中高速无线传感器网络环境中,网络性能则大幅下降。因此,本文在深入研究PTTL退避算法的基础上,提出一种密度预测与服务分级的MAC退避算法DPSC(Density Prediction and Service Classification),以达到提高网络信道利用率与网络吞吐量的目的。
1 PTTL退避算法介绍与分析
PTTL退避算法主要思想是:流量分级与转发优先。即节点通过侦听信道状态来判断当前网络流量级别,并对转发节点赋予较小竞争窗口而增大其信道接入概率。PTTL退避算法描述如下:
(1)空 闲 状 态 ,CW=max(CWmin,CW-i3),其 中 i是 连续侦听到空闲时隙数,CWmin是窗口最小值。
(2)发送成 功,CW=max(CWmin,CW-s2),其 中 s 是 连续成功竞争信道并发送报文成功次数。
(3)发送失败,竞争窗口CW为:

其中C是连续竞争信道失败次数,Cmax是最大退避次数,CWmax是窗口最大值。
(4)节点是转发节点,则 CW=CWmin。
总的来说,PTTL退避算法简便易行,在网络负载较重的网络环境中性能良好。但PTTL退避算法并没有服务分级,即不同业务类型数据以相同的机会接入信道,造成关键数据延迟,不能反映实际需求。且节点是转发节点,则CW将无条件降低到CWmin,虽然这样能够在一定程度上提高转发能力并保证数据转发优先,但是当网络负载严重时,不区分服务类型的无条件降至最小值CWmin,会造成碰撞概率急剧增加,反而与尽快将数据发送出去的初衷相反。因此关键类型数据应该具有接入信道优先权,提高优先级数据的传输率,减少关键类型数据时延来满足应用实时性需求。
2 DPSC退避算法设计
为了提高网络负载重且负载波动急剧的中高速无线传感器网络性能,基于PTTL退避算法提出密度预测与服务分级MAC退避算法DPSC。主要创新点如下:
(1)网络节点数目进行加权递推平滑预测。节点密度与邻近节点数目是一一映射关系,即某节点的邻近节点越多,此节点区域的节点密度越大。假设网络自适应占空比p∈[0,1],即节点每周期处于活动状态概率为p。在每个估算周期i∈[1,n],利用竞争窗口来实现计算邻近节点,且计算节点数是指除开周期1~i-1中已计算的所有醒来邻近节点。在估算周期i中,询问节点发送询问包REQ。接收到询问包REQ且未有回答的醒来节点时,在M个时隙中随机选择一个时隙回复一个装载唯一身份ID的回复包ANS。询问节点在第i窗口成功收集分组Gi数目并记录ID。由伯利努试验二项分布可知占空比为p、实际邻近节点数目为N且发生k次的概率为:

现定义 L(N,G1,…,Gn,p)为在周期 1,2…,n中邻近节点数为G1,k2,…,Gn的概率,由二项分布公式[7]可知,
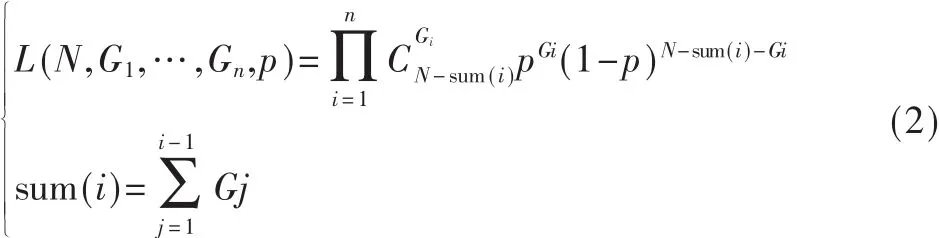
则实际邻近节点数目N的最大似然估算值N*为:

由于是高阶运算而直接计算式(2)得出最大值十分困难。事实上,L(N,G1,…,Gn,p)一定存在一个整数最大值N^≈N*,当 N′不等于 N^时,
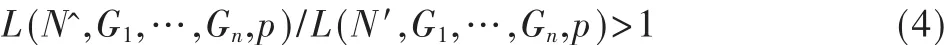
当式(4)接近1时,最大似然估算值N*必定在区间[N′,N^]即区间[N-1,N]中,则
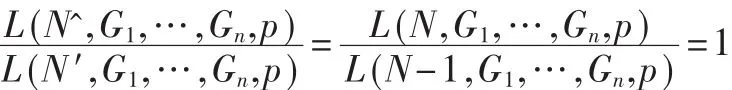
即

则由式(5)可得最大似然估算值N*为:
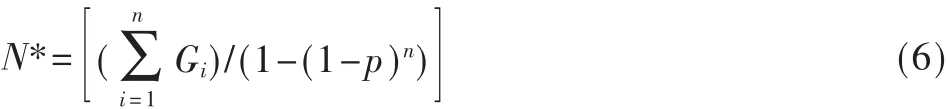
定义Nc为当前邻近节点数目,Nj为第j个最大似然估算值,则对节点数目最大似然估算值进行加权递推平滑估算可得当前邻近节点数目Nc为:
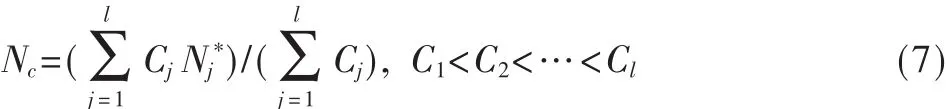
其中l是平滑因子,l值越大则估算值越平滑,适应节点密度变化能力越差,这里取中间值 l=5;Cj是权重值,Cj越大表示相对应的 Nj*权重越大。C1<C2<…<Cl说明最近估计的最大似然值权重最大,所起作用最大。
(2)引入服务分级因子δ∈[0,1]。基于服务分级思想,优先级别越高的类型数据对应的δ越大,反之亦然。为了能进行服务质量区分,应对复杂数据进行数据分类。数据分类原理是,把所有数据分成m优先等级,并且每个节点中有m个数据类型缓冲数据队列,缓冲数据队列容量总数分别为 Q1、Q2、Q3…Qm, 当前数据队列数分别为q1、q2、q3…qm。 可得节点的服务因子 δ为:
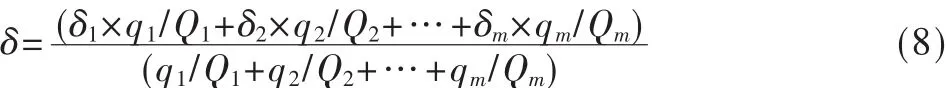
即 δ=(K1×δ1+K2×δ2+…+Km×δm)/(K1+K2+…+Km), 其中 Ki是i类型数据的缓冲数据队列比率,且Ki=qi/Qi。
(3)引入负载分级因子κ∈[0,1]。负载分级因子κ越大,则表明网络负载越重,应该尽快把数据发送出去,减轻节点数据积压。负载分级因子κ为:
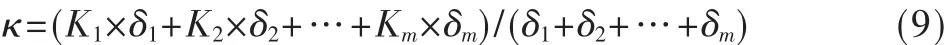
(4)引入多跳传发优先因子μ。数据传输中经过跳数越大,相应数据时延也越大。关键数据往往经过多跳传输后实时性得不到满足。因此同等级数据的跳数越多则越应该优先转发,减小发送时延。具体实现是数据捎带多跳总跳数Jn与当前跳数Ji,则多跳传发优先因子为:

根据以上思路,提出了一种密度预测与服务分级的MAC退避算法:DPSC。具体实现步骤如下。
(1)DPSC退避算法先对每个节点i竞争窗口设定最小值 CWmin×log(Nci)和最大值 CWmax×log(Nci),初始退避窗口设置为CWmin。同时为区分当前网络负载情况,设置一个退避窗口分隔阈值CWm×log(Nci)。其中CWm×log(Nci)把竞争窗口区间分隔成如图1所示。

图1 DPSC竞争窗口
(2)空闲状态,即当检测到连续的信道空闲时隙数大于 2×CWmin×log(Nci)时,根据式(6)、式(7)更新节点 i的当前网络邻居节点数Nci,CW更新为:
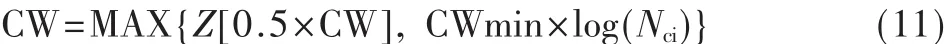
其中Z代表取整。MAX表示取最大值。
(3)发送成功时,

(4)发送失败未超过最大退避次数阈值Fth时,
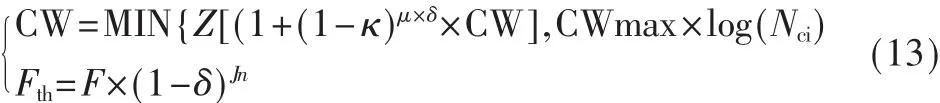
其中Fcourt是连续竞争信道失败次数,F表示规定失败次数,Jn是数据传输多跳总次数。
(5)发送失败超过规定次数阈值Fth时,
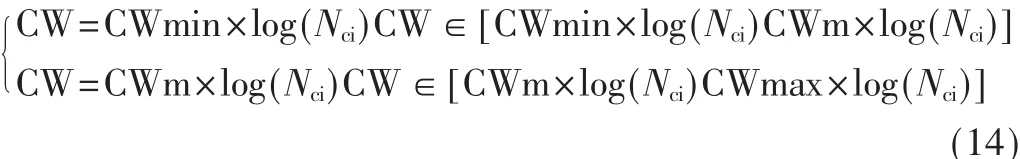
(6)负载分级因子κ超过包队列容忍阀值κth时,

其中,容忍阈值 κth=(1-δ)×κ′,κ′表示规定的数据包队列数容忍值。
(7)接收到RTS包时,进行服务分级优先转发,

3 仿真与实验分析
本文采用NS2仿真平台,为了评估新退避算法在实际应用场景的性能,采用节点随机分布的网络拓扑。节点数目随机分布在80 m×80 m的范围内,各节点都处于相互通信范围内,节点的通信距离为120 m。
3.1 节点密度预测分析
邻近节点数目的最大似然估算值N*与节点占空比p有关,占空比p的大小决定N*的估算精确度。当前网络邻居节点数Nc与平滑因子 l、权重系数 Cj相关,此处取 l=5,C1=0.2,C2=0.4,C3=0.6,C4=0.8,C=1.0。 其中相对误差e=|Nc-N|/N,Nc是当前邻近节点数目加权递推平滑预测值,N是当前邻近节点数目真实值。
从图2可知,邻近节点数目越多,占空比 p越大,则当前邻近节点数目加权递推平滑预测值与真实值相对误差e越小,即平滑预测值越接近真实值,估算精确度越高。同理,对于节点密度大的区域节点可以设置较低的占空比p进行估算而得到可靠的邻近节点数目估算值,且减少估算周期侦听所消耗的能量。
3.2 系统时延分析
从图3可知,节点数目较少时各算法端到端时延基本相同,但节点数目较多时的时延相差甚远。DPSC算法时延增加速率最小,因为能够根据邻近节目数目动态地修改竞争窗口,减少碰撞概率与重发次数,从而减少端到端时延,能够适应不同节点数目的网络环境。
3.3 系统吞吐量分析
从图4可知,随着节点密度增大吞吐量都有所下降,在节点数目小于10时吞吐量大致相同,之后出现大幅度差距。因为随着节点数目的增加,节点冲突概率将会增大,所以各种算法吞吐量都有所下降。其中DPSC算法下降速度最慢是由于邻近节点数目能自适应竞争窗口,从而有效地提高信道利用率,相对PTTL算法平均提高15%。其余三种算法都不太适应于高节点密度的网络环境,特别是BEB算法吞吐量下降最快。
3.4 系统能耗分析
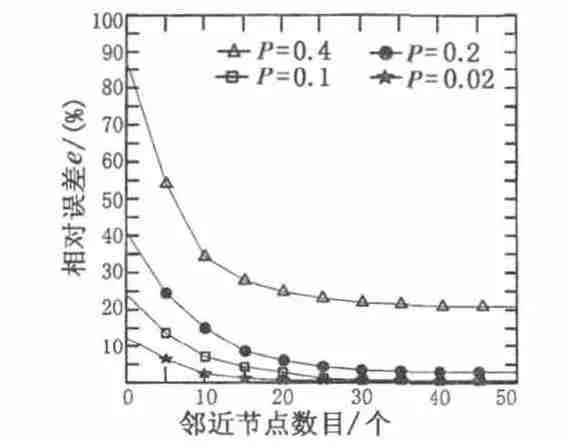
图2 邻近节点数目估算误差与占空比关系
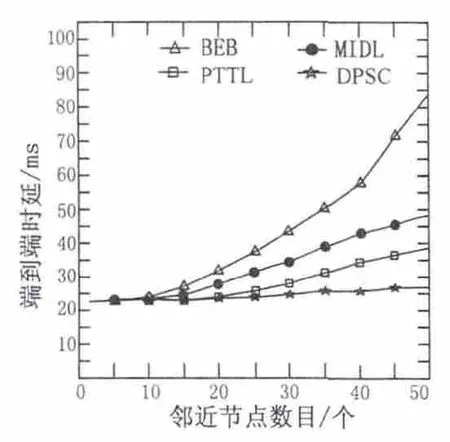
图3 δ=0.6时延与节点数目关系
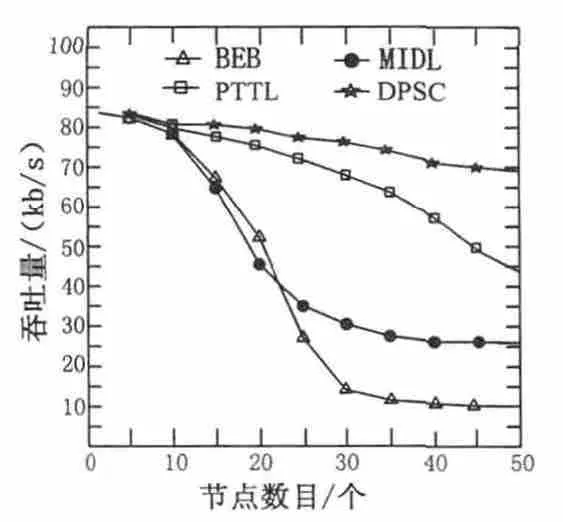
图4 δ=0.6时吞吐量与节点数目关系

图5 平均能耗与节点数目关系
从图5可知,各退避算法成功发送每比特数据的平均能耗随着系统网络节点数目的增加而增加。在邻近节点少的网络系统中,其他三种算法能耗低于DPSC算法,因为密度低而竞争信道的冲突少,数据发送成功率高,而DPSC算法却因节点估算预测的周期侦听耗能略高。但高密度时DPSC算法因为根据节点数目动态地改变竞争窗口而降低冲突概率,减少重传次数,所以平均能耗明显低于其他三种算法,相对于PTTL算法平均下降5%。
本文退避算法DPSC通过二项分布概率模式对邻近节点数目进行最大似然估算并进行加权递推平滑预测,精准地估算出邻近节点数目,实现竞争窗口自适应节点密度的目的;根据服务分级思想,引入服务分级因子δ实现服务级别高的数据能优先发送;引入负载分级因子κ表示负载级别并赋予数据积压的节点优先发送权;引入多跳传发优先因子μ实现数据前传的连续性与减少时延,满足关键数据多跳传输实时性要求。DPSC退避算法与其他三种算法在节点低密度与低负载情况下网络性能差别不大,但在节点高密度与高负载情况下则表现出优越的网络性能。进一步的工作将采用无线传感器硬件平台CC2430对DPSC退避算法进行实际性能测试。
[1]王越超,程良伦.中高速传感器网络中基于服务区分的QoS路由算法研究[J].计算机应用与软件,2010(8):152-158.
[2]CHIA W C,CHEW L W,ANG L M,et al.Low memory image stitching and compression for WMSN using stripbased processing[J].International journal of sensor network,2012,11(1):22-32.
[3]PANTAZI A,ANTONAKOPOULOS T.Equilibrium point analysis of the binary exponential backoff algorithm[J].Computer Communications,2001,24(18):1759-1768.
[4]Zhang Yi,PIUNOVSKIY A,AYESTA U,et al.Convergence of trajectories and optimal buffer sizing for MIMD congestion control[J].Computer Communications,2010,33(2):149-159.
[5]奎晓燕,杜华坤.CIMLD:多跳 Ad Hoc网络中一种自适应的MAC退避算法[J].小型微型计算机系统,2009,30(4):679-682.
[6]余庆春,谭狮.一种基于转发优先及流量分级的无线传感器网络退避算法[J].计算机应用研究,2012,29(5):1846-1849.
[7]CAMILLO A,NATI M,PETRIOLI C,et al.IRIS:Integrated data gathering and interest dissemination system for wireless sensor networks[J].Ad Hoc Networks,2011,11(2):654-671.?
猜你喜欢
中学化学(2024年4期)2024-04-29 22:54:35
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年6期)2018-11-25 09:50:10
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
中国民族医药杂志(2016年5期)2016-05-09 07:43:50
电测与仪表(2016年17期)2016-04-11 12:38:28
作文大王·低年级(2016年3期)2016-03-11 00:48:53
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:42
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:44
电子设计工程(2015年8期)2015-02-27 12:05:33
