
语义We b服务搜索研究概述*
2013-11-10 07:09郭富禄曾志浩武岫缘
网络安全与数据管理 2013年21期
郭富禄,曾志浩,武岫缘
(湖南工业大学 计算机与通信学院,湖南 株洲 412008)
1 语义Web服务搜索
语义Web服务[1]源自2001年Berners Lee提出语义Web[2]的概念,并继承了大量有关Web服务的研究成果,是语义Web技术和Web服务[3]技术相结合的产物。相关研究主题包括:服务发布/注册、服务搜索、服务组合、服务调用/执行、服务管理/监控等。在上述研究主题中,语义Web服务搜索处于整个语义Web服务生命周期中的关键位置。服务的组合和调用都必须以找到满足用户需求的服务资源为前提条件,而服务的搜索又与语义Web服务资源的发布和注册机制密切相关,这使得服务资源的搜索功能在整个语义Web服务生命周期中起着承上启下的重要作用。
语义Web服务搜索利用语义Web服务的描述模型和描述语言给予Web服务的语义信息进行搜索操作[4],以获得满足用户需求的Web服务资源。这种方式能够提高服务搜索的精度,改善用户体验,并为语义Web服务的组合、执行提供更为可靠地支持。
2 语义Web服务搜索相关研究主题
目前语义Web服务搜索相关研究的侧重点都集中在如何利用语义信息进行服务的匹配,即在大量已有语义服务资源的基础之上,快速、准确地搜索和发现满足用户需求的服务。对于语义Web服务搜索的研究工作,通常从以下3个方面进行,即服务资源的收集/索引、搜索条件表达/处理和服务资源的匹配/排序[5]。语义 Web服务的相关研究内容和语义Web服务搜索的研究主题可用下图1说明。
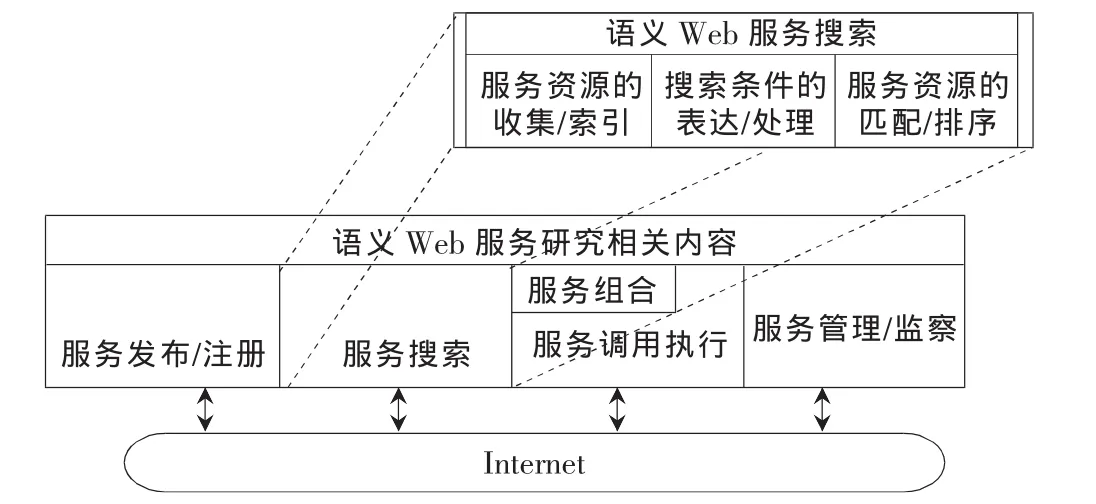
图1 语义Web服务相关研究主题
语义服务资源的收集和索引研究涉及语义Web服务的发布和注册机制,服务资源的收集,以及对于收集的服务资源进行索引和索引资源后续管理方面的问题。语义搜索条件的表达则主要研究提供一种方法,使用户利用语义信息,清晰、明确地表达其对所需服务资源的需求。语义Web服务资源的匹配/排序研究用户对Web服务资源的需求的语义描述与Web服务资源的语义信息的契合程度,并根据契合程度对服务资源进行排序,以便择优选择。
3 Web服务资源收集/索引
3.1 传统的注册和发布机制
UDDI主要提供基于Web服务的注册和发现机制,为Web服务提供3个重要的技术支持:标准的描述Web服务的机制;调用的Web服务的机制;可以访问的Web服务注册中心。UDDI规范由OASIS标准化组织制定。其缺点是仅支持语法层的操作,在服务的注册阶段无法准确的描述服务的功能,而在服务的搜索阶段也是仅提供基于关键字的匹配策略,因而无法提供精确的搜索结果。另一方面UDDI集中式Web服务发现结构也存在缺乏可扩展问题。
3.2 分布式注册中心
为了解决注册中心因为缺乏有效分布式策略而导致的系统存在可扩展问题,Perryea等[6]提出通过注册中心组成社区(community),利用服务间的依赖关系生成食物链来帮助发现Web服务,这种方式虽然提高了发现效率,却导致大量的额外存储,降低了可扩展性。Verma等[7]通过联盟(federation)来组织注册中心,即一个注册中心可以属于多个联盟。这种方式会导致在极端的情况下,如一个注册中心属于所有的联盟,该策略就不能很好地将注册中心分类,无法高效地完成服务注册和发现任务。参考文献[8]通过P2P覆盖网将注册中心组织起来以提供好的可扩展性,然而采用非结构化P2P方式,很难解决系统内请求消息转发次数太多导致的占用带宽过多等问题。参考文献[9]则通过crawler主动地访问各个注册中心来提取服务信息。
4 语义Web服务搜索条件表达
4.1 假想完整服务搜索条件描述模型
以假想的完整服务描述模型来表示服务搜索条件。在参考文献 [10]中给出了以完整服务描述模型来表示报务搜索条件的一般范式。以这种方式进行的研究工作主要分为两类:(1)基于 OWL-S服务描述模型的,代表性工作有[11];(2)基于 WSMO服务描述模型的,代表性工作包括[12]。从地域上看,基于OWL-S模型进行研究工作的研究机构和人员主要分布在美国和亚洲地区,而基于WSMO模型的研究工作则集中在欧洲和大洋洲地区。此外,对于WSDL规范进行语义描述的扩展,以使其能够描述语义Web服务的研究工作相对时间较早,现已基本偃旗息鼓。
4.2 简化的服务描述模型元素
以简化后的服务描述模型元素来表示服务搜索条件。服务描述模型元素包括服务描述中的功能语义,服务的前置条件(Precondition,P),服务接口的效果(Effect,E)[13],服务的各种操作(operation),更进一步的还有服务的输入(Input,I)和服务的输出(Output,O)[14]。
4.3 自定义服务搜索条件格式
自定义服务搜索条件格式。以该种方式进行语义Web服务资源的搜索和发现的研究工作比较多,其实该类研究工作是在简化后的服务描述模型基础上对相关的元素进行了规范化。具体的方法有:以服务模版(Service Template)的概念表示服务的搜索请求条件;以能力描述(Capability Description)来表述语义服务的搜索请求条件;提出过程查询语言PQL(Process Query Language),基于其提出的过程本体(process ontology)表述服务搜索条件。而更多的研究工作则基于上述简化后的服务描述模型元素,将其抽取出来后进行规范化表述,以N元组的方式来表述服务搜索条件。如参考文献[15]中用服务请求三元组 req={reqName,InReqSet,OutReqSet}。此外,语义上下文(Semantic Context)也可以包含在服务搜索条件中。
4.4 特定语言或语法结构
利用现有的特定语言或语法结构来表示服务搜索条件。在OWL-S 2004版本规范中,已经考虑了关于服务条件的表述,其中就包括 SWRL(Semantic Web Rule Language)和 KIF(Knowledge Interchange Format)。 SWRL(Semantic Web Rule Language)是W3C的标准之一,作为OWLS-Lite和Rule ML的综合,它可以表示面向OWL-S服务资源的规则,并能将其用于语义Web服务资源的搜索中。但很明显,上述两种描述语言只能适用于用OWL-S规范描述的服务搜索,且KIF是面向机器的、在不同程序间交换知识的语言,不适用于半自动化的、由用户自己提交服务搜索条件的情况。这种方式直接用于语义Web服务搜索时,对用户的要求过高[16]。
5 语义Web服务匹配/排序
5.1 基于逻辑推理的语义Web服务匹配方法
基于逻辑推理的Web服务匹配方法是Web服务搜索的主要方法之一,即通过本体概念之间包含的逻辑关系来实现基于语义的服务匹配。当前基于逻辑推理的匹配方法主要是根据其语义关系,特别是在本体分类层次中的关系来确定。服务的接口的描述主要有输入(Input,I)参数的语义标注、输出(Output,O)参数的语义标注、接口的前置条件 (Precondition,P)、接口的效果(Effect,E)组成。根据匹配的内容不同可以分为基于输入输出(IO)的匹配和基于输入输出和前置后置条件的匹配(IOPE)的匹配。基于IO语义匹配的匹配器有OWLSM,OWLS-UDDI,他们通过发布服务的IO与请求服务IO之间的语义包含关系来确定服务的匹配程度。基于IOPE的服务匹配除了考虑IO外,还考虑前置条件P和后置条件E,目前提出的有,采用两阶段的方法来度量用户目标的满足程度,第一阶段度量WSMO目标模板与WSMO中Web服务匹配程度,若满足,再在此基础上度量目标实例与Web服务的相似度[17]。
5.2 基于语义相似度的语义Web服务匹配算法
基于语义相似度计算的匹配方法,以本体概念之间的相似性为基础,通过计算服务描述之间的相似性来确定服务的匹配程度。当前研究工作有,通过计算本体概念之间相同和不同的属性来得到相似度值,其代表是Amos Tversky的基于属性相似度的算法[18];通过测量本体间概念连接边长度,用概念间的几何距离来衡量语义相关度的基于语义相似度的计算算法[19];还有一种基于信息容量的相似度算法,其核心是根据两个本体概念所拥有的共同部分来决定他们之间的相似度。
从上述对语义Web服务搜索的研究工作的总结和分析中可得出以下结论。首先,语义Web服务搜索是语义Web服务研究工作中一个基础性问题。现有的研究工作主要集中在Web服务的匹配上,基于逻辑推理的匹配方法和基于语义相似度的匹配方法以及它们的组合的方法都为Web服务的匹配提供的丰富的选择。随着服务效果、服务的情景等信息的引入,有效地提高了语义Web服务匹配的质量。其次,目前尚没有一种完备的、规范的服务搜索条件表达方式,进而使得当前的服务的匹配算法大多都是在自我假定环境中实现的,不具有通用性。最后,Web服务的注册和索引没有一种统一的规范,UDDI注册中心的集中式Web服务发现结构存在可扩展性不足的问题。
[1]MCILRAITH S A, SON T C, ZENGH.Semanticweb services[J].Intelligent Systems, IEEE, 2001,16(2):46-53.
[2]BERNERS-LEE T, HENDLER J, LASSILA O.The semantic web[J].Scientific american,2001,284(5):28-37.
[3]岳昆,王晓玲,周傲英.Web服务核心支撑技术:研究综述[J].软件学报,2004,15(3):428-442.
[4]孟祥福,张霄雁,马宗民,等.基于语义相似度的 Web数据库不精确查询方法[J].计算机科学,2012,39(4):154-158.
[5]曾志浩.用于语义Web服务搜索的语义条件表达式的研究[D].武汉:武汉大学,2010.
[6]PERRYEA C A,CHUNG S.Community-based service discovery[C].Web Services, 2006.ICWS′06.International Conference on.IEEE,2006.
[7]SIVASHANMUGAM K, VERMA K, SHETH A.Discovery of web services in a federated registry environment[C].Web Services,2004.Proceedings.IEEE International Conference on.IEEE,2004.
[8]刘志忠,王怀民,周斌.一种双层P2P结构的语义服务发现模型[J].软件学报,2007,18(8):1922-1932.
[9]AL-MASRI E,MAHMOUD Q H.WSCE:A crawler engine for large-scale discovery of web services[C].Web Services,2007.ICWS 2007.IEEE InternationalConference on.IEEE,2007.
[10]GRIMM S, MOTIK B, PREIST C.Matching semantic service descriptions with local closed-world reasoning[M].The Semantic Web:Research and Applications.Springer Berlin Heidelberg,2006.
[11]PAOLUCCI M, KAWAMURA T, PAYNE T R, et al.Semantic matching of web services capabilities[M].The Semantic Web—ISWC 2002.Springer Berlin Heidelberg,2002.
[12]STOLLBERG M,HEPP M,HOFFMANN J.A caching mechanism for semantic web service discovery[M].The Semantic Web.Springer Berlin Heidelberg,2007.
[13]BENER A B, OZADALIV, ILHAN E S.Semantic matchmaker with precondition and effect matching using SWRL[J].Expert Systems with Applications, 2009,36(5):9371-9377.
[14]张佩云,黄波,孙亚民.一种基于语义与QoS感知的Web服务匹配机制[J].计算机研究与发展,2010(5):780-787.
[15]邹国兵,向阳,甘杨兰,等.利用语义匹配度计算的Web服务发现方法 [J].小型微型计算机系统,2010(5):807-812.
[16]王海,高岭,范琳,等.基于 SPARQL-DL的语义 Web服务查询[J].电子学报,2011,39(A03):52-56.
[17]STOLLBERG M,KELLER U,LAUSEN H,et al.Twophase web service discovery based on rich functional descriptions[M].The Semantic Web:Research and Applications.Springer Berlin Heidelberg,2007.
[18]TVERSKY A.Features of similarity[J].Psychological review,1977, 84(4): 327-352.
[19]CRAMER I, WANDMACHER T, WALTINGER U.Exploring resources for lexical chaining:A comparison of automated semantic relatedness measures and human judgments[M].Modeling, Learning, and Processing of Text Technological Data Structures.Springer Berlin Heidelberg,2012.
猜你喜欢
吉林广播电视大学学报(2021年4期)2022-01-14
数学小灵通(1-2年级)(2021年10期)2021-11-05
数学小灵通(1-2年级)(2020年12期)2021-01-14
作文成功之路·小学版(2020年5期)2020-06-11
开放教育研究(2020年2期)2020-03-31
小天使·一年级语数英综合(2018年11期)2018-11-23
资源再生(2017年3期)2017-06-01
小学阅读指南·低年级版(2016年10期)2016-09-10
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
