
一种新的生成候选关键词集的方法
2013-10-22 02:44许爱琴王梦洁刘永坚王卫华
武汉理工大学学报(信息与管理工程版) 2013年6期
许爱琴,王梦洁,刘永坚,王卫华
(1.武汉理工大学理学院,湖北 武汉 430070;2.武汉理工大学计算机科学与技术学院,湖北 武汉 430070)
自动标引是一种利用计算机自动给出信息主题词或关键词的技术。这一技术涉及到如何从信息中提取有实意的词汇,并从这些词汇中分析能够代表一段信息或一篇文章主题意义的词汇[1]。关键词是表达文件主题意义的最小单位,它可以提高信息检索的准确性,帮助读者快速查找相关内容所需的文献信息。但由于传统的人工标引关键词费时费力且主观性较强,不利于下一步的检索,因此,对关键词提取技术的研究是一项具有重要意义的工作。
在西文文献的自动标引中,相比于单个的单词,单词序列即词组有语法结构,对于表达信息的主题有较强的代表能力。西文关键词的提取主要包括3个步骤:①候选关键词集的自动识别;②引入一系列特征来计算候选集里关键词的权重并按权值排列;③用一个监督模型从具有相应权值的候选集中选取出最终的关键词汇[2]。笔者主要讨论候选关键词集的自动识别。目前,最常用的识别方法有两种:基于NGram 法[3]和基于词性序列法(又称 POS 法)[4]。由于每个候选集权值必须在步骤②中计算,而这一步占据了系统运行的大部分时间,因此,大量的候选集必然会导致系统效率低下[5]。笔者在N-Gram基础上提出了关键单词拓展树算法,由此产生候选关键词集,并将其与N-Gram法产生的候选集大小进行比较。
1 关键单词集
1.1 关键单词与关键词的关系
关键单词是指文本中重要的单个的单词,在文本中出现的频率较高,而关键词是指由一个或几个单词组成的具有一定的表达文本主题的单词串。通常直观地认为关键词一定包含关键单词,而笔者认为在一特定领域的文章标引中,关键单词可以作为发现关键词的基础,这里主要针对科技文献这一领域。基于关键单词发现关键词的方法可以在一些现存的相关作品中发现,如TURNEY的作品[6]。笔者通过一个统计研究实验来验证这一思想。
通过输入2~10个关键词自动抽取出400篇科技相关论文,实验前一般要对输入计算机的文本进行预处理。设k为关键单词的个数,a为以关键单词开头或结尾的关键词在所有已知关键词中的比例,b为所有关键单词的频数在预处理后文本中占据的比例。通过改变k的值,计算分析a和b值的变化情况。其分析结果如图1所示。
从图1中可以分析出绝大多数的关键词是以关键单词集中的单词开头或结尾的。当k增大时,a和b都在增长,当 k增大到40时,a高达90%以上,虽然b不到40%,通过比较a与b,可以得出关键单词对待测关键词有较大的覆盖能力,因此可以通过先抽取关键单词集,再由关键单词前后拓展得到待测关键词,找出每个关键单词在文本中的位置。
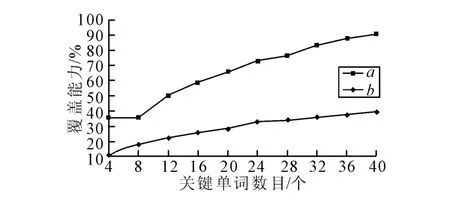
图1 关键词数目与其对关键词抽取的覆盖能力比较
1.2 关键单词集的获取
关键单词集的获取[7]必须在已经预处理过的文本中选取,通过计算该文本中的所有非停用单词的频率,将其按从大到小的顺序排列,并记录它们每次出现时对应文本中的位置,当k的大小确定了,就取频率大小排在前k的非停用单词,同时将它们的位置记录一起取出。这样关键单词集就确定了,这里不妨记其为Mkw={(Wi,Pi),i=1,2,…,k},其中 Wi为单个关键单词,Pi为 Wi出现的位置矩阵。根据图1分析可知,当k取40时,关键单词对关键词的覆盖率达到90%以上,因此,建议将关键单词的个数设置为40。
2 关键词的形成算法
根据Porter茎算法[8]中在相同茎下的单词进行组配成词的思想,先描述基于关键单词集产生候选集的前拓展算法,所谓前拓展就是以关键单词开头的关键词。统计表明,包含4个单词的关键词是相当少的,把一个关键词的最大长度设置为4是合理的[9]。同现存的很多抽取系统一样,笔者设置一个临界值来过滤掉低频数的单词组合,在这里可设置为3[10],即在文本中出现次数小于3的词待测集将自动过滤,其具体算法过程如下:
(1)输入已预处理过的文件及其关键单词集Mkw;
(2)赋值每次抽取Mkw中的一个关键单词Wi和它的位置矩阵Pi,并用*标记它为非叶节点;
(3)根据Porter茎算法,将Wi作为根节点开始建立拓展树;
(4)当在建的拓展树中含有未拓展的非叶节点时,分别取出每个非叶节点和它的位置矩阵,做如下处理,转入步骤(5),否则转入步骤(10);
(5)将非叶节点的深度(即由根节点开头到该节点的单词序列的长度)记为L,若L<4,则将该非叶节点的位置矩阵中每个元素的下个位置所对应文本中的单词放入一个子集合中,不妨记为Mi,转入步骤(6);若 L≥4,则转入步骤(9);
(6)对Mi全体元素利用Porter茎算法分别对其茎进行拓展,其中Mi中的每个不同茎(即Mi中的一个元素)记为wj,转入步骤(7);
(7)赋值wj和其在文本中其父节点这个单词之后出现的位置矩阵,若其位置矩阵的元素个数小于3,或wj是一个词边界,则用#标记其为叶节点,反之则用*标记为非叶节点,转入步骤(8);
(8)再从Mi中取出与步骤(7)中不同的茎,同样对其进行步骤(7)的操作,直至取完Mi中的元素,转入步骤(4);
(9)建立一个空的叶节点集作为非叶节点的子节点,则对该非叶节点的处理结束,转入步骤(4);
(10)取拓展树的一个叶节点,对树的这个叶节点进行向根节点方向回溯,直到遇到第一个非停用词节点时停止,则从根节点开头到这个非停用词节点结尾的单词组合称为一个待测关键词,转入步骤(11);
(11)取拓展树的一个其他不同于步骤(10)中的叶节点,重复步骤(10)的操作直至所有叶节点都被处理完,则转入步骤(12);
(12)输出具有频数和位置信息的候选关键词集。
笔者用一个简单例子解释其具体运算,随意抽取一篇西文科技文献的一个关键单词candidate在文章中每次出现的位置,具体每次出现的片段是:①The first step is called candidate phrase identification or its generation;②Some candidate phrase identification methods were proposed in previous works;③Unsupervised approaches usually involve assigning a saliency score to each candidate phrase by considering various features;④We argue that distinguishing strong candidates from weak ones should not only rely on feature engineering[11]。由于一个关键单词的每次出现都会伴随着一个以它开头的单词序列,根据上述算法的相关设置,可知这个单词序列的最大长度为4,因此只需要从该关键单词开始向后依次再取出3个单词,即candidate phrase indentification or、candidate phrase indentification methods、candidate phrase by considering 和candidates from weak ones。
为了简化书写和便于理解,用不同字母和符号代替不同单词及其在文本中的位置,用‖代表词边界,则预处理后的简化形式和拓展树如图2和图3所示。

图2 预处理后简化图
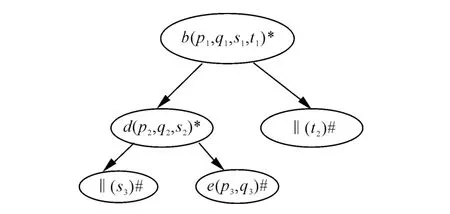
图3 关键单词candidate的前拓展树
根据图3的前拓展树及其算法过程的步骤(10)可知,由candidate产生的候选关键词为cd和d,即还原为 candidate phrase和 candidate。再来分析前拓展树,由关键单词开头的每个单词序列相当于拓展树的一个枝干,用数学语言更准确地说,如果用集合P代表关键单词每次出现的位置,集合S代表所有不同的以关键单词开头的所有单词序列,集合B代表树的所有枝干,则函数f:P→S为满射,函数g:S→B为双射。结合算法可得出树的每条枝干最多形成一个候选关键词,换句话说就是关键单词的每次出现最多产生一个候选关键词。再回到该例子,candidate的第一次、第二次和第三次出现都产生了candidate phrase,第四次出现产生了candidate,也完全符合以上的分析,对于第一次、第二次和第三次产生的候选关键词只取一次就行了。
后拓展树算法与上述算法十分相似,只需稍做改变,首先将步骤(5)中的下一个位置改为上一个位置,再对步骤(10)中的操作进行反序操作,即从非停用词节点到根节点取候选关键词。其实验结论与前拓展树是一样的。
随后笔者再次通过输入2~6个关键词自动选取了100篇科技类文章,随机抽取每篇文章中的2个关键单词进行前后拓展树算法,并画出拓展树图,记录对应产生的潜在候选关键词。实验结果表明,关键单词的每次出现仍然都最多可产生两个潜在候选关键词,前后拓展树分别产生一个。这里所说潜在候选关键词是因为有些单词序列组合可能无意义,形成后还要再次进行筛选。
3 前后拓展树算法与N-Gram法的比较
传统的基于N-Gram法形成潜在候选关键词的方法在先前的许多研究中都被采用了[12],其过程简单描述如下:首先,根据词边界将输入文本分解;其次,将长度在一定范围内的词序列和其子序列抽取出来当做初步的候选关键词集;最后,设置一些法则来过滤掉无意义的词序,例如候选关键词不能以停用词开头或结尾。在后来的标引系统中N-Gram法得到更进一步的改善和提高[13-14],如将候选关键词的最大长度设置为4,则所有小于或等于4的N-Gram都可能称为候选关键词。具体到某个关键单词,不妨记为Wp,其中p为在文本中出现的位置,则所有的候选词将出现在单词序列 Wp-3Wp-2Wp-1WpWp+1Wp+2Wp+3中,其包含关键单词Wp本身,以及所有的2-Gram、3-Gram和4-Gram,再排除不含关键单词或包含在内部的词序列,这样就可将基于N-Gram法产生的所有候选关键词列于表1中。

表1 由关键单词产生的潜在候选关键词
由表1可知,通过N-Gram法对于关键单词的每次出现产生潜在候选关键词的最大数目为7个,然而这7个中的一些潜在关键词有可能是无意义的,一些系统都有相应的过滤操作将其过滤,但是由这种方法产生的候选关键词集仍然较大。而采用上述关键单词前后拓展树算法,关键单词的每次出现最多产生两个候选关键词,因此可推算该算法将通常的N-Gram法产生的候选关键词减少1/2以上。
4 结论
所提出的方法只需要将每个关键单词前后拓展,其中拓展树的深度设置为4,过滤临界值设置为3,这样就可得到一个相对较小的候选关键词集以便于后面的操作。但是还要考虑该算法的时间复杂性,由于拓展树的时间复杂性等同于深度优先策略(即O(n))的复杂性,而深度优先策略与其他抽取系统的复杂性是相似的。由此可以表明,该算法是在没有增加计算难度的同时达到了减小候选关键词集的效果。
[1]苏新宁.信息检索理论与技术[M].北京:科学技术文献出版社,2004:208-210.
[2]刘华.关键词自动标引系统实现[J].现代图书情报技术,2006(2):88-90.
[3]KUMAR N,SRINATHAN K.Automatic keyphrase extraction from scientific documents using N-gram filtration technique[C]∥Proceedings of the 8th ACM Symposium on Document Engineering.Sao Paulo:[s.n.],2008:199-208.
[4]HULTH A.Improved automatic keyword extraction given more linguistic knowledge[C]∥Proceedings of the 2003 Conference on Emprical Methods in Natural Language Processing.Sapporo:[s.n.],2003:216 -223.
[5]BEREND G,FARKAS R.SZTERGAK:feature engineering for keyphrase extraction[C]∥Proceeding of the 5th International Workshop on Semantic Evaluation.Uppsala:[s.n.],2010:186 -189.
[6]TURNEY P D.Coherent keyphrase extraction via web mining[C]∥ Proceedings of the 20th International Joint Conference on Artificial Intelligence.Acapulco:[s.n.],2003:434 -439.
[7]HULTH A,MEGYESI B.A study on automatically extracted keywords in text categorization[C]∥Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics.Sydney:[s.n.],2006:124-154.
[8]PORTER M F.An algorithm for suffix stipping[J].Program,1980,14(3):130 -137.
[9]FRANK E,PAYNTER G W,WITTEN I H.Domainspecific keyphrase extraction[C]∥Proceedings of the 16th International Joint Conference on Aritifical Intelliegence.Stockholm:Morgan Kaufmann,1999:668 -673.
[10]EL-BELTAGY S R,RAFEA A.KP-miner:a key phrase extraction system for english and arabic documents[J].Inf Syst,2009,34(1):132 - 144.
[11]WEI Y,DOMINIQUE F,JEAN-PAUL B.An automatic key phrase extraction system for scientific documents[J].Knowl Inf Syst,2013(34):691 - 724.
[12]TURNEY P D.Learning algorithms for key phrase extraction[J].Inf Retrieval,2000,2(4):303 -336.
[13]HUANG C,TIAN Y,ZHOU Z,et al.Key phrase extraction using semantic networks structure analysis[C]∥Proceedings of the 6th International Conference on Data Mining.Hong Kong:[s.n.],2006:275 -284.
[14]WAN C H,ZHANG M,RU L Y,et al.An automatic online news topic key phrase extraction system[C]∥Proceedings of 2008 IEEE/WIC/ACM International Conference on Web Intelligence.Sydney:[s.n.],2008:214-219.
猜你喜欢
中老年保健(2022年1期)2022-08-17
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
阅读(快乐英语高年级)(2020年8期)2020-01-08
资源信息与工程(2019年2期)2019-05-09
智慧少年·故事叮当(2018年11期)2018-05-14
温州医科大学学报(2018年8期)2018-03-03
意林(绘英语)(2017年5期)2017-05-15
温州医科大学学报(2016年2期)2016-03-16
中国商人(2013年1期)2013-12-04
中国商人(2013年1期)2013-12-04
