
ASON网络的路由方案设计及仿真
2013-11-05 06:43高书强李海涛
电子测试 2013年5期
高书强 李海涛
(郑州大学信息工程学院,河南郑州 450052)
1 仿真软件的介绍
在此次仿真中,我们选用OPNET Modeler进行仿真。下面就对这个软件做一些简要的介绍。
1.1 概述
Modeler提供了一个协议开发和器件、网络模型的开发环境,可以进行高效、准确的仿真。为网络优化、降低成本、缩短投放市场的时间等提供了方便。我把Modeler开发分为三种:一是上层开发,利用内部已有模型搭建符合要求的网络,通过配置外部属性改变网络特性,通过设置不同的统计量,了解网络各个方面性能。二是底层开发,通过编程的方式,利用Modeler内部机制,开发出灵活性更强的模型。三是二者结合,既利用内部模型函数又自己编制程序,这可以省去很大的工作量,减短开发周期。
1.2 Modeler仿真的层次结构
Modeler仿真以project为单位,一般一个project完成一项仿真任务。而一个Project是一系列网络实例(scenario)的集合,而每一个实例研究网络设计的一个方面,如不同的scenario可能是采用的协议不同、统计方向不同、拓扑不同等等。一个Project 至少有一个scenario。
Modeler仿真,是一个分层构建的过程,从底往上,像盖房子一 样。Link、 packet、Ici,etc.—process—node—network。一个可以有一个或几个network 。
2 ASON节点模块的设计
在这里,由于ASON的节点主要由3个模块来构成,所以主要由ASON的RC(路由模块),CC(信令模块)和LRM(链路资源管理)所构成。具体连接图沿用ASON仿真组上一次的设计,在这里面要能够提供业务发生器的部分,以在节点的外部接口可以直接设置业务的属性,以便以后不同网络状况的的输出比较。
这里lrm资源管理、自动资源发现、故障定位和恢复,CC分发信令来实现控制平面对传送面的控制信息,他们和RC模块构成了对ASON控制平面的作用的执行,而在仿真中由于要依赖IP网组建ASON的控制平面,信令和LSA要通过IP网络传输,这里的ip_encap和ip模块就是完成数据包的封装和IP传送功能,CPU的作用是主要是协调各个模块,分配仿真资源。
2.1 仿真所用的拓扑介绍
为保证仿真的真实性,此次仿真所用的是NSFNET,共有16个节点,研究对象的粒度为波长极。下图为NSFNET拓扑结构,这次仿真主要采用的是静态拓扑输入。
2.2 仿真统计如图所示
仿真时间为1小时,计算历时6分56秒,仿真事件9152462件,平均每秒21963件,仿真结束未发生错误。
仿真中的完成一次Flooding所传送控制信息的平均开销(AOF)如下图:
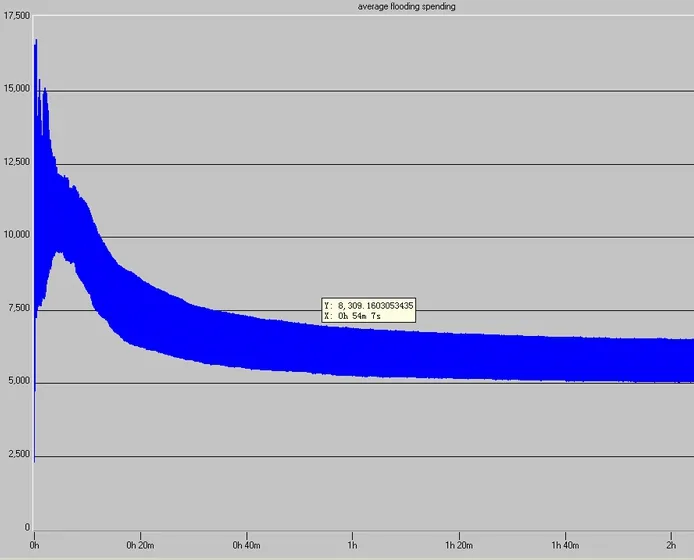
从上图可以看出,在仿真开始的约10分钟,flooding的开销很大,每次 1Mbit,过后慢慢趋于平静,约没次平均5500bit,造成这种的原因应该是在仿真开始之初的一段时间里,各个节点的网络状况和初始化还没有完全稳定下来,所以造成那在这段时间里由于网络各节点之间的拓扑未同步,并且此时真正的业务还没有完全建立起来,网络中有大量的控制面的信息需要交互,这就造成了LSA的收发的成功率,于是节点RC就需要重复发送LSA以确保所有节点之间的链路状态的同步,从而造成了此时的每次flooding的开销比较大,一旦网络状况稳定下来以后,业务开始建立,此时的控制平面的改变较少,并仅仅在链路状况改变的情况下才flooding其相应的LSA,控制平面需要的带宽较少,比较不容易引起拥塞,从而flooding的开销会比较稳定。
完成一次Flooding的平均时间(ATF)的显示图表如下:
为了比较方便,我们把flooding的平均时间设定为本地变量,这里我们将选取4个节点来输出结果分析:
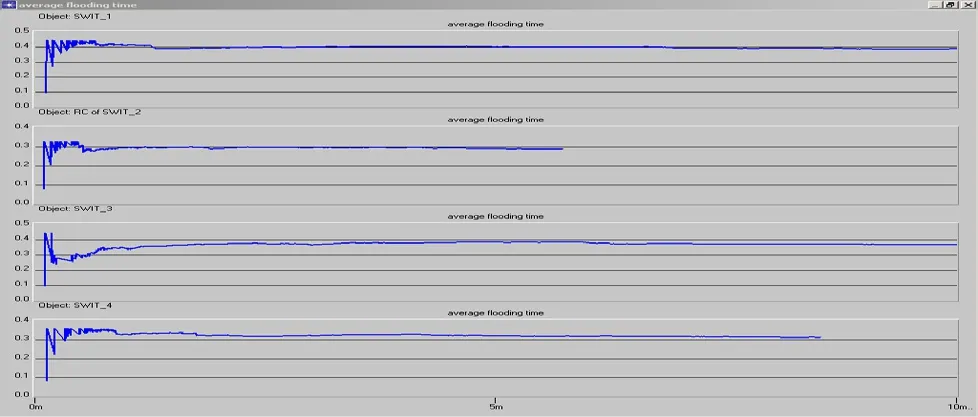
这里我们可以看出,由于在网络中所处的位置不同,在结果中每次flooding所需要的时间也不尽相同,当还是大致的都在0.3秒到0.5秒之间的一个值收敛,这里也出现了在仿真开始之初的不稳定情况,和上面的关于flooding的开销的分析相似,还有一点要注意的是在仿真中仿真的时间是1小时,但是在这里有些节点的存在flooding的时间却只有10分钟左右,这个原因有几种可能:
1.前面已经讲过,由于在ASON控制平面中,仿真的时间较短,可能在信令系统接收到业务的请求并建立业务以后,业务的持续时间比较长,就可能引起在业务建立以后的较长一段时间里没有新的业务。
2.在此,由于RWA算法还未成功移植,在这里就表明链路的状态没有发生变化,所以就没有LSA信息的分发。
3.程序故障,可能是RC,CC,LRM模块之间的交流存在一些问题。
4.网络资源的配置问题。
仿真时间也为1小时,计算历时10分31秒,仿真事件6735658件,平均每秒10661件,仿真结束未发生错误。在这里,业务量大约是上次仿真的一半,其结果如下:
仿真中的完成一次Flooding所传送控制信息的平均开销(AOF)如下图:
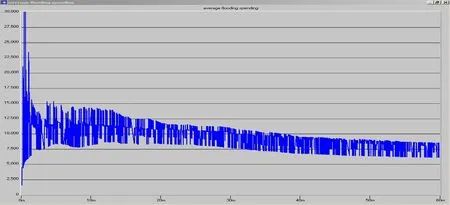
在比较中,我们可以看出,在业务量比较小的情况下,平均网络收敛的时间变短,平均每次flooding的开销也在7500bit/次。说明当网络比较稳定的情况下,每次flooding的开销大致相等。在业务量比较小的时候,链路的变化也比较少,平均每段时间内所产生的链路状态改变也比较少,所以产生的LSA也相对较少。
完成一次Flooding的平均时间(ATF)的显示图表如下:
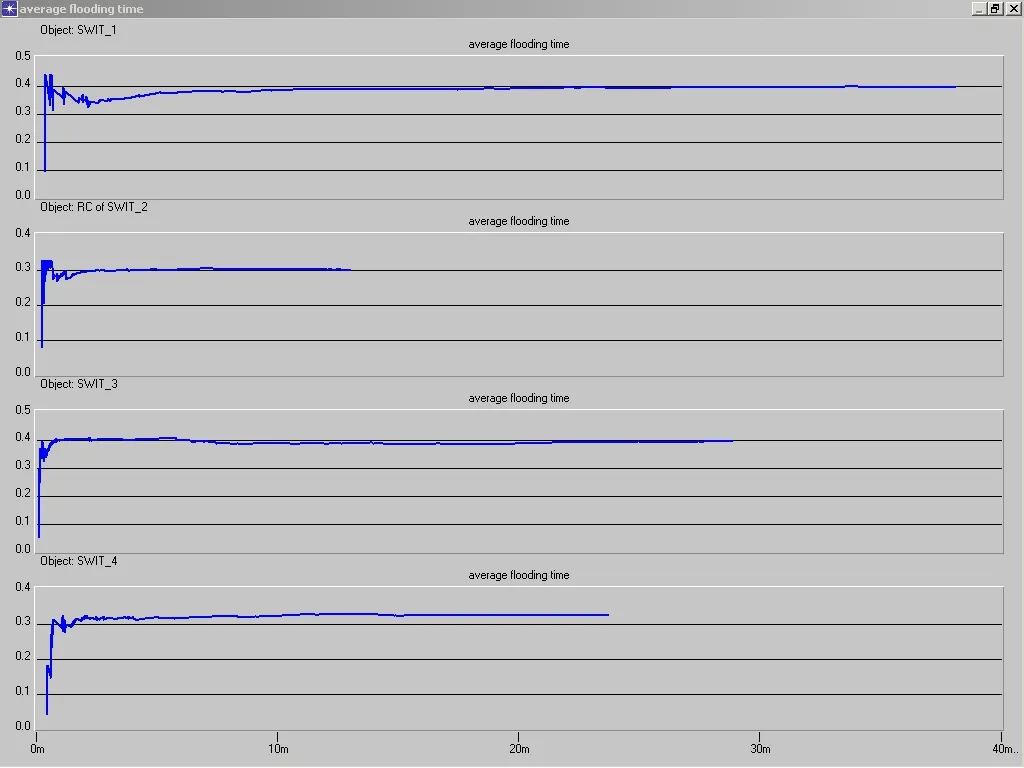
这次我们的设置中,每个节点发生的业务强度也不一样,在图中我们可以看出,业务量最大的节点3中,大概在10几秒以后就不再有要flooding的广播数据包产生,我们可以并且可以看出他flooding的时间要比别的节点好,说明它在网络中的位置比较好,所属链路的链路状况比较好,这在也第一次的仿真结果比较中我们可以看出,平均每次flooding所需要的时间大致相当,这说明了基本上平均每次flooding所需要的时间是与控制平面的拓扑有关系。在这次的仿真结果中我们看得出,节点有链路状态变化的时间虽然也没有到完全仿真时间,但是比起是一次来说已经提高很多,并且业务量最大的节点三也是最先产生链路状态无变化(这里的变化值得是相对的变化,比如说所用信道带宽占总带宽的权值),就是说明在上次分析的原因中,所讲的第二中情况,即网络的带宽在业务发起的一段时间后会达到一个相对大的值,这个时候相对所占带宽的权值就没有变化,造成了一段时间后就没有新的链路状态相对变化。当然这里也不能完全排除其他的情况,所以还是需要进一步的比较分析,说明。并且在不同的业务发生强度,业务持续时间,业务量的情况下做相应的比较分析。
此次仿真还未解决的问题:
1.在仿真中对于过期的LSA确认(所需确认的LSA链路状态已经重新改变,所属sequence number也已经更新),在本次的仿真中所做的处理是直接释放,这些信息还是否需要保存仍然需要继续研究。
2.在本次中,所用的路由算法应采用RWA算法,但是由于项目组的原因并未实现,仍然沿用老的链路权值计算方法。
3.在于CC的交流中,CC模块也是所用的老的模块,新的资源预留的模块还未完成,没有办法比较在资源预留情况下所用算法的优劣。由于采用的老的算法在给CC显式路由时以查算好路由表的方法,在OPNET仿真中,其返回时间约为0,所以没法统计平均的路由计算时间。
[1] B. Wu, A.D. Kshemkalyani. Objective-optimal algorithms for long-term Web prefetching. IEEE Transactions on Computers, 2006, 55(1):2-17
[2] X. Chen, X. Zhang. A popularity-based prediction model for Web prefetching. Computer. 2003,36(3):63-70
[3] Lei Shi, Yingjie Han, Xiaoguang Ding, Lin Wei,Zhimin Gu, An SPN based Integrated Model for Web Prefetching and Caching, Journal of Computer Science and Technology, 2006, 21(4): 482-489
猜你喜欢
移动通信(2021年5期)2021-10-25
中国经济周刊(2021年1期)2021-02-05
空间科学学报(2020年3期)2020-07-24
铁道通信信号(2020年9期)2020-02-06
时代风采(2019年8期)2019-08-26
太原科技大学学报(2019年3期)2019-08-05
网络安全和信息化(2018年3期)2018-11-07
电信科学(2016年11期)2016-11-23
中国交通信息化(2014年3期)2014-06-05
自动化与仪表(2014年10期)2014-02-26
