
基于本体片段模糊相似度的异构本体合并
2013-11-09 08:06钱鹏飞
上海电机学院学报 2013年6期
钱鹏飞
(上海宝信软件股份有限公司, 上海 201203)
基于本体片段模糊相似度的异构本体合并
钱鹏飞
(上海宝信软件股份有限公司, 上海 201203)
提出一种基于本体片段模糊相似度的异构本体合并方法研究。复杂的异构本体模型可被分割成多个本体片段,且这些片段均具有独立语义,使本体合并转换成本体片段之间的合并;提出基于概念或关系的两种本体片段模糊化相似度计算方法,并进一步讨论一种基于本体片段模糊相似度的异构本体合并的算法。该算法解决相似度计算过程中出现的模糊特性过早裁决的问题,从而文本信息可与结构信息共同分析以提高本体片段间的合并效果。最后通过应用实例和相关复杂性分析比较,全面评估该基于本体片段模糊相似度的异构本体合并的算法。
本体合并; 本体片段; 模糊相似度; 本体概念
在各种本体映射及本体合并方法中[1-5],往往通过本体概念或本体关系间的语义相似度来进行本体模型的匹配;而具有若干个概念和关系组成的本体片段一般比单个本体概念包含了更复杂的语义特征信息。能否通过本体片段间的语义特征匹配来完成本体间的匹配和合并,本文提出了基于本体片段的异构本体合并研究。按照文献[6]中所涉及的本体定义元模型(Ontology Definition Meta-Model, ODM)及对应的对象约束语言(Object Constraint Language, OCL)的扩展将异构本体模型分割成多个本体片段,即片段内本体元素高度相关,从而本体之间的合并就转换成本体片段间的合并;然后,通过本体片段间的相似度计算,在目标本体模型的多个已分割片段中,定位与待合并本体片段最匹配的片段,而后进行2个本体片段间细节层面的合并,以完成本体合并。考虑到本体片段语义紧密程度较高,本体片段间的细节层面合并就相对容易,如何通过本体片段间相似度的计算以完成相似本体片段间的定位,成为本文讨论的重点。
本体片段包含多个本体概念和关系,具有更复杂的语义特征信息,因此可基于不同本体片段特征分别计算相似度,然后按照一定的权重将这些相似度复合。本文采用模糊化的相似度计算方法[7]解决了本体概念相似度计算过程中存在的特征信息系统偏好、过早裁决模糊特征等现象。与本体概念间的匹配相类似,本体片段间相似度的计算和表示仍采用模糊化相似度的表示方法,可针对本体片段的不同语义特征信息进行多种类型的模糊相似度计算和表示。
本文研究成果已应用于上海宝信软件股份有限公司职能产品人力资源模块的整体框架设计中。通过组织机构本体片段的半自动化合并,较好地支撑了大型集团型企业中频繁出现的组织机构的划转、合并、映射及匹配等问题。
1 本体片段模糊相似度计算
本体片段中的特征信息主要包括: ① 本体实例及本体概念;② 本体模型内概念间关系,如概念间继承、概念间包含属性、概念间参数依赖等。基于这两种本体片段特征信息,提出了基于概念的本体片段模糊相似度计算、基于关系的本体片段模糊相似度计算,并在此基础上研究了一种基于本体片段模糊相似度的异构本体合并的算法。
1.1面向本体概念及实例的片段模糊相似度计算
面向本体片段的语义概念及实例特征信息,本文提出了基于复合概念的片段模糊相似度算法。复合概念即将本体片段看作虚拟的单个本体概念,所涉及实例均为该复合概念的实例,从而通过本体片段间复合概念的模糊相似度计算,即得到面向复合概念的本体片段间模糊相似度。在复合概念构造过程中,并非本体片段中所有实例和概念均具有相等地位,其原因是概念上、下文语义关系、概念实例的数量及重要性都相差较大,需要从待选的概念和实例中,选取具有较强上、下文语义代表性的实例及概念,构造复合概念。本文结合片段,OM1=(c1,c2,…,cm)(i=1,2,…,m),其中,ci为任一概念,m为概念个数,完成了复合概念的构建。
步骤1以与对应本体片段语义关联程度为依据,确定本体片段中参与复合概念构造各本体概念的权重。若某个概念与该本体片段语义相关度非常高,则给予“十分重要”评级;若某个概念属很不重要概念,则给予“十分不重要”评级。因此,对于片段OM1获得模糊评级权重W1=(w1,w2,…,wm)(i=1,2,…,m),w∈(十分不重要,较不重要,普通,较重要,十分重要),对应的三角模糊权重TW1=(tw1,tw2…,twm)(i=1,2,…,m),tw=(l,k,r)为三角模糊数,其中,l、k、r分别为三角模糊数tw的左边界、中值与右边界,且0≤l≤k≤r≤1。
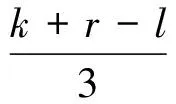
步骤3若要从待计算片段中选取N个分别隶属于概念(c1,c2,…,cm)的实例,且同一概念中多个实例的选取采用随机的方法,从而每个概念中选择的实例数量可表示为(rw1·N,rw2·N,…,rwm·N)。针对m个概念的名称信息,有复合概念的名称向量Nv=(n1,n2,…,nm),而实例向量Instυ=(Ins1,Ins2,…,Insm),其中,第i个概念的实例向量Insi=(e1,e2,…,erwi·N),1≤i≤m,e为概念ci的实例。目前,复合概念间的相似度计算仅考虑名称和实例。基于Instv特征的模糊相似度和基于Nv特征的模糊相似度,分别可以根据实例向量、名称向量得到,均服从区间型模糊分布[8]。分别按照Nv和Instv进行区间型的模糊相似度计算,然后归一化为三角模糊相似度,再按照预先设置的权重WN和WInst进行加权复合,即可得到采用三角模糊相似度表示的基于复合概念的本体片段间模糊相似度。其过程如图1所示。

图1 复合概念本体片段模糊相似度Fig.1 Composite concept ontology slice fuzzy similarity
1.2面向本体关系的片段模糊相似度计算
假定本体形式化公式O=(C,A,T,D,X),其中,C、A、T、D、X分别表示概念、属性、分类关系、依赖关系和公理规则5个本体元素;而片段中概念间的关系类型包括:概念间继承(T)、概念间对象包含属性(OA)、概念间参数依赖(D)等。面向本体关系的片段相似度计算可依据本体片段间相类似的本体概念间关系的数量进行计算。
判断2个概念关系是否相类似的顺序如下: ① 判断2个概念关系类型是否相同;② 检查2个概念关系的对应概念是否相类似。本文结合本体片段OM1=(c11,c12,…,c1m,r11,r12,…,r1p),i∈(1,2,…,m),k∈(1,2,…,p)(设OM1拥有m个概念,p个关系)和OM2=(c21,c22,…,c2n,r21,r22,…,r2q),j∈(1,2,…,n),d∈(1,2,…,q)(设OM2拥有n个概念、q个关系),来说明本体片段间面向概念关系的模糊相似度计算步骤。
步骤1相似概念对的识别寻找,其不同于相似度计算。前者按照相关标准(如相似度非模糊化值超过某个阈值),识别出本体片段间的相似概念对;而相似度计算还需在前者基础上计算出概念对的具体相似度。相似概念对的识别过程如下(假定m≤n):
Void SearchingSimConPair(OM1,OM2, SimConPair[][2])
{SimConPair[][2];
∥本体片段OM1和OM2之间的相似概念对;
For(i=1;ilt;=m;i++)
∥片段OM1中有m个概念,i∈(1,2,…,m);
{S[n];
For(j=1;jlt;=n;j++)
∥片段OM2中有n个概念,j∈(1,2,…,n);
S[j]=Sim(c1i↔c2i);
∥次一级的概念对相似度计算,仅仅考虑实例和名称信息;
if(max(S[n])gt;Δ)
∥找到了相似概念对,即某个相似度值超过了阈值Δ;
{SimConPair[i][1]=OM1·c1i;
∥取相似度最大的概念对,为本次匹配找到的概念对;
SimConPair[i][2]=S[j]=max(S[n])|OM1·c2j);
∥c1j,c2j为S[n]中的n个相似度中取得最大值的对应概念
}else{
SimConPair[i][1]=SimConPair[i][2]=NULL; ∥当前概念无相似概念对;
} ∥End of else
} ∥循环结束
}∥SearchingSimConPair ∥算法结束
然后需要找出片段OM1、OM2间概念对相似度的数值(非模糊化值)超过阈值Δ的本体概念对。
步骤2若要判定两关系是否相似,先要获得相似概念对,然后结合关系类型综合判断。本文结合关系类型及本体片段间的相似概念对,计算两个本体片段间相似关系的个数,计算过程如下(设p≤q):
Void SearchingSimRelationPair(OM1,OM2, SimConPair[][2],SimRelPair)
{SimRelPair;
∥本体片段OM1和OM2之间的相似关系对;
For(k=1;klt;=p;k++)
∥片段OM1中有p个关系;k∈(1,2,…,p)
{For(d=1;dlt;=q;d++)
∥片段OM2中有q个关系;d∈(1,2,…,q)
{if(OM1·r1k·type=OM2·r2d·type)
∥两个关系类型相同;
if((SimConPair.IS_Find(OM1·r1k·c1,OM2·r2d·c1)==True and SimConPair.IS_Find(OM1·r1k·c2,OM2)·r2d·c2)==True) or
(SimConPair.IS_Find(OM1·r1k·c1,OM2·r2d·c2)==True and SimConPair.IS_Find(OM1·r1k·c2,OM2·r2d·c1)==True)
)
{
∥两个关系相关概念互相匹配;
SimRelPair.Push(OM1·r1k,OM2·r2d);
break;
∥确定相似的关系对;
∥本算法认为,在寻找相似关系对的过程中,每个关系只能使用一次;
}∥end of if
} }∥end of for
}∥End of SearchingSimRelationPair ()
计算中,隶属于不同本体片段的两个关系相似的判断条件包括: ① 类型相同;② 关系对应两概念也能互相相似。该计算主要是寻找出片段OM1和OM2间类似关系对,算法完成后,相似关系对保存入队列SimRelPair中。
步骤3根据本体片段OM1和OM2间类似关系对数量g,运用结构型模糊相似度表示方法来表示片段间面向本体关系的模糊相似度。如Simrelation=g=SimRelPair.count,其中g为正整数,且0≤g≤min(p,q)。采用模糊化的相似度计算方法中的相关公式,可将面向关系的本体片段间模糊相似度归一化为三角模糊数表示。
2 面向本体片段间模糊相似度的本体合并算法
面向本体片段间模糊相似度的异构本体合并[9-11],将需要合并的某个本体模型中所有片段作为目标片段,另一本体的所有片段作为并入片段(一般较复杂本体模型作为目标本体,另一本体作为并入本体),然后本体合并过程就演化为并入本片片段与目标片段间持续进行相似度求解,并进行本体片段创建、添加以及合并的过程。
本文提出一种面向本体片段间模糊相似度的异构本体合并算法,包括本体片段间在概念及关系的细节层面上合并的计算方法。
2.1本体合并计算方法
本体模型可由五元组(C、A、T、D、X)来表示,本体为这些元素组成的集合,本体片段为该集合中部分具有紧密语义的元素构成的子集,本文将其命名为本体模型中的元素集合(Ontology Element Set, OESet)。一系列具有相同特性的OESet,可构成OESetGroup, OESetGroup中的OESet 均必须满足OESetGroup所对应的集合定义规则(GroupDefinitionRule)[12]。对于本体模型内部片段的结构特征,本体定义元模型[13]可对其进行约束描述。
本文通过本体O1=(OESet11,OESet12,…,OESet1m),i∈(1,2,…,m)与O2=(OESet21,OESet22,…,OESet2n)j∈(1,2,…,n)之间的合并,介绍该本体合并算法。
假定n≥m,以较复杂本体O1中的m个本体片段作为目标片段,而本体O2中的n个片段作为并入片段,合并后生成本体O3。合并步骤如图2所示。

图2 本体合并核心算法流程图Fig.2 Core algorithmic flow of the ontology merging
步骤1构建不包括本体片段的空本体模型O3。
步骤2若O2=NULL,转步骤5;否则,继续步骤3。
步骤3从O2中任意选取某个片段OESet2j,将该片段OESet2j,与本体O1中的所有可能与之匹配的片段(OESet11,OESet12,…,OESet1n),i∈(1,2,…,m)分别进行本体片段模糊相似度的计算。若存在模糊相似度大于预定阈值Δ,说明本体O2中有片段与O1片段匹配,则定位本体片段对{OESet1k|Max(Sim(OESet1i,OESet2j)),OESet2j},j=1,2,…,n,其中OESet1k为在本体O1所有片段中,与OESet2j相似度取得最大值的本体片段,即OESet2j与本体O1中第k个本体片段取得最大相似度。包括并入片段OESet2j和目标片段OESet1k,继续步骤4;否则,将OESet2j添加到O3,返回步骤2。
步骤4根据已定位的本体片段对{OESet1k,OESet2j},计算本体片段间所有本体概念对的相似度,获得映射概念对(Con_Pair)={…,c1p∶c2p,…}。从OESet2i中删除出现在(Con_Pair)中并属于的O2的概念。再对OESet2j进行基本规则校验(主要考查本体片段中被剔除概念占比),若通过校验,证明OESet1i与OESet2j语义关联性不大,则抛弃对OESet2j的修改,回复到未修改状态,并同时在系统中标记该两个片段无法发生合并,返回步骤2;若未通过校验,则片段对{OESet1k,OESet2j}进行细节上的合并即执行本体片段合并算法,包括概念和结构关系的合并。合并后得到的新片段OESet3i添加到O3,并从O1中去掉OESet1k,O2中去掉OESet2j,返回步骤2。
步骤5将O1中余下本体片段添加到O3中,结束本体合并的过程,得到合并结果本体O3。
2.2本体片段合并计算方法
本文算法主要考虑本体片段间在概念和关系等细节层面上的合并。
2.2.1 基于概念细节的本体片段合并 仅需将并入片段中剩余概念直接合并到目标片段[14-15],其原因是已将并入片段中与目标片段中概念相类似的概念剔除。
2.2.2 基于“关系”细节的合并 本体片段中的关系可分为概念间继承关系、概念间包含属性关系、概念间参数依赖关系等。虽然概念间不同种类关系可并存,如本体片段中,2个概念间同时存在参数依赖关系,包含属性关系,但系统在冲突检测中仅考虑相同类型关系间的冲突,不同类型的关系则认为是不同种类的关系。如,若某并入片段中对应的关系类型为包含属性关系Own,而在目标本体片段中两概念间关系为继承Inherit关系,就会发生冲突。冲突产生后,可进行人工指定,也可采用某些策略自动解决该冲突。
针对并入片段的某关系对应的2个概念均能在目标片段中找到与之匹配的概念,且这2个概念不相邻,则直接加入该关系(或仅有一个能在目标片段中找到匹配概念,也直接加入该关系);若在目标片段中不能找到任何一个概念与该2个概念相似,则丢弃该关系;若在目标片段中确定找到2个相邻概念与这2个概念相类似,且2个关系类型相同,则2个关系合并为一个关系。
3 应用实例与分析
3.1本体定义元模型及组定义规则
多个本体模型将会具有某些公共特征,本体定义元模型即是对这些公共特征的统一抽象描述。本体定义元模型中的所有元素可被分为两类: 本体相关元素和定义规则相关元素。通过相应的定义规则相关元素(如组定义规则、本体设计模式等),即可对该元模型所描述的各类本体模型进行基于结构及约束关系的形式化校验和表示,从而使得异构本体模型按照语义分割成为可能。本体定义元模型的初步UML静态类如图3所示。
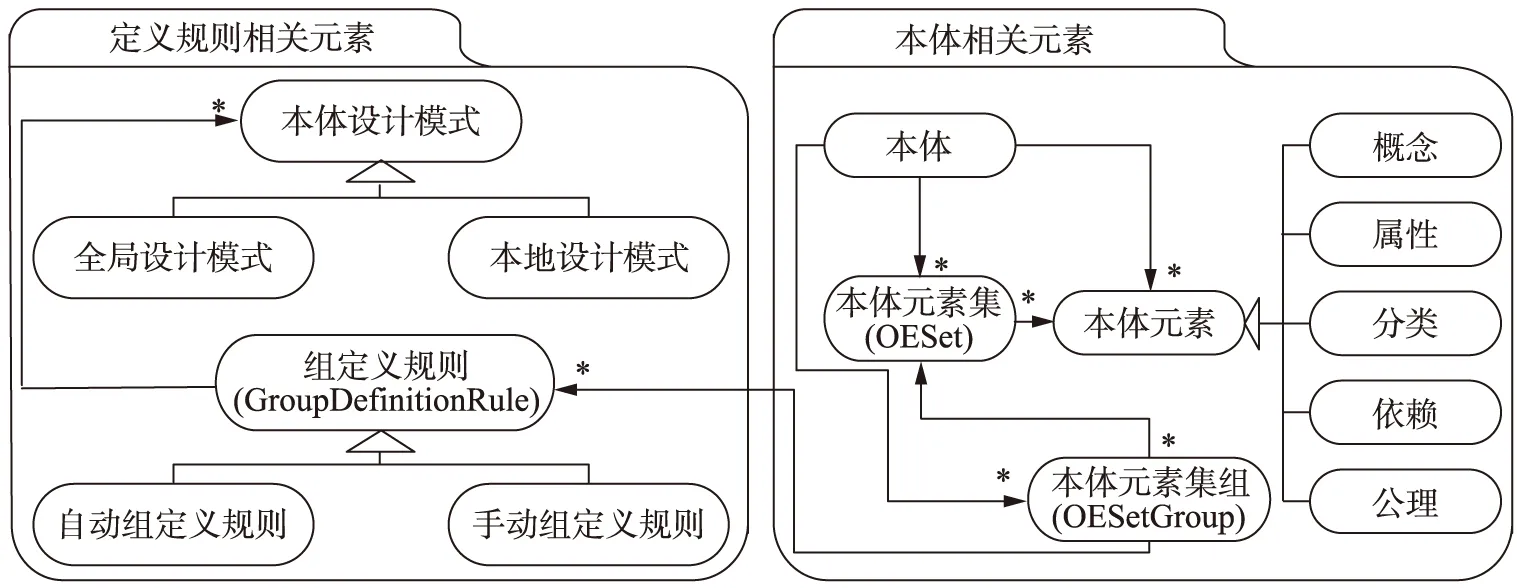
图3 本体定义元模型Fig.3 Ontology definition meta-model
图3中,组定义规则(GroupDefinitionRule)是用来定义这些公共特征的约束规则。如基于OCL的简单组定义规则定义特定的OESetGroup,该简单规则如下:
GroupDefinitionRuleA:
Context Group1OESet
inv: elements→forAll(e|e.size()=2 and e.element.type=Entity)
该组定义规则表明Group1中的每个OESet有且仅有2个元素,元素类型为Entity。
将这些规则应用到本体模型中,即可半自动化地识别出相应的本体片段(先应用组定义规则,后人工调整)。另外,在面向对象的软件开发领域中,领域模型中一些公共的经常使用的模块被定义为设计模式。同理,在本体模型中经常使用的特殊模块结构也可被定义为本体设计模式。因此,本体设计模式(OntologicalDesignPattern)就成为本体定义元模型中的组定义规则重要相关元素。本体设计模式可以被分类为全局模式和局部模式,相关详细细节请参见文献[16]。
3.2实例与分析
出于业务需要,本体模型A和B(见图4)需进行合并,以完成本体A和本体B所对应不同组织机构的划转和合并。
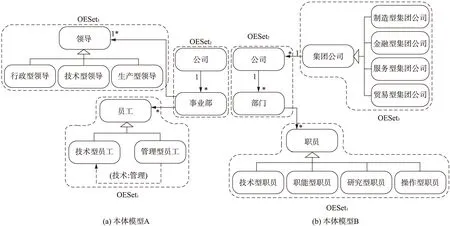
图4 本体模型A和本体模型BFig.4 Ontology models A and B
针对图4中的本体模型A和B,应用组定义规则GroupDefinitionRule1和GroupDefinitionRule 2。
(1) GroupDefinitionRule1。判断某OESet是否服从“Inheritance”模式。
context ODP::Inheritance():Boolean
post: result=self.RelationSet.elements→forAll(p|Relation::ObjectAttribute(p)==FALSE)and self.RelationSet.elements.exist(p|Relation::ChildTaxonomy(p)==TRUE or Relation::ParentTaxonomy(p)==TRUE)
(2) GroupDefinitionRule2。判断某OESet是否服从“Composite”模式。
context ODP::Composite():Boolean
post: result=self.RelationSet.elements -gt;forAll(p|Relation::ChildTaxonomy(p)==FALSE and Relation::ParentTaxonomy(p)==FALSE)and self.RelationSet.elements.exist(p|Relation:: ObjectAttribute(p)==TRUE)
根据本体概念和关系的上下文相关语义,本体模型A可被划分为3个OESet。其中,C、A、T、D、X分别表示本体的5个元素,即概念、属性、分类关系、依赖、公理规则。
A: OESet1={C(员工),C(技术型员工),C(管理型员工),T(员工_技术型员工),T(员工_管理型员工),D(技术型员工_管理型员工)}(近似服从GroupDefinitionRule1)。
A: OESet2={C(事业部),C(公司),A(公司_事业部),A(事业部_领导),A(事业部_员工)}(服从GroupDefinitionRule2)。
A: OESet3={C(领导),C(行政型领导),C(技术型领导),C(生产型领导),T(领导_行政型领导),T(领导_技术型领导),T(领导_生产型领导)}(服从GroupDefinitionRule1)。
相对应地本体模型B也被划分为3个OESet。
B: OESet1={C(职员),C(技术型职员),C(职能型职员),C(研究型职员),C(操作型职员),T(职员_技术型职员),T(职员_职能型职员),T(职员_研究型职员),T(职员_操作型职员)}(服从GroupDefinitionRule1)。
B: OESet2={C(部门),C(公司),A(公司_部门),A(部门_职员)}(服从GroupDefinitionRule2)。
B: OESet3={C(集团公司),C(制造型集团公司),C(金融型集团公司),C(服务型集团公司),C(贸易型集团公司),T(集团公司_制造型集团公司),T(集团公司_金融型集团公司),T(集团公司_服务型集团公司),T(集团公司_贸易型集团公司),A(集团公司_公司)}(近似服从GroupDefinitionRule1)。
将本体模型A中的3个OESet作为合并目标片段,本体模型B中的3个OESet作为并入片段。通过(B: OESet1)与目标片段中的3个片段间的模糊相似度求解,得出(B: OESet1)与(A: OESet1,A: OESet2,A: OESet3)3个片段的相似度分别是{(0.42,0.51,0.55),(0.01,0.02,0.04),(0.08,0.12,0.18)}。系统确定相似片段对{A: OESet1,B: OESet1},进行概念对相似度计算,同时从(B:OESet1)中剔除与(A: OESet1)相似的概念后,经过规则校验发现(B: OESet1)已不是完整的片段,故对{A: OESet1,B: OESet1}进行细节层面上的合并。得到如图5的合并片段,图中斜体部分即为两片段间的相似匹配概念对。

图5 A: OESet1与B: OESet1合并后的新片段Fig.5 Merging module of A: OESet1 and B: OESet1
同时,分别对(B: OESet2)与(B: OESet3)进行类似操作,获得新合并片段。其中(B: OESet3)与(A: OESet3)虽具有一定类似性,但由于两者之间没有类似概念,则它们就不需要进行细节层面上的合并,因此,这两个本体片段均被直接添加到新本体模型中,形成拥有4个片段的合并后本体模型,如图6所示。

图6 本体模型A和B合并后的新本体模型Fig.6 Merged ontology model of ontology models A and B
上述应用实例的相似度计算结果如表1所示,其中黑斜体的三角模糊相似度说明两本体片段已定位为相似的本体片段对,而两片段间能否进行细节层面上合并,仍然需要进一步计算。

表1 本体片段模糊相似度计算结果
3.3时间复杂度分析
考虑到本体模型按照语义相关性存在多种分割方法,不同的分割方法将产生不同的本体合并算法效率,故本节针对本体合并方法中的算法时间复杂度进行进一步分析。为了简化问题,在时间复杂度分析中将本体概念和概念之间关系两种元素同等对待。假设:
(1) 本体模型A,拥有U个本体概念或关系,且本体模型A可被分割为K个本体片段,每个本体片段平均拥有P个概念或关系,且U=KP;
(2) 本体模型B,拥有V个本体概念或关系,且本体模型B可被分割为H个本体片段,每个本体片段平均拥有Q个概念或关系,且V=HQ。
先考虑一般情况下该本体方法的算法时间复杂度。该方法可分为3个步骤。
(1) 本体分割。采用相关组定义规则进行本体分割,其相应的算法时间复杂度与本体中的元素(概念或关系)个数相关,本体模型A和B分割的算法时间复杂度,可表示为X(U)和X(V)。
(2) 本体片段相似度计算及两两定位。由于本体模型A拥有K个本体片段,本体模型B拥有H个本体片段,故进行两者两两匹配的相似度计算的时间复杂度为X(KH)。
(3) 本体片段内部合并。由于本体模型A的本体片段平均拥有P个概念或关系,本体模型B平均拥有Q个概念或关系,故单个本体片段对通过两两相似匹配进行合并的时间复杂度为X(PQ)。
综合(1)~(3),该算法的时间复杂度为
X(t)=X(U)+X(V)+X(KH)+X(PQ)
本文考虑3种特殊情况。
(1) 本体模型被分割成一个模型(即未被分割),K=1,P=U;H=1,Q=V,此种情况下,本体模型A和B之间的概念和关系分别进行两两匹配,其算法时间复杂度为
X(t1)=X(U)+X(V)+X(KH)+X(PQ)=
X(U)+X(V)+X(1)+X(UV)≈
X(UV)
(2) 本体模型被完全细分成单个概念或关系(即被完全分割),K=U,P=1;H=V,Q=1。此情况下,本体模型A的M个片段与和本体模型B的V个片段分别进行两两匹配,其算法时间复杂度为
X(t2)=X(U)+X(V)+X(KH)+X(PQ)=
X(U)+X(V)+X(UV)+X(1)≈
X(UV)
(3) 特殊情况,即
K=P=U/2,H=Q=V/2
此时,时间复杂度为
X(ts)=X(U)+X(V)+X(KH)+X(PQ)=
X(U)+X(V)+X(UV)/2≈X(UV)/2
故得到
X(ts)≈X(t1)/2=X(t2)/2
根据上述分析不难得出,当K≈U/2,且H≈V/2 时,采用该方法进行本体合并能比采用传统方法降低近50%的算法时间复杂度,但由于K与H的取值一般与本体的上、下文语义相关,故在本体分割过程中需尽可能的将K与H的取值设置为U/2和V/2。
4 结 语
本文提出一种基于本体片段模糊相似度的异构本体合并方法,将先按照相关规则分割成多个本体片段,这些片段均具有独立语义(即片段内本体元素高度相关),从而本体之间合并就转换成本体片段间的合并;然后,通过本体片段间的相似度计算,在目标本体模型的多个已分割片段中,定位与待合并本体片段最匹配的片段,再进行两个本体片段间细节层面的合并,以完成本体合并。
本文提出了基于概念或关系的两种本体片段模糊化相似度计算方法,并在此基础上进一步讨论一种基于本体片段模糊相似度的异构本体合并的算法,该算法解决传统本体概念相似度计算过程中出现的模糊推理特性过早判断的问题,因此结构信息可与文本信息协同并行分析以提高片段间的合并效果。
[1] Kotis K,Vouros G A,Stergiou K.Towards automatic merging of domain ontologies: The HCONE-merge approach[J].Journal of Web Semantics,2006,4: 60-79.
[2] Taylor J M,Poliakov D,Mazlack L J.Domain-specific ontology merging for the sem antic web[C]∥2005 Annual Meeting of the North American Fuzzy Information Processing Society.Michigan: IEEE,2005: 418-423.
[3] Richardson B,Mazlack L J.Approximate ontology merging for the semantic web[C]∥Fuzzy Information.Baff Canana:IEEE,2004,2: 641-646.
[4] Qian Pengfei,Wang Yinglin,Zhang Shensheng.Combining instance selection amp; rough set theory in ontology mapping[J].High Technology Letters,2008,14(3): 258-265.
[5] 刘溪涓.数字化产品设计中多形态知识集成[J].上海电机学院学报,2010,13(3) : 130-135.
[6] Qian Pengfei,Wang Yinglin,Zhang Shensheng.Ontology mapping approach based on set amp; relation theory and OCL[J].Journal of Harbin Institute of Technology: New Series,2009,16(4): 498-504.
[7] Qian Pengfei,Wang Yinglin,Zhang Shensheng.Configurable ontology mapping based on multi-feature[J].Journal of Harbin Institute of Technology: New Series,2009,16 (6):781-788.
[8] Zobel C W,Rees L P,Rakes T R.Automated merging of conflicting knowledge bases,using a consistent,majority-rule approach with knowledge-form maintenance[J].Computers amp; Operations Research,2005,32(7): 1809-1829.
[9] Kim J M,Shin H,Kim H J.Schema and constraints-based matching and merging of topic maps[J].Information Processing amp; Management,2007,43: 930-945.
[10] Lee C S,Kao Y F,Kuo Y H.Automated ontology construction for unstructured text documents[J].Data amp; Knowledge Engineering,2007,60(3): 547-566.
[11] Lambrix P,Tan H.SAMBO-A system for aligning and merging biomedical ontologies[J].Web Semantics: Science,Services and Agents on the World Wide Web,2006,4(3): 196-206.
[12] Qian Pengfei,Zhang Shensheng.Ontology mapping approach based on OCL[C]∥Fronties of WWW Research and Development-APWeb,2006.Berlin:[s.n.],2006: 1022-1033.
[13] Qian Pengfei,Wang Yinglin,Zhang Shensheng.Combining ODM and OCL in ontology verification[J].Journal of Harbin Institute of Technology: New Series,2009,16(5): 723-729.
[14] Paul E,Nicolaas J.Bottom-up construction of ontologies[J].IEEE Transactions on Knowledge and Data Engineering,1998,10(4): 513-526.
[15] Wang Yinglin .Method of automatic ontology mapping through machine learning and logic mining [J].High Technology Letters,2004,10(4): 29-34.
[16] Qian Pengfei,Wang Yinglin,Zhang Shensheng.Ontology matching approach based on triangle fuzzy expression[C]∥Challenges in Information Technology Management.Singapore: World Scientific,2008: 17-30.
Heterogeneous Ontology Merging Based on Ontology Slice Fuzzy Similarity
QIANPengfei
(Shanghai Baosight Software Co., Ltd., Shanghai 201203, China)
This paper presents a novel heterogeneous ontology merging approach based on the fuzzy similarity between ontology slices.The ontology model to be merged is divided into many slices having independent semantic meaning, and the merging between ontology models can be transferred to the merging between ontology slices.Two kinds of fuzzy similarity algorithms between ontology slices are proposed based on the concept and relation of ontology, and a heterogeneous ontology merging approach based on fuzzy similarity between ontology slices is discussed.It restrains possibility of making decision to fuzzy characteristic too early in the process of similarity calculation.The structural information can be synchronously analyzed and computed together with text information to improve the effect of merging between ontology slices.The proposed approach is evaluated by an ontology merging application example and related analyses and comparisons.
ontology merging; ontology slice; fuzzy similarity; ontology concept
2095-0020(2013)06 -0365-10
TP 18
A
2003-06-27
钱鹏飞(1978-),男,高级工程师,博士,主要研究方向为本体技术及知识管理,
E-mail: qianpengfei@baosight.com
猜你喜欢
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
制造业自动化(2017年2期)2017-03-20
文学教育(2016年27期)2016-02-28
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
