
中文篇章级句间语义关系识别
2013-10-15 01:52张牧宇
中文信息学报 2013年6期
张牧宇,宋 原,秦 兵,刘 挺
(哈尔滨工业大学,黑龙江 哈尔滨150001)
1 引言
随着词汇语义、句子语义研究的逐渐成熟,篇章级语义分析逐渐成为研究热点。作为篇章语义分析的重要内容,篇章句间关系识别(Discourse Relation Recognition)也受到了越来越多的关注。该研究检测同一篇章内,两个文本单元(片段、分句、复句、句群、段落等)之间的逻辑语义关联(例如,因果关系)。通过定义层次化的语义关系类型体系将句内的语义分析结果扩展为篇章级的语义信息,从而成为语义分析的重要解决途径之一,对自动文摘[1]、自动问答[2]、倾向性分析[3-4]以及文本质量评价[5]、文本连贯性评价[6]等许多NLP任务起到了很大的帮助。
根据文本单元间是否存在篇章连接词(也称作篇章关联词),可将篇章句间关系分为显式篇章句间关系(Explicit Discourse Relation,简称显式关系)与隐式篇章句间关系(Implicit Discourse Relation,简称隐式关系)两类。其中显式关系包含篇章关联词,如例1所示,篇章关联词“因为”指示因果类型的关系实例;隐式关系缺少显式关联词,需要根据上下文推测语义类型,如例2所示。
例1:因为我是你爸爸,我愿意为你做所有一切。(显式因果关系)
例2:他生病了,今天没有来上课。(隐式因果关系)
已有篇章句间关系识别研究主要针对英文[7],印度语[8]、土耳其语[9]和阿拉伯语[10]。虽然已有一些面向中文的研究[11-13],但主要集中在分析和语料标注,对关系识别研究不足;另外,已有研究大都直接使用了英文关系类型体系,忽略了中文本身的特点。
本文对中文篇章句间关系识别进行了探索,包括显式关系识别和隐式关系识别两方面。
针对显式关系识别,我们提出一种基于关联词的识别方案,通过分析中文篇章句间关系语料获得关联词对关系类型的指示能力,并根据关联词指示规则决定显式关系的语义关系类型。针对隐式关系识别,由于缺少篇章关联词,我们主要采用机器学习方法,抽取词汇、句法和语义等特征训练分类模型,根据模型输出判定最终的关系类型。以上识别研究均采用面向中文的篇章句间关系体系,更好的适应中文特点。
实验结果显示,基于关联词的显式关系识别方法取得了非常好的效果,取得了90%左右的识别准确率,F值达到80%;此外,我们的隐式关系识别方法也取得了较好的效果。文章内容组织如下:第2节介绍相关工作;第3节介绍显式关系识别方法,给出实验结果与分析;第4节介绍隐式关系特征、识别方法及实验结果;第5节分给出结论。
2 相关工作
篇章句间关系体系及语料:作为有指导方法的基础,英文中已经出现一些篇章句间关系语料[14-16]。这些语料采用不同的关系类型体系[14-17]描述文本单元之间的语义关系。典型的篇章句间关系语料包括以下两种:基于RST理论[17]的修辞结构理论树库(Rhetorical Structure Theory Discourse Treebank)[15]和基于PDTB体系的宾州篇章树库(Penn Discourse Tree Bank)[16],它们采用不同的关系类型体系和标注标准[18]。目前已有的语料和标注理论关注英语、印度语[8]、土耳其语[9]和阿拉伯语[10]。Xue[11]、Zhou和 Xue[12]、Huang 和 Chen[13]在中文上做了部分分析工作,不过这些研究直接将英文关系类型体系平移到中文,忽略了中文本身的特点。本文采用了Zhang在2012年提出的面向中文的篇章句间关系类型体系[19],更好的适应中文问题。
显式篇章句间关系识别:显式篇章句间关系通常由篇章关联词作为指示,Pitler et al.[7]使用无指导方法,仅仅利用关联词的统计特征识别显式篇章句间关系类型,取得了较好的效果,证明关联词对显式关系识别的重要性。除无指导方法之外,有指导模型也被用于显式关系识别,Pitler et al.[20]使用关联词相关的标准句法特征帮助提高显式关系识别性能;Wellner和Pustejovsky[21]采用有指导方法识别篇章句间关系元素范围;Elwell和 Baldridge[22]使用关联词排序器识别关系元素范围。本文提出基于中文关联词统计信息的识别方案探索显式关系识别,并且取得比较好的效果。
隐式篇章句间关系识别:隐式篇章句间关系通常存在于相邻句子之间,同时缺少关联词。类似于显式关系识别,隐式关系识别的相关研究最早出现在英文中,主要关注词汇特征,例如,词汇之间的依存关系[23-24]、词汇的语义类别[20]和关联词预测[25]。
由于隐式关系识别不同于显式关系[26],除了词汇特征之外,一些额外信息被逐渐引入,例如,句法限制[20,27]、核函数[28]、实体特征[29]以及事件配对特征[30]。这些研究提高了隐式关系识别效果,但到目前为止,隐式关系识别效果依然不佳,而且缺少面向中文的隐式关系识别研究。本文提出基于中文篇章句间关系体系的隐式关系识别模型,通过引入词汇、句法和语义特征识别隐式篇章句间关系。
3 显式篇章句间关系识别
显式关系的具体类型通常由关联词标识,如例3、例4所示。
例3:如果大家都同意这个方案,咱们就按照它来执行;(条件关系)
例4:因为大家都同意这个方案,咱们就按照它来执行;(因果关系)
例3、例4中,除关联词外的句子成分完全一
在显式关系识别中,关联词往往作为关系类型的指示标志出现。本文提出基于关联词的中文显式关系识别模型,利用关联词规则识别显式关系。
3.1 基于关联词的识别方案
致,但不同的关联词使得两个句子具有不同的语义和关系类型。可以推测:关联词标识了具体关系类型。基于这种想法,我们提出了基于关联词的显式篇章句间关系识别方案。据我们了解,这是首个利用中文篇章关联词识别显式关系类型的研究工作。
3.1.1 识别方案
我们将中文篇章句间关系语料分为两部分:Set 1包含996篇文本,用于抽取篇章关联词和对应的关系类型;Set 2包含100篇文本,用于测试识别方案。首先,我们从Set 1中抽取所有的篇章关联词和相应的关系类型;之后采用极大似然估计计算关联词对各关系类型的指示能力,获得“关联词—关系类型”矩阵:其中横轴对应某一篇章关联词,纵轴对应某一具体关系类型。具体的计算方法如式(1)所示。

其中ci对应某一关联词;sj表示待计算的关系类型;S是所有关系类型的集合。
对Set 2中的每一个测试实例,我们首先抽取篇章关联词;随后查找“关联词—关系类型”矩阵,获得该关联词对各关系类型的指示能力,从中选取最大值;并将该类型作为测试实例的最终标签。
3.2 实验设置
3.2.1 类型体系及语料获取
为了支持关联词分析和后续的有指导识别方法,我们采用Zhang[19]提出的中文篇章句间关系体系,我们从 OntoNotes 4.0[31]中随机筛选出1 096篇文本并进行了人工标注。在这份语料中,三名标注人员独立标注了显式关系和隐式关系。为了验证标注质量,检验标注一致性,我们计算了用于统计多类、多标注人员标注一致性的Fleiss Kappa指标[32]。
在最终的计算结果中,我们获得了66.52%的Fleiss’Kappa值,根据Fleiss’Kappa指标的性能分布区间,该数值反映了较好的标注一致性;此外,该结果包括显式关系和隐式关系在所有类别上的标注一致性,如果单独计算显式关系的标注一致性,我们会获得更好的结果。据我们所知,这是第一份中文篇章句间关系语料。
3.2.2 实验结果
训练语料中共标记出1 273个不同的篇章关联词,利用这1 273个关联词构成“关联词-关系类型”矩阵,并根据该矩阵对测试实例进行分类。对每一个测试实例,我们抽取相应的篇章关联词,之后检索矩阵,找到概率最大的关系类别作为最终结果。
我们在中文篇章句间关系体系[19]的六个顶层类别进行实验,包括“时序关系”、“因果关系”、“条件关系”、“比较关系”、“扩展关系”、“并列关系”,采用标准P、R、F进行评价,结果如表1所示。

表1 基于关联词的显式关系识别方法实验结果
分析表1,我们在“因果关系”、“条件关系”、“比较关系”三类获得了非常好的效果:准确率均高于0.96,F值均高于0.91。效果最好的“条件关系”精确率达到0.989 0,召回率为0.904 5,F值则是0.944 9。这意味着绝大多数情况下,“条件关系”对应的篇章关联词(例如,如果)都是无歧义的;一旦这些关联词出现,我们可以以非常高的概率将该关系实例判定为条件关系。类似的情况同样存在于 “因果关系”和“比较关系”中。
“时序关系”的实验结果略有不同,我们获得了较高的准确率(0.951 2),但召回率较低(0.715 6)。高准确率说明“时序关系”对应的篇章关联词歧义性较小,低召回率说明统计信息的覆盖率较差。对于“扩展关系”和“并列关系”情况则比较复杂。在这两类中,准确率和召回率都相对较低,这意味着除了覆盖率问题外,两类关系对应的篇章关联词歧义性也比较高。对于歧义问题,很难单纯通过语料扩充或分析解决,需要后续工作的更多关注。
总的来说,基于关联词的识别方案在各个类别上的平均表现较好。但是,最高的F值(0.944 9)和最低的F值(0.563 8)之间差距较大,说明不同的关系类型之间差异非常明显,这提示我们:不同的关系类型适合不同的处理方法。
3.2.3 错误分析与讨论
进一步分析实验结果,我们发现,大部分篇章关联词歧义较小;识别错误主要由少部分高歧义导致。这些关联词种类较少,但常用关联词较多(例如,而)。图1描述出现次数Top 10的篇章关联词在各关系类型上的分布情况:柱状图的不同颜色代表关联词对应的关系类型;不同的高度代表对应关系类型所占的比例;同一关联词对应的关系类型越少、类型越集中,该词的歧义性越小。从图中可知,大部分关联词(例如,因为)的歧义性较小,90%以上指示同一关系类型,但同时存在部分高歧义关联词。

图1 Top 10关联词的关系类型分布情况
以关联词“而”为例,它对应的关系类型分布情况包括以下几类:
(1)48.6% 对应“扩展关系”;
(2)41.8% 对应“比较关系”;
(3)7.6% 对应“并列关系”;
(4)2% 对应“因果关系”。
根据3.1.1的计算公式,“扩展关系”对应的得分最高。在分类过程中,所有由“而”标识的篇章句间关系实例都被分为“扩展关系”类别。对于48.6%的实例而言,我们获得了正确结果;然而对于剩余的51.4%,则发生了分类错误。实验分析发现,大部分分类错误都和该类关联词有关。这提示我们对于歧义性大,出现次数较多的关联词,需要特殊的处理方案。
4 隐式篇章句间关系识别
隐式篇章句间关系缺少篇章关联词,没有明显的语义类型标志,需要人类推理才能判断关系的存在和具体类型。这使得隐式篇章句间关系具有不同于显式关系的分布特点。
4.1 隐式关系分析
在很多情况下,关联词不仅仅起衔接作用,还会影响关系类型的分布,如例5、例6所示。
例5:如果你身体还没恢复,就先不用来上班了。(条件关系)
例6:你身体还没恢复,先不用来上班了。(因果关系)
例5首先描述某一假设条件,随后说明假设成立时的结果,属于“条件关系”;例6首先描述某一事实,随后指出事实引发的结果,属于“因果关系”。除关联词“如果……就……”之外两个例句内容完全相同,但却具有完全不同的语义类型。换言之,对某些关系类型来说(例如,条件关系),如果删除篇章句间关系关联词,句子语义会发生翻转。这种现象使得对应类型的隐式关系实例大大减少,形成和显式关系完全不同的分布特征。图2描述了隐式关系和显式关系在中文篇章句间关系体系[19]中六个顶层类别上的分布情况,其中图2(a)为显式关系分布图,图2(b)为隐式关系分布图。
分析图2可知,相较于显式关系,隐式关系的分布非常不均衡,其中“扩展关系”的比例大大增加,占到了总数的60.37%;而“条件关系”、“时序关系”、“比较关系”的数量则大大压缩,其中“条件关系”和“时序关系”分别只占0.72%和2.57%;只有“并列关系”和“因果关系”比例相对稳定。
分析原因,对“条件关系”和“时序关系”而言,由于关联词的省略导致了语义翻转,使得对应类型很少出现在隐式关系中,而“扩展关系”则非常适合用隐式关系来表达,这导致了图2中分布现象的出现。该特点提示我们,在隐式关系识别中,不同关系类型具有不同的分布特性,适合不同的识别方法。考虑到隐式关系中“条件关系”和“时序关系”数量极少,我们主要识别“扩展关系”、“因果关系”、“比较关系”、“并列关系”四类。

图2 显式/隐式关系类型分布图
4.2 基于有指导方法的隐式关系识别模型
根据以上的分析,对隐式关系识别主要集中在“扩展关系”、“因果关系”、“比较关系”、“并列关系”四类。我们抽取了词汇、句法、语义等多层次的特征,采用最大熵和SVM两类学习方法训练四元分类模型,根据模型输出判定隐式篇章句间关系类型。
4.2.1 特征集合
核心动词:作为句子的主要成分,动词往往在语义表达中起很重要的作用,动词之间的关系常常反映了句子间的语义关系。如例7所示。
例7:塔利班10日晚袭击了阿富汗北部一个村落,导致18人丧生。(因果关系)
上例中,“袭击—丧生”之间存在因果联系,同时也指示了两个分句之间的因果关系。通过挖掘动词之间的搭配特性,有助于识别篇章句间关系类型。这两词在依存句法分析结果中均作为“SBV(主谓关系)”的谓语动词出现,因此我们利用依存句法分析找到前后分句中的“SBV”关系,抽取其中的谓语动词;同时为了避免稀疏,我们将两个谓语动词在同义词词林中泛化至第三层,并将泛化结果配对构成核心动词特征。
极性特征:不同的极性信息常常指示特定的篇章句间关系类型,如例8所示。
例8:他很喜欢 苹果公司的产品,遗憾的是价格太高了。(转折关系)
例8中“喜欢”指示“Positive”的极性信息;“价格太高”指示“Negative”的极性信息,前后分句的极性信息相反,指示该实例属于“转折关系”。基于这种现象,我们引入了篇章单元的极性特征,采用极性词匹配的方法判定篇章单元极性,并作为特征使用。
依存句法特征:篇章单元的句法结构中,最核心的关系包括“SBV(主谓)”和“VOB(动宾)”两类,它们描述了文本单元的主要信息。本文将两个篇章单元中的“SBV”和“VOB”关系抽取出来,并将对应词汇在同义词词林中泛化至第三层,作为特征使用。
Unigram(句首):在中文里,句首词语通常起承上启下的作用,对篇章句间关系类型具有一定的指示作用。本文分别抽取两个篇章单元中的第一个词,作为识别特征使用。
Bigram(句首):中文里承上启下的可以是单个词,也可以是双词或短语。因此除Unigram特征之外,本文还抽取两个篇章单元中的前两个词,作为识别特征使用。
4.3 实验结果
我们仍然采用3.2.1中提到的中文篇章句间关系语料库进行实验,该语料库包含1 096篇文本,手工标注了显式篇章句间关系和隐式篇章句间关系两类信息。我们将其中996篇作为训练语料,另外100篇作为测试语料,抽取前文提出的词汇、句法、语义等特征,分别训练最大熵和SVM两种模型进行分类。我们在中文篇章句间关系体系的四个顶层类别进行分类,包括:“扩展关系”、“因果关系”、“比较关系”、“并列关系”,结果如表2所示。
分析表2,除“扩展关系”外,其他类型存在高准确率、低召回率的特性。以最大熵模型下的“因果关系”为例,识别准确率达到0.687 5,召回率却只有0.080 3。而“扩展关系”情况恰恰相反。这说明数据不均衡性使得模型倾向于将测试实例分为“扩展关系”,导致“扩展关系”类型召回率增加,准确率下降;同时使得其他类型召回率降低。系统的整体性能不佳,很大一个原因是由于低召回率导致的。这提示我们在类别分布严重不均衡的情况下,传统的统一识别思路存在很大的困难。
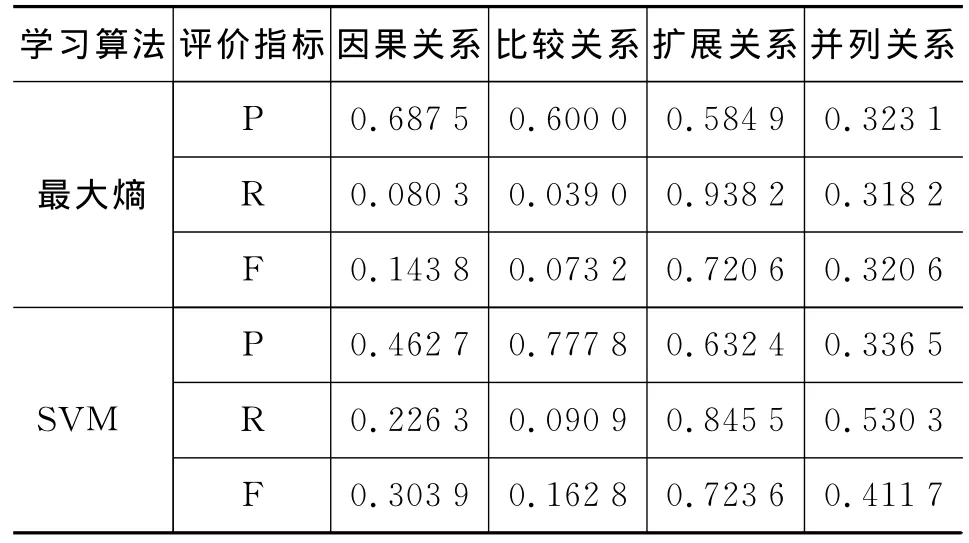
表2 隐式篇章句间关系识别结果
注意到SVM实验结果普遍高于最大熵,这主要是由于隐式关系在各类型上分布不均衡,而SVM模型对边界实例敏感,但对数据不平衡有较强的容忍度,因此取得了相对较好的效果。此外,对比前文的显式关系识别结果,我们发现“并列关系”识别效果始终不佳,这在一定程度上反映该类型的特征不明显,区分度较弱;同时考虑图1,主要的关联词歧义集中在“扩展关系”和“并列关系”,说明这两个类别特征接近。从语义体系定义上来说,是否有必要将“扩展关系”和“并列关系”区分开来,是值得考虑的一个问题。
5 结论与展望
本文首次探索面向中文的篇章句间关系识别任务,尝试了显式篇章句间关系识别和隐式篇章句间关系识别两方面研究。对于显式篇章句间关系识别,我们首次提出基于篇章关联词的显式关系识别方法,在关联词统计的基础上识别关系类型,取得了非常好的效果。对于隐式篇章句间关系识别,我们首先分析了隐式关系和显式关系在类型分布上的差别,指出隐式关系的特点,并在识别过程中进行了针对性处理;随后我们提出词汇、句法、语法等一系列特征,采用最大熵和SVM两种方案尝试了隐式篇章句间关系识别。本文的分析和实验结果为后续的工作提供了参考,推动了中文篇章分析研究,尤其是篇章句间关系分析的进一步发展。
[1]D Marcu.The rhetorical parsing of unrestricted texts:A surface-based approach[J].Computational Linguistics,2000,26(3):395-448.
[2]R Girju.Automatic detection of causal relations for question answering[C]//Proceedings of the ACL 2003 workshop on multilingual summarization and question answering.2003,12:76-83.
[3]S Somasundaran,J Wiebe,J Ruppenhofer.Discourselevel opinion interpretation[C]//Proceedings of Coling 2008.
[4]Zhou L,Li B,Gao W,et al.Unsupervised Discovery of Discourse Relations for Eliminating Intra-sentence Polarity Ambiguities[C]//Proceedings of the EMNLP 2011(Oral presentation),Edinburgh,Scotland,July:27-31.
[5]E Pitler,A Nenkova.Revisiting readability:A unified framework for predicting text quality[C]//Proceedings of EMNLP 2008:186-195.
[6]Ziheng Lin,Hwee Tou NG,Min-Yen Kan.Automatically Evaluating Text Coherence Using Discourse Relations.[C]//Proceedings of ACL-HLT,2011:997-1006.
[7]E Pitler,M Raghupathy,H Mehta,et al.Easily identifiable discourse relations[C]//Proceedings of COLING 08.
[8]Rashmi Prasad,Samar Husain,Dipti Sharma,et al.Towards an annotated corpus of discourse relations in Hindi[C]//Proceedings of the IJCNLP 2008,Hyderabad,India,2008.
[9]Deniz Zeyrek,Bonnie Webber.A Discourse Resource for Turkish:Annotating Discourse Connectives in theMETU Corpus[C]//Proceedings of IJCNLP-2008.Hyderabad,India,2008.
[10]A AlSaif,K Markert.The leeds arabic discourse treebank:Annotating discourse connectives for arabic[C]//Proceedings of LREC 2010.
[11]Xue Nianwen.Annotating discourse connectives in the Chinese Treebank[C]//Proceedings of the ACL Workshop in Frontiers in Annotation II.2005.
[12]Hen-Hsen Huang, Hsin-Hsi Chen.Chinese Discourse Relation Recognition[C]//Proceedings of IJCNLP 2011:1442-1446.
[13]Yuping Zhou,Nianwen Xue.PDTB-style Discourse Annotation of Chinese Text[C]//Proceedings of ACL 2012.
[14]J.R.Hobbs.On the coherence and structure of dis-course[M].CSLI,1985:37-85.
[15]Carlson L,Marcu D,Okurowski ME.Building a discourse-tagged corpus in the framework of rhetorical structure theory[M].Springer Netherlands,2003:85-112.
[16]R Prasad,N Dinesh,A Lee,et al.The Penn discourse treebank 2.0[C]//Proceedings of LREC 2008.
[17]William Mann,Sandra Thompson.Rhetorical structure theory:Toward a functional theory of text organization[J].Text,1988,8(3):243-281.
[18]A AlSaif,K Markert.The leeds arabic dis-course treebank:Annotating discourse connectives for arabic[C]//Proceedings of LREC 2010.
[19]张牧宇,秦兵,刘挺.中文篇章级句间语义关系体系及标注[C]//Proceedings of CCIR 2012.
[20]Pitler E,Louis A,Nenkova A.Automatic Sense Predication for Implicit Discourse Relations in Text[C]//Proceedings of ACL-IJCNLP 2009.
[21]Ben Wellner,James Pustejovsky.Automati-cally identifying the arguments of discourse connec tives[C]//Proceedings of EMNLP-CoNLL 2007,Prague,Czech Republic.
[22]R Elwell,J Baldridge.Discourse connective argument identification with connective specific rankers[C]//Proceedings of the International Conference on Semantic Computing.2008.
[23]D Marcu,A Echihabi.An unsupervised approach to recognizing discourse relations[C]//Proceedings of ACL 2001:368-375.
[24]S Blair-Goldensohn,K R McKeown,O C Rambow.Building and Refining Rhetorical-Semantic Relation Models[C]//Proceedings of NAACL HLT,2007:428-435.
[25]Z Zhou,Y Xu,Z Niu,et al.Predicting discourse connectives for implicit discourse relation recognition[C]//Proceedings of Coling 2010:1507-1514.
[26]C Sporleder,A Lascarides.Using automatically labelled examples to classify rhetorical relations:an assessment[J].NLE 2008:14(3).
[27]Lin Z,Kan M,Ng H.Recognizing Implicit Discourse Relations in the Penn Discourse Tree-bank[C]//Proceedings of EMNLP 2009,Singapore,August.
[28]W Wang,J Su,C Tan.Kernel-based discourse relation recognition with temporal ordering information[C]//Proceedings of ACL 2010:710-719.
[29]A Louis,A Nenkova.Creating local coherence:An empirical assessment[C]//Proceedings of NAACL 2010.
[30]C Chiarcos.Towards the Unsupervised Acquisition of Discourse Relations[C]//Proceedings of ACL 2012.
[31]Eduard Hovy,Mitchell Marcus,Martha Palmer,et al.Ontonotes:The 90%solution[C]//Proceedings of the Human Language Technology Conference of the NAACL,Companion Volume:Short Papers,2012:57-60.
[32]Fleiss,J.L.Measuring nominal scale agreement among many raters[J].Psychological Bulletin,1971,76(5):378-382.
猜你喜欢
疯狂英语·新阅版(2022年7期)2022-07-07
疯狂英语·新悦读(2022年7期)2022-07-06
通信技术(2021年12期)2022-01-25
唐山学院学报(2021年4期)2021-11-20
南大法学(2021年6期)2021-04-19
高中生·天天向上(2018年7期)2018-07-23
作文周刊·小学四年级版(2017年35期)2017-10-18
作文周刊·小学三年级版(2017年34期)2017-10-17
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
