
中文专利文献术语抽取
2013-09-08 10:18施水才吕学强
计算机工程与设计 2013年6期
徐 川,施水才,2,房 祥,2,吕学强,2
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京100101;2.北京拓尔思信息技术股份有限公司,北京100101)
0 引 言
专利文献是科技信息的载体,集中体现了科学技术的发展水平,有效利用专利可以提高国家和企业的发展速度。快速找出专利文献中相应的技术信息是有效利用专利文献的前提。因此,研究专利文献术语的抽取技术越来越受到研究者们的关注,专利文献中的术语体现和承载了专利文献的技术信息。同时,通过所提取的专利文献术语,可以构建专利领域叙词表,也可以进一步对专利文献进行分类,识别不同专利文献之间的相互关系。
目前,国内外相关学者对于术语提取做了很多研究。主要是基于规则和统计的方法。文献 [1-3]中都提到采用条件随机场的方式抽取术语,文献 [4]提出隐马尔科夫模型的中文泛术语识别和提取,虽然这两种方法抽取正确率和召回率较高,但都需要人工进行标注,人工标注的质量决定了术语抽取的质量。文献 [5,6]介绍采用互信息的方式抽取术语,但当遇到常用搭配但非术语时,并未做相应的处理。文献 [7]采用分隔符的方法进行抽取,该方法需要大量已知的术语进行分隔符抽取,而且只能抽取与分隔符相邻的术语。文献 [8]提出采用术语部件库的方法抽取术语,对于不包含已知的部件库的术语,该方法无法处理。文献 [9-10]在术语抽取的过程中都用到了TFIDF算法,这个算法对于提取单篇文献中的术语不适用。文献[11]采用正则表达式抽取术语,对于不符合正则表达式的术语将无法抽取。文献 [12]采用混合策略的方式抽取术语,但在抽取的过程中需要大量的空间。
针对以上方法存在的不足,本文提出基于字符串之间的边界结合度、字符串之间的串边结合度同双字词性过滤方法相融合抽取中文专利术语的方法。
1 专利文献中术语的特点
定义1 术语表示某一学科领域内概念或关系的词语。
1.1 术语构成的特点
(1)中文术语一般是由名词、动词和形容词等词性组合而成,并且中文术语的词性组合中,术语一般都是以名词性的字符串作为结尾。如:“同步电机/n转子/n”、“启动/v模块/n”、“最小/a均方/n”。
(2)术语长度的特点。术语一般由2-6个字组成。
(3)在专利文献中,专利作者使用的专业术语和自组术语所占比例较多,采用现有分词工具对专利文献进行分词结果不会很好,文献中很多的专业术语和专利作者使用的自组术语将不能被识别。如:
本/rz发明/un所/usuo提出/v转向/un盘/qv机电式/n助力器/un最/d接近/un的/ude1现有/vn技术/un是/vshi一种/un转向/un盘/v机电式/n助力器/un,……,/wd其中/rz的/ude1扭力/n杆/ng被/pbei设计/un为/p力矩/un传感器/un感测元件/n的/ude1形式/n,/wd输入/un轴/n和/cc输出/un轴/n与/cc转向/un盘/qv相/d联接/un,……;/wf以及/cc控制单元/un,/wd该/rz控制单元/un的/ude1输入/un端口/un与/cc力矩/un传感器/un以及/cc电动机/un转子/un位置传感器/un的/ude1输出/un端口/un相连/un接/v,……
从上可以看出,由于专利术语一般较长,并且大部分是专利作者根据自身的需要构建的自组术语,这些术语往往被现有的分词工具分成多个词。
1.2 术语上下文特点
在中文术语的构成方式中,只可能出现连续的名词词性构成的字符串,而其它词性的字符串往往不会在术语中连续出现。如 “机械程控装置”为 “机械/n程控装置/n”,“红外线酒精传感器”为 “红外线/n酒精/n传感器/n”,它们都是名词词性的字符串相组合而成的术语,而 “处理单元”为 “处理/v单元/n”, “高电位”为 “高/a电位/n”,分别是 “V+N”和 “A+N”这两种组合方式构成的术语,在 “V+N”构成方式前一般不能再加 “V”和其它非名词词性的词,在 “A+N”构成方式前不能再加 “A”和其它非名词词性的词。
2 字符串之间结合强度计算方法
术语往往是由多个有序字符串组合而成,组成术语的多个有序字符串在同一篇文献中结合强度一般较大,而不能组成术语的有序字符串之间的结合度一般较小,因此,通过计算具有前后关系的字符串之间的内部结合强度,可以作为判断有序字符串能否组合成术语的标准。
2.1 边界结合度计算方法
定义2 字符串边界,即一个字符串对应的首尾单个字。
定义3 边界结合度,在同一篇文献中,前后有序的两个字符串,字符串相邻边界之间的结合强度。
在同一篇文献中,选取出现频次在两次及以上的词或词组,记为S=S1S2,其中S1=WaWb…Wn,S2=WAWB…WN。例如,字串S= “直流电动机”,S1= “直流”,S2= “电动机”。记ic(WnWA)为字符串S1与字符串S2在对应单篇文献中的边界结合度,F (Wn)表示字Wn在对应单篇文献中出现的频次,F (WA)表示字WA在对应单篇文献中出现的频次,F (WnWA)表示字符串WnWA在对应单篇文献中出现的频次。
字符串S1与字符串S2之间的边界结合度ic(WnWA)的计算方法如式 (1)
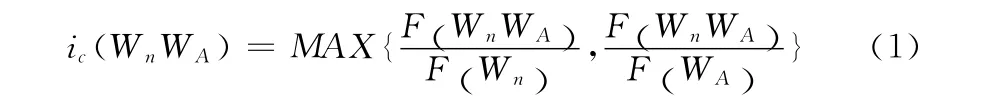
如果ic(WnWA)偏大,说明字Wn、字WA中的谋个字的出现往往与另一个字相伴出现,说明两个字结合紧密,在一定程序上反应字符串S1与字符串S2结合紧密。反之,如果ic(WnWA)偏小在一定程度上说明字符串S1与字符串S2之间的结合不紧密。
2.2 串边结合度计算方法
定义4 串边结合度,即在同一篇文献中,前后有序的两个字符串,字符串相邻边界组成的词与相邻边界的上文或下文的结合强度。
在同一篇文献中,选取出现频次在两次及以上的词或词组,记为S=S1S2,其中S1=WaWb…Wn,S2=WAWB…WN。例如,字串S= “耦合层”,S1= “耦合”,S2=“层”。记is(WnWA)为字符串S1与字符串S2在对应单篇文献中的串边结合度,F (S1)表示字符串S1在对应单篇文献中出现的频次,F (S2)表示字符串S2对应单篇文献中出现的频次,F (WnWA)表示字符串WnWA在对应单篇文献中出现的频次。
字符串S1与字符串S2之间的串边结合度is(WnWA)的计算方法如式 (2)
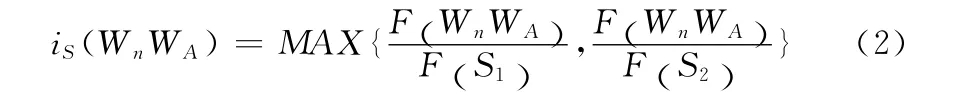
如果is(WnWA)偏大,说明字符串S1的出现后极有可能WA相续出现或者字Wn出现之后极有可能字符串S2相续出现,说明至少有一个字和另一个串结合紧密,因此,在一定程序上反应字符串S1与字符串S2结合紧密。反之,如果is(WnWA)偏小在一定程度上说明字符串S1与字符串S2结合不紧密。
3 术语双字词性过滤法
通过计算字符串之间的结合度,能够找出字符串间结合强的有序字符串,但对于常用来修饰或限定同一术语的字符串与术语之间的结合度也比较强,由于这些字符串往往是非名词词性的串,并且这些字符串的长度一般为2,因此,本文提出术语双字词性过滤的方法对计算结果进行修正,提高术语提取的准确性。
根据构成术语的词性特点和本文提出的正向双字切分和逆向双字切分的方法。本文实现术语双字词性过滤法如下:
步骤1 对于长度在3及3以上的字符串S=W1W2…Wn采用正向双字切分,经过切分S=S1S2…St,其中t=[n/2],S1=W1W2,S2=W3W4…,当n为偶数时St=Wn-1Wn,当n为奇数时St=Wn。如 “数字逻辑单元”,它经正向双字切分得到 “数字”、“逻辑”、“单元”。
步骤2 判断S1的词性,若为 “n”,则认为字符串S正向合法;若字符串S1的词性为 “nr”、“nz”、“vn”、“a”、“v”、“b”中的一种的情况,字符串S2的长度为1时,则认为字符串S正向合法;若字符串S1的词性为 “nr”、“nz”、“vn”、“a”、“v”、“b”中的一种的情况,字符串S2的词性为 “n”则认为字符串S正向合法;若字符串S1的词性为 “nr”、“nz”、“vn”、“a”、“v”、“b”中的一种的情况,字符串S2在词性集合中没有对应项,则认为字符串S正向合法;如果字符串S都不满足以上任何一条,刚认为字符串S正向不合法。对于正向合法的字符串转到执行步骤4,对于正向不合法的字符串将其转到执行步骤3。
步骤3 对于给定的正向不合法的字符串S=S1S2…St,字符串S去除S1,即S’=S2…St,对于去除S1后的字符串S’,如果其长度小于3,将整个字符串抛弃,结束对整个字符串的处理,如果其长度在3及3以上将其转到步骤1执行处理。
步骤4 对于经过正向判断合法的字符串S=W1W2…Wn,将字符串S进行逆向双字切分,S=S1S2…St,其中t=BXW1,…,St=Wn-1Wn,当n为偶数时,S1=W1W2,…,St=Wn-1Wn。如 “控制器”经逆向双字切分为 “控”、“制器”。
步骤5 判断St的词性,若St的词性为 “n”或St不存在于词表中,则认为字符串S逆向合法,否则不合法。对于不合法的,将其转至步骤6。如果合法转至步骤7。
步骤6 对于给定逆向不合法的字符串S=S1S2…St,去除St,即S=S1S2…St-1。若此时字符串S的长度小于3,则将其抛弃,结束对整个字符串的处理。若此时字符串S的长度在3及3以上,将S转至步骤4进行处理。
步骤7 剩余字符串有效,结束执行。
对于候选术语字符串,经过上述步骤验证后,余下的本文认为是有效字符串。
4 实验及结果
4.1 实验步骤
文的语料采用某专利公司提供的1248篇专利文献,大小为14.4M。通过ICTCLAS对专利文献进行分词及词性标注,统计单篇文献中出现的所有词汇,并去除停用词、频次仅为1和不必要的词性如 “wky”、“wkz”、“t”所标注的字符串。
对于统计结果中存在的字符串,如S1= “信号”及S2= “分量”采用式 (3)获得的拼接结果S为 “信号分量”和 “分量信号”。在对应文献中去查找,若 “信号分量”和 “分量信号”在对应文献中出现频次大于1时就将其保留并存入对应文献的候选词集Word1中

在对应候选词集Word1的基础之上,选取Word1中的字符串作为S1,选取对应文献统计结果中出现频次在两次及以上的字符串作为S2,按式 (3)再次进行拼结。对于拼结的字符串,如果字符串在对应文献中出现的频次在两次及两次以上,则将其保留并存入对应文献的候选词集Word2中。
再次选取候选词集Word1中字符串,把其中的字符串按式 (3)进行拼结。如S1= “信号分量”及S2= “计算机信号”,对于拼结的结果字符串,如果其在对应文献中出现的频次在两次及在两次以上,则将其保留并存入候选集合Word3中。
对于候选集Word1中的字符串,采用式 (1)和式(2)计算字符串之间的结合度,对于大于指定阈值的字符串,保留在初选合法集。对于候选集Word2和候选集Word3中的字符串,如取候选集Word2中的字符串S’,S’= “计算机 信号分量”,若 “计算机 信号”和 “信号分量”都在初选合法集中,则将S’存放入初选合法集,否则将其抛弃。
对于初选合法集中的字符串,如S=S1’+S2’+S3’,如果S1’的长度大于1,则认为S首部合法;若S1’长度为1,为判断其是否合法,本文采用准确度高的 《PFR人民日报标注语料库》一月的熟语料,S1’在语料中作为词首部的概率大于其作为词尾部概率,大于其作为词中部的概率,则认为S首部合法。否则,将S1’删除,即S=S2’+S3’。如果S的长度个数小于3个字则将其抛弃,否则继续对S进行首部合法判断。
对于首部合法的候选术语字符串,采用术语双字词性过滤法对其进行修正,对于修正的结果字符串,本文中将其认定为术语。
4.2 结果及分析
本文在计算字符串之间的结合强度时都是在字符串对应的单篇文献中的基础之上进行计算。因此,本文提出单篇准确率、单篇召回率、平均召回率、平均召回率评价指标。
定义5 单篇准确率,即某单篇文献中,正确识别的术语数Nr与对应文献中识别的所有术语数Nt之比

定义6 单篇召回率,即某单篇文献中,正确识别的术语数Nr与对应文献中所有出现的术语数Na之比

定义7 平均准确率,所有统计的文献中,所有正确识别的术语数之和与所有识别数之和的比

定义8 平均召回率,所有统计的文献中,正确识别术语数之和与统计文献中术语数之和的比

本文随机选取14篇专利文献的结果进行统计分析,具体结果见表1和表2。

表1 单篇准确率与单篇召回率实验结果

表2 平均准确率与平均召回率统计结果
其中,Pa表示文献总数;Ntr表示所有文献中识别的术语总数;Ncr表示所识别的术语中正确的总数;Ntp表示文献中术语的总数。
从上统计结果可以看出本文提出的融合边界结合度、串边结合度、双字词性过滤法提取术语具有较好的效果。但也存在一定的误识别,对于错误识别为术语的字符串主要有两类。一类是由专利文献中词语之间的常用搭配引起,如 “本发明”, “实施例”, “本”和 “发”、 “施”和 “例”在文中一般连续出现,结合强度较大,导致识别错误。另一类词语是动宾结构如 “用电容”、 “用电线”, “发出信号”,在文章中出现的频次较低,而且这些动词在对应的句子中起到谓语的作用,但是在识别的过程中 “动词+名词”的结构且动词与名词结合强度较大,在本文被识别为术语,从而导致识别错误。
5 结束语
本文从组成术语的字符串之间的结合强度出发,提出了字符串之间的边界结合度、串边结合度的概念及其计算方法;同时根据组成术语字符串的词性规律,本文提出了双字词性过滤方法。在本文中,将边界结合度、串边结合度与双字词性过滤法相融合,提取专利文献中的术语。实验结果表明所采用的方法取得了较好的效果。但也存在一定的误识别,因此需要进一步改进,下一步打算结合语义分析,在对应文献中正确识别出动宾结构,提高正确率。
:
[1]LIU Bao,ZHANG Guiping,CAI Dongfeng.Technical term automatic extraction research based on statistics and rules [J].Computer Engineering and Application,2008,44 (23):147-150(in Chinese).[刘豹,张桂平,蔡东风.基于统计和规则相结合的科技术语自动抽取研究 [J].计算机工程与应用,2008,44 (23):147-150.]
[2]JIA Meiying,YANG Bingru,ZHENG Dequan,et al.Research on automatic military intelligence term extraction using CRF model[J].Computer Engineering and Application,2009,45(32):126-129 (in Chinese).[贾美英,杨炳儒,郑德权,等.采用CRF技术的军事情报术语自动抽取研究 [J].计算机工程与应用,2009,45 (32):126-129.]
[3]TANG Tao,ZHOU Qiaoli,ZHANG Guiping.Term extraction based on the combination of statistics and rules [J].Journal of Shenyang Aerospace University,2011,28 (5):71-74 (in Chinese).[唐涛,周俏丽,张桂平.统计与规则相结合的术语抽 取 [J].沈 阳 航 空 航 天 大 学 学 报,2011,28 (5):71-74.]
[4]CEN Yonghua,HAN Zhe,JI Peipei.Chinese term recognition based on hidden Markov model [J].New Technology of Library And Information Service,2008 (12):54-58 (in Chinese).[岑咏华,韩哲,季培培.基于隐马尔科夫模型的中文术语识别研究[J].情报分析与研究,2008 (12):54-58.]
[5]LIANG Yinghong,ZHANG Wenjing,ZHANG Youcheng.Term recognition based on integration of C value and mutual information [J].Computer Applications and Software,2010,24 (7):108-110 (in Chinese). [梁颖红,张文静,张有承.C值和互信息相结合的术语抽取 [J].计算机应用与软件,2010,24 (7):108-110.]
[6]CHEN Shichao,YU Bin.Method of mutual information filtration with dual-threshold for term extraction [J].Journal of Computer Applications,2011,31 (4):1070-1073 (in Chinese).[陈士超,郁滨.面向术语抽取的双阈值互信息过滤方法 [J].计算机应用,2011,31 (4):1070-1073.]
[7]LIU Li,LIU Xiaoming.Extraction of domain-specific phenomenal terms based on separator and contextual terms [J].Journal of South China University of Technology (Natural Science Edition),2009,39 (7):145-149 (in Chinese).[刘里,刘小明.基于分隔符和上下文术语的领域现象术语抽取 [J].华南理工大学学报 (自然科学版),2009,39 (7):145-149.]
[8]HE Yan,SUI Zhifang,DUAN Huiming,et al.Term mining combining term component bank [J].Computer Engineering and Application,2006 (33):4-7 (in Chinese).[何燕,穗志方,段慧明,等.一种结合术语部件库的术语提取方法 [J].计算机工程与应用,2006 (33):4-7.]
[9]ZHAI Dufen,LIU Baisong.Automatic domain-specific term extraction in administrative-domain ontology [J].New Technology of Library and Information Service,2010,191 (4):59-65(in Chinese).[翟笃风,刘柏嵩.政务领域本体术语的自动抽取 [J].现代图书情报技术,2010,191 (4):59-65.]
[10]GU Jun,WANG Hao.Study on term extraction on the basis of Chinese domain texts [J].New Technology of library and Information Service,2011,204 (4):29-34 (in Chinese).[谷俊,王昊.基于领域中文文本的术语抽取方法研究 [J].现代图书情报技术,2011,204 (4):29-34.]
[11]CHENG Lanlan.The study of large-scale web term-pairs extraction based on regular expressions [J].Journal of Information,2008 (11):62-68 (in Chinese).[程岚岚.基于正则表达式的大规模网页术语对抽取研究 [J].情报杂志,2008(11):62-68.]
[12]WEN Chun,WANG Xiaobin,SHI Zhaoxiang.Automatic domain-specific term extraction in Chinese domain ontology learning [J].Application Research of Computers,2009,26 (7):2652-2655 (in Chinese).[温春,王晓斌,石昭祥.中文领域本体学习中术语年自动抽取 [J].计算机应用研究,2009,26 (7):2652-2655.]
猜你喜欢
山东纺织经济(2021年5期)2021-08-13
无线互联科技(2020年11期)2020-12-01
中国外汇(2019年14期)2019-10-14
科教导刊·电子版(2016年30期)2016-12-26
南风窗(2015年15期)2015-09-10
中国信息技术教育(2015年21期)2015-09-10
汽车科技(2014年6期)2014-03-11
通信学报(2014年12期)2014-01-01
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
