
基于强类型DataSet的批量数据导入的优化算法
2013-10-15 05:04刑千里李永丽董立岩尹相杰
吉林大学学报(信息科学版) 2013年2期
孙 鹏, 刑千里, 李永丽, 董立岩, 张 亮, 尹相杰
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 东北师范大学 计算机科学与信息技术学院, 长春 130117)
0 引 言
NET是用来编写各种类型应用的全新框架[1]。它具有灵活性、 高扩展性, 统一的用户接口; 与数据库的良好集成性。ASP.NET是一种服务器端技术, 所有的开发、 升级、 维护都在服务器端完成, 不必涉及客户端; .NET提供了一套ADO.NET技术, 可用于创建分布式的、 数据共享的应用程序, 可快速、 方便地与数据库进行交互[2]。
为简化开发, 化简对数据库的操作, 选择使用ADO.Net中DataSet进行开发, 鉴于DataSet分为强类型DataSet和弱类型DataSet两种, 以往的做法是: 如果优先考虑应用程序的性能和控制, 则要使用弱类型DataSet对象和sqlDataAdpter; 但要牺牲一部分性能, 以节省开发时间, 由于使用该强类型DataSet对批量数据处理需要进行频繁的数据库开关操作, 浪费了大量的时间, 使系统效率低下。笔者从以上问题出发, 分析了强类型DataSet的工作原理, 给出了优化算法, 在节省开发时间的同时提高应用程序的性能。该算法适用于大部分支持存储过程的大型数据库[3], 并在SQLServer2008环境下进行测试。
1 强类型DataSet

图1 DataSet类的层次结构
DataSet类是ADO.NET中最核心的成员之一, 同时也是各种基于.Net平台开发数据库应用程序最常接触的类。DataSet类之所以在ADO.NET中具有特殊的地位, 是因为DataSet在ADO.NET实现与数据库交互数据时起到关键作用。DataSet类的层次结构如图1所示。
DataTableCollection包含特定数据集的所有DataTable对象; DataTable表示数据集中的一个表; DataColumnCollection表示DataTable对象的结构; DataRowCollection表示DataTable对象中的实际数据行; DataColumn表示 DataTable对象中列的结构; DataRow表示DataTable对象中的一个数据行[4]。
DataSet是数据的存放地, 是各种数据源中的数据在计算机内存中映射的缓存, 可把DataSet当成内存中的数据库。DataSet是不依赖于数据库的独立数据集合[5]。即使断开数据链路, 或关闭数据库, DataSet依然可用。所以, 有时DataSet可看成是一个数据容器。同时它在客户端实现读取、 更新数据库等过程中起到了中间部件的作用[6]。
DataSet又分为弱类型DataSet和强类型DataSet两种。强类型DataSet是从弱类型DataSet派生的类。它继承弱类型DataSet的所有方法、 事件和属性。而且, 强类型DataSet提供强类型的方法、 事件和属性。
使用ADO.NET弱类型DataSet存在一些问题。首先, 索引器中返回的都是Object类型, 在程序中使用该数据时还需转换为对应类型, 这使程序的编写非常麻烦; 其次, 取出DataSet列值时只能通过列名引用, 如果写错了列名编译时不会报错, 但给程序调试带来很大的不便; 再次, 将DataSet传递给其他使用者时, 使用者很难识别有哪些列可以使用。
强类型DataSet正是为了解决上述问题而设计。“强类型”通常指程序中表达的任何对象所从属的类型都必须能在编译时确定[7]。强类型DataSet突出的特点是将数据行和列作为对象的属性公开, 而不是作为集合中的项公开。可以通过强类型的属性名称而不是基于字段查找的方式访问表和字段的值, 在编译程序时, 由编译器进行类型检查, 使人们可继续进行其他任务而不必担心是否已经正确输入了列名。此外, 强类型数据集还可借助Visual Studio智能感知查找表或字段的名称。强类型DataSet所提供的设计和编译支持不但大大减少启动开发时间, 而且可减少调试和稳定应用程序所需的时间。尽管如此, 也有一定的不足, 即在创建、 填充和访问时需要更多的时间。
2 强类型DataSet内部方法工作原理

图2 批量数据导入的流程示意图
使用强类型DataSet内部的adapter.Insert()方法进行批量数据导入的流程示意图如图2所示。在执行操作之前进行判断, 如果数据库连接是关闭的, 则自动打开, 然后进行具体操作。当操作完成时, 方法内部判断执行操作前数据库的连接是否处于关闭状态, 如果关闭, 则执行关闭数据库的链接操作。这种方法可很好地控制数据库的链接, 使其在不使用的情况下为关闭状态[8]。但是, 在使用强类型DataSet中的adapter.Insert()方法时, 如果开始数据库的连接是关闭的, 则需要在每插入一条数据时进行一次数据库连接开关操作。如果将一个文本文件导入到数据库中,该文本文件有几万条数据, 导入每条数据都需要调用一次adapter.Insert()方法, 都要有一次连接的打开和关闭的过程, 则需要进行几万次的数据库连接开关操作。数据库连接开关操作是非常耗时的, 浪费了大量的时间, 使系统效率低下, 所以笔者引进了优化算法。
3 算法描述
Step1 算法开始; 获取外部文件的路径及名称。
Step2 新建一个离线数据集DataSet, 用来存储外部文件中的数据。
Step3 将外部文件中的数据添加到DataSet中, 此时的离线数据集记为D={D1,D2,…,Di,…,Dn}, 其中Di表示第i条数据。
Step4 新建一个计时器对象stopwatch, 并打开计时器。
Step5 生成adapter对象。
Step6 测试数据库的连接状态, 如果数据库的连接状态是关闭的, 则将其打开。
Step7 for eachDi∈D{用强类型DataSet提供的adapter.Insert()方法, 将Di插入数据库}。
Step8 将数据库的连接状态设置为关闭状态。
Step9 关闭计时器, 记录所用时间, 算法结束。
算法表明, 如果开始就将数据库的链接状态手动设为打开, 每插入一条数据时则无需进行两次开关操作, 等全部的操作结束后, 再关闭数据的链接。这样就使一系列的操作都处于连接状态, 从而在批量数据导入的过程中节省了大量的数据库开关操作, 节省了时间, 提高了导入效率。将数据从外界表格导入数据库, 分为两个步骤, 首先把数据从表格提取到DataSet中; 然后使用强类型 DataSet 所提供的adapter.Insert()方法将DataSet中的数据导入数据库, 下面对其分别进行研究[9]。
4 实验与实现
4.1 实验1
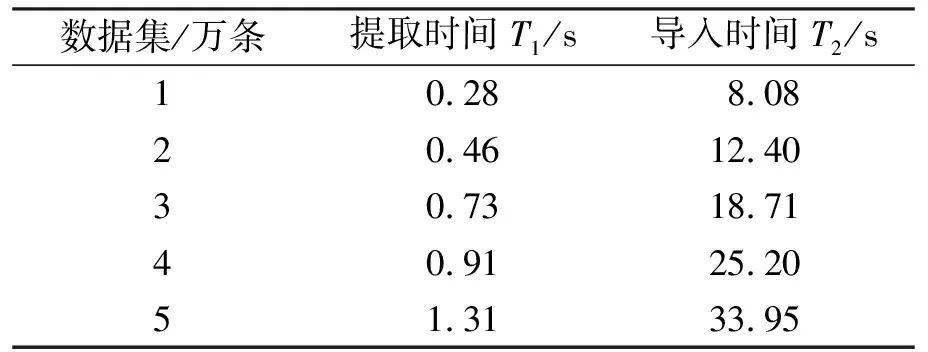
表1 提取数据与导入数据所用时间的比较
用D表示外部文件的数据数量; 将数据从外部表格文件提取到DataSet中所用的时间记为T1; 把用强类型DataSet所提供的adapter.Insert()方法将DataSet中的数据导入数据库所用的时间记为T2。分别测量不同数量导入数据的T1和T2值(见表1)。
实验结果表明, 数据从表格提取到DataSet中所用的时间微乎其微, 即使数据量很大, 提取速度也非常快。所以, 整体批量数据导入效率低下的问题出现在导入数据的部分, 从而主要针对导入部分使用优化算法。
4.2 实验2
通过Stopwatch提供的方法测量出不同批量的数据导入数据库所需的时间。选择不同数据量的数据作为测试数据, 记录所需时间, 并绘制图表(见图3)。
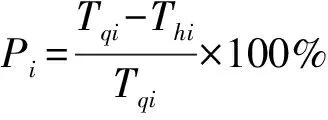
从表2可看出, 当从外界的文本中插入5万条数据时, 优化后所用时间节省了71.61%。

图3 优化前、 后所用时间随插入数据变化的曲线
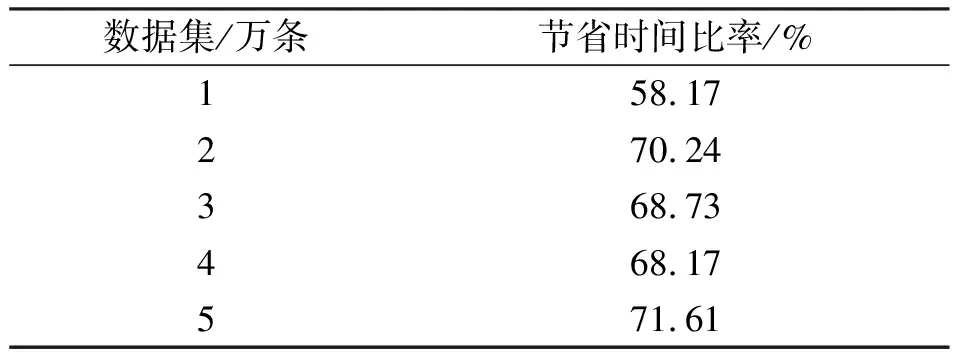
表2 优化后导入部分所节省的时间比率
实验中如果导入一条记录所用的时间是t, 应用优化算法后导入D条数据所用时间为t×D, 如果直接使用强类型DataSet中的adapter.Insert()方法, 记打开一次数据库连接耗时为m, 关闭一次数据库的连接耗时为n, 根据强类型DataSet内部方法工作原理得知, 在每次循环内都需要进行上述两种操作各一次, 所以耗时(m+n)。因而导入D条数据时要比使用该优化算法多耗时(m+n)×D[10]。
该算法中既不包含嵌套的循环也没有并列循环, 基本语句在for循环内部, 算法的时间复杂度为O(n)。程序运行过程所要借助的内存空间大小随着外部文件数据量大小而线性变化, 所以该算法空间复杂度是为O(n)。
5 结 语
批量数据导入技术是提高数据录入速度的有效途径。笔者实现了将系统外部文件的大量数据批量导入到数据库中, 在简化开发的同时又提高了系统的执行效率。 该方法比较实用, 为数据库信息管理及软件开发人员提供了一定的参考。
参考文献:
[1] PARIHAR M ASP. NET宝典 [M]. 北京: 电子工业出版社, 2002.
PARIHAR M ASP. NET Collection [M]. Beijing: Publishing House of Electronics Industry, 2002.
[2]王华昌, 孙锦程, 李志刚. 基于.NET平台的3D标准模架库系统的开发 [J]. 华中科技大学学报: 自然科学版, 2005, 33(10): 10-12.
WANG Hua-chang, SUN Jin-cheng, LI Zhi-gang. NET Platform-Based Development of 3D Standard Mold Base Library System [J]. Huazhong University of Science and Technology: Natural Science Edition, 2005, 33(10): 10-12.
[3]李兵, 刘淑芬. 海量数据下的Web分页呈现研究 [J]. 吉林大学学报: 信息科学版, 2005, 23(5): 517-518.
LI Bing, LIU Shu-fen. Web Paging Research under the Massive Data Presents [J]. Journal of Jilin University: Information Science Edition, 2005, 23(5): 517-518.
[4]张建成, 李春青. 基于.net环境下ado.net访问数据库技术的研究 [J]. 电脑知识与技术, 2009, 22(5): 6102-6104.
ZHANG Jian-cheng, LI Chun-qing. .NET Environment Ado.Net Access Database Technology-Based Research [J]. Computer Knowledge and Technology, 2009, 22(5): 6102-6104.
[5]徐枫. DataReader与DataSet对象之比较分析 [J]. 现代电子技术, 2008(7): 185-187.
XU Feng. Analysis of Compare between DataReader and DataSet [J]. Modern Electronics Technique, 2008(7): 185-187.
[6]梁艳. 对Visual Studio.NET DataSet的几点讨论 [J]. 辽宁科技学院学报, 2006, 8(1): 13-14.
LIANG Yan. Some Discuss of Visual Studio.NET DataSet [J]. Journal of Liaoning Institute of Technology, 2006, 8(1): 13-14.
[7]徐家福. 系统程序设计语言 [M]. 北京: 科学出版社, 1983.
XU Jia-fu. System Programming Languages [M]. Beijing: Science Press, 1983.
[8]孙仁鹏. ADO.NET在多层模式下应用的研究 [J]. 计算机工程与设计, 2010, 31(16): 3621-3624.
SUN Ren-peng. The Research to Application of ADO.NET under Multilayer Mode [J]. Computer Engineering and Design, 2010, 31(16): 3621-3624.
[9]黄汛, 程治刚. 数据库连接池技术的应用研究 [J]. 武汉大学学报: 工学版, 2002, 35(1): 98-101.
HUANG Xun, CHENG Zhi-gang. Research on Application of Connection Pool Technique for Database [J]. Engineering Journal of Wuhan University, 2002, 35(1): 98-101.
[10]黄翰, 郝志峰, 秦勇. 进规划算法的时间复杂度分析 [J]. 计算机研究与发展, 2008, 45(11): 1850-1857.
HUANG Han, HAO Zhi-feng, QIN Yong. Time Complexity of Evolutionary Programming [J]. Journal of Computer Research and Development, 2008, 45(11): 1850-1857.
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
科学家(2021年24期)2021-04-25
中学生数理化·中考版(2020年10期)2020-11-27
制造技术与机床(2019年11期)2019-12-04
意林(2018年3期)2018-03-02
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
财经(2016年6期)2016-02-24
