
基于语料库的《红楼梦》两译本词汇特征的对比分析
2013-08-18 09:46刘露露
三峡大学学报(人文社会科学版) 2013年1期
刘露露,屈 琼
(三峡大学外国语学院,湖北宜昌 443002)
《红楼梦》是中国文学史上的一朵艺术奇葩,是我国古典小说的巅峰之作。它独特的语言美和文化美使无数的中外读者为之倾倒;其译文不仅是外国友人了解中国文化的一扇窗口,更是中西方文化相互沟通的一座桥梁。自1830年以来,各种红译本便纷纷问世。如今,最广为人知的译作要数中国翻译家杨宪益和其夫人戴乃迭翻译的The Dream of Red Mansion以及牛津大学汉学教授大卫·霍克斯和约翰·闵福德翻译的The Story of The Stone,这两部译作完整优美,各具特色。自从这两个译本出现以来,国内出现了红译本研究的热潮,译本研究的文章层出不穷。然而概括而言,红译本的研究方法长期以来却比较单一:大多数语言学者或翻译学者从译文中选取例句,采用比较——分析——结论的模式进行研究,这种研究方法多以译者的经验归纳为主,受研究者主观性的约束性较强,一般没有详细客观的数据分析或实验设计,因而得出的结论主观色彩也比较浓厚。这种单一的研究方法已经达到了饱和的状态,需要引进新的研究方法进行突破,而近年来语料库研究方法的引入恰好满足了这一需求,语料库通过使翻译研究数据化、客观化,弥补了以经验为主的研究方法的不足。
语料库语言学是20世纪六七十年代逐渐兴起的一门独立的语言研究学科。它采用多种语言检索和处理工具对发生在日常生活中的语言,即自然语言进行加工处理,力求找出语言发生的本质特征及其使用规律。它为二语习得的过程,规律及其特征的研究提供了有力的数据支持。在国外,以20世纪60年代初,在美国BROWN大学建立的BROWN数据库为标志,计算机语料库的研究开始兴起;在国内,以80年代上海交通大学杨惠中教授主持建成的JDEST科技英语数据库为标志,国内的语料库研究正式进入一个新的发展阶段(杨惠中,2002)。
语料库在翻译学中的应用始于20世纪90年代,其根本思想就是运用语料库语言学的工具、技术和研究方法对大量真实的翻译现象进行描述并从所描述的翻译“自身”的语言特征中寻找翻译现象固有的规律性特征(胡显耀,2007);其理论依据是Mona Baker在1993年提出的翻译共性理论,即译文的显化、简化和范化等特征,这一理论极大地推进了语料库翻译研究的热潮。其中国外比较有名的研究学者有Kenny D,Laviosa S,Olohan M,Munday J等等,他们的研究都是围绕着翻译共性理论从各种角度发展或验证而展开的。相对而言,国内的研究起步较晚,目前国内语料库翻译研究的代表主要是胡显耀(2007)的语料库和翻译的普遍性验证研究;王克非(2004)的语料库的建库理论和翻译教学;柯飞、秦洪武(2011)的英汉双语的对比分析以及王家义(2011)的译文分析的语料库途径等。概括而言,现今语料库在翻译中的应用主要有以下三个方面:(1)平行语料库的翻译研究,即收集某种语言的原创文本和与其对应的翻译文本;(2)多语语料库的翻译研究,即收集两种或以上语言的原创文本,研究原文特征的语料库;(3)可比语料库的翻译研究,即收集某种语言的原创文本以及其他语言翻译成该语言的文本(王克非,2008)。这三种语料库相互补充相互支持,开创了翻译研究的新局面。
但是由于技术条件和经济因素的制约,目前语料库在翻译教学中的实践应用及普及度还不够充分。诚如王青在其《基于语料库的<尤利西斯>汉译词汇特征研究》(2011)一文中说道,近年来利用语料库研究翻译的论文虽然有所增加,但多数基于大型英汉对应语料库研究,即通用语料库研究为主,对某一个体创作和翻译文本进行对比的个案研究还不多见。
本文试图通过建立红译文的可比语料库,利用语料库检索工具对单个案例《红楼梦》的杨、戴译本和霍克斯译本(以下分别简称为杨译和霍译)进行分析比较,期望通过客观的数据支持和定量定性分析来发掘不同译者的用词特征,体会不同译文的独特魅力。
一、研究工具
本文采用由Watt开发的Concordance 3.0.0语料库文本处理软件来分析译文。此软件功能齐全,包括词频统计、类型符统计、标准类型符比、带语境的关键词索引(KWIC)、搭配词词频统计、词长统计等。译文自网上下载,后转化成txt格式进行concordance处理,建立一个小型的译文语料库。由于语料库的规模越大,其数据分析就越具有典型性和稳定性;《红楼梦》本身就是一部文学巨著,其译文语料库自然具有相当大的规模,因而其词汇特征分析起来比较具有稳定性和突出性。
二、《红楼梦》杨译和霍译的词汇特征对比分析
词汇是刻画人物性格的最直接的手段,《红楼梦》以其“千人千面,千面千声”的特点被誉为我国古代文学史上刻画人物性格特征最为成功的典范,其译文当然也应该具有和原文想应的表现力,因而译文词汇的选择关系着译文质量的高低。译文的词汇特征是译者文体风格的重要组成部分,是译者无意识的显示其个性的最基础的表现形式。因为不同的译者,其遣词造句的方法各有不同:有的朴实自然,给人以亲切率真的感觉;有的优雅古典,给人以庄重严肃的感觉。正是这些词汇的不同形成了译者各自不同的风格,给人独特的感受。杨戴译者和霍闵译者不论从国籍、个人修养、知识面广度或翻译侧重点、用词偏好等都不相同,这些不同之处必然会在译文中留下某种痕迹,而通过语料库统计分析的方法,我们可以捕捉这种痕迹。
在阅读时,通常读者会自然地在脑海中形成对不同译文的感性认识,虽然这种认识比较模糊但它往往令人印象深刻,极大地影响着读者对译文的评价和深入认识。通过语料库检索统计,我们能够具体再现这种感性认识。词汇特征的统计分析是基于语料库研究译文文体的最基本的功能之一,其涉及的参数较多,如类符数,形符数,类符形符比,词长统计,词频统计,词汇密度,关键词,词汇搭配等等。本文主要从以下四个方面:(1)类符形符比;(2)词汇的复杂度;(3)词汇密度;(4)动词高频词汇表来进行两译文的对比分析。
1.类符形符比
显而易见,两译文首先在篇幅上有所不同。语料库中用于统计语料容量的功能是类符和形符的统计。这里的类符,是指构成文章的非重复的词形的数目;形符是指文章的词形总数,如“An eye for an eye and a tooth for a tooth.”这句话有11个形符却只有6个类符,因为“an,eye,for,a,tooth”在句中都是重复的。一般说来,类符/形符的比值越大,说明文章的用词变化就越大,反之亦然;但当语料库的容量不同时,其得出的类符形符比就不再具有可比性。因而为了更加准确的测量文章的用词变化,我们一般采用标准化类符形符比来进行对比,即将不同的语料分成多个同等形符容量的子语料(一般以1000个形符为每等份),得出每个子语料的类符形符比,再求出平均数进行比较,这样就可以将容量这一变量纳入控制中,使得结果更科学,也更具有说服力。由于本文中所使用的两个译本容量较大,若以1000个形符/每等分来求标准比工作量很大,故此处以100000个形符/每等分来求标准化类符形符比。其结果如表1所示。
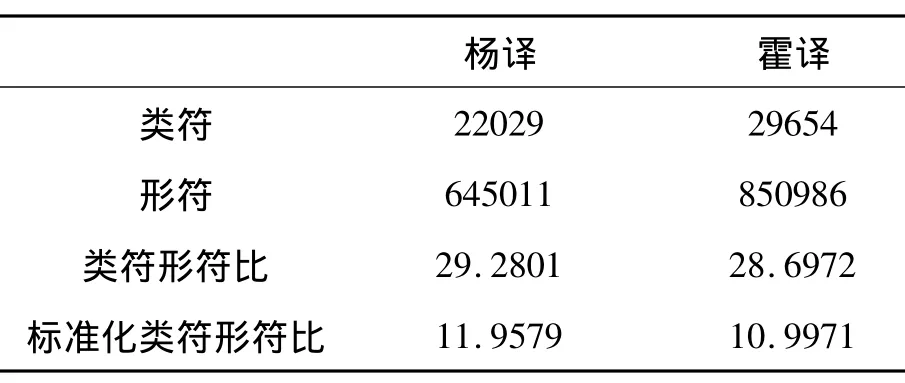
表1 两个语料的用词变化统计
由表1可知,(1)霍译的类符和形符都比杨译的都要多,这说明了霍译文的词汇比杨译文的词汇要丰富性得多,正体现了霍译作为英语母语译者在语言方面的优越性;(2)杨译的标准化类符形符比11.9579远大于霍译文的10.9971,说明杨译的用词变化要远大于霍译译文的用词变化,即在同等长度的文章中,霍译文词汇的重复数要远大于杨译文词汇的重复数。出现这种现象可能是由于两方译者的翻译目的和对原文的理解程度不同而造成的。因为就翻译目的而言,杨译侧重于向国外介绍中国的传统文化,因而在翻译时会尽量保留原文中丰富的文学知识和文化知识,从而使用新的或生僻的词汇,重复的词汇较少,而霍译主要侧重于让英语读者了解红楼梦讲述了一个怎样的故事,对原文的故事情节较侧重些,可能词汇使用的重复度较高;就对原文的理解程度而言,虽然霍克斯是大名鼎鼎的汉学家,但比起母语为汉语的翻译大家杨戴夫妇来说,其对红楼梦原文的理解程度还是会有一定的差距,因而很可能在对某句话或某个文化现象的翻译时,杨戴夫妇能够翻出其丰富的内涵而霍闵却不能。总之,虽然霍译文使用的类符形符数都比杨译文的多,但其用词变化却不如杨译文大,因而在取相同的形符时,杨译文的词汇结构要比霍译文的更具变化性。
2.词汇复杂度对比
译文的词长统计可以反映文章的用词复杂性。通常人们将由5个以上字母构成的词汇称作复杂词汇,5个或5个以下的词汇称作简单词汇。一般而言,文章使用的复杂词汇越多,其传达的意象就越隐晦,理解就越困难。我们知道英语中有2000~3000左右的最常用词汇,这些最常用词汇一般都是简单的词汇,长度多在五个字母以内。由于这类词汇在各类文章中占有较大的比例,因而在比较文章的用词复杂性时,人们通常忽略这些最常用词汇,而主要比较由五个字母以上组成的复杂词汇在文章中所占的比例。Concordance搜索软件可以显示不同语料的词长比例表,显示不同词长的词在文中所占的比例以及出现的数目。由于两语料容量不一,在此还是采用标准化的比较方法,即将两文本分别以100000形符为单位进行统计,得出每个长度单词的平均数来进行比较,从而大致得出两译文的用词复杂性。
从表2 可以看出,(1)杨译文中由 1,4,5,6,7 个字母组成的单词比霍译的多,尤其是4,5个字母组成的单词比霍译多出许多,而由8个字母以上组成的复杂词汇都比霍译的少,说明了相比霍译文而言,杨译文较多使用简单词汇或一般词汇来表达意思,复杂词汇的使用概率比霍译的少;霍译用词要比杨译复杂得多,阅读难度也大得多。这充分体现了霍闵译者以英语为母语的优越性。(2)统计表中复杂词汇的数量分别为:杨译24094和霍译25143;则其所占的比例分别为:24.094%和25.143%,得出霍译文的整体用词难度要稍大于杨译的难度,因而对《红楼梦》英译本感兴趣的读者可以不妨先读杨译本,再读霍译本,降低阅读难度。
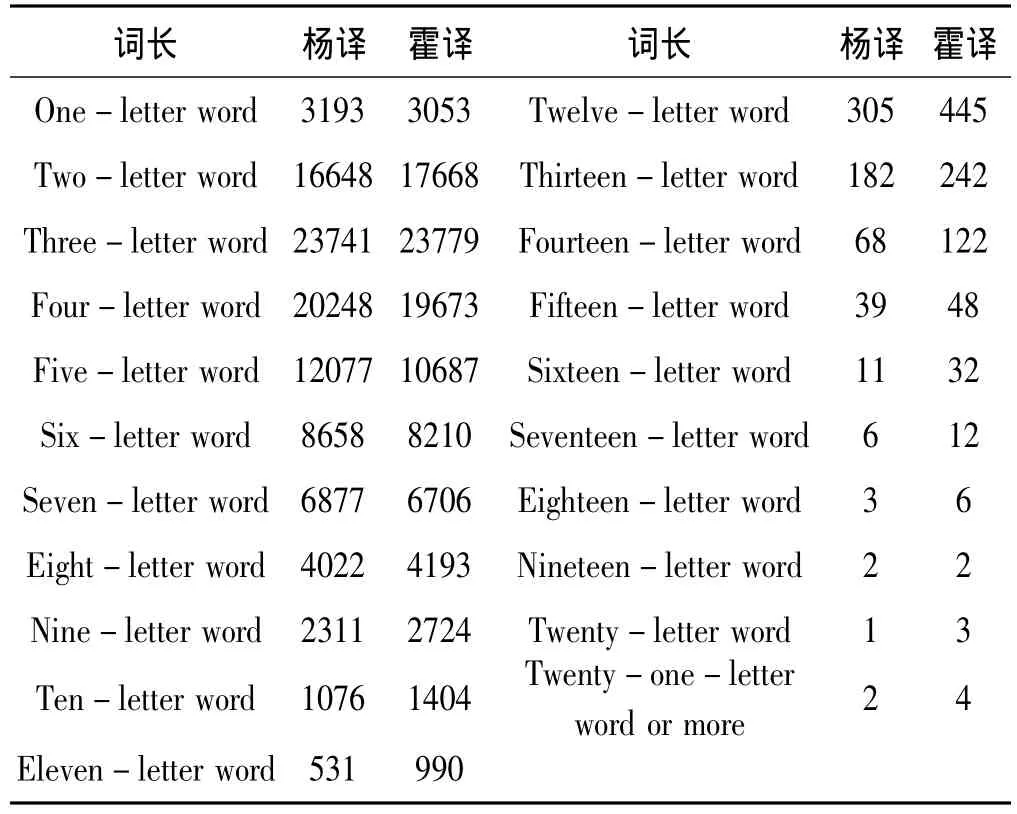
表2 两译文的词长统计
3.词汇密度
文章的词汇密度是指文中实词所占的比例。所谓实词,一般是指名词、形容词、动词和副词这类概念词。它们都具有信息负载功能,能够向读者传达出具体的有意义的信息;而与之相对的,就是虚词,主要包括介词、连词、冠词等只起着语法作用的功能词。文章的词汇密度越大,说明文章所传递的信息量越大。在理解同一原文的基础上,通过统计两译文的实词密度,我们可以分析出哪个译文传递的信息量大些。由于译文的容量较大,实词的种类多、变化多,统计起来有一定的困难,而虚词种类少,相对而言比较固定,因而我们可以通过统计虚词的数目来确定实词数,得出实词比例。如下两译文的词汇密度对比见表3。

表3 词汇密度统计
由表3可知,杨译的实词比例大于霍译的实词比例,这说明了:(1)因为虚词主要是起着连接句子的语法功能,表明了霍译文的句子结构和语法结构更加严谨,充分体现了英语重“形合”的特征,逻辑性较强(2)杨戴夫妇对原文的挖掘更深一些,传递的信息量更大些。
4.动词高频词表
译文的常用词表,尤其是动词的高频词表,不仅可以显示文章的关键词,还可以显示译文的主要时态,译者的偏爱词汇等,为读者提供许多理解文章的线索。Concordance可以给出译文的词频表,分别依照首字母、尾字母或单词出现的先后顺序排列。下面是两译文的动词高频词表,依照单词出现的频率取前10位按照降序排列,见表4。
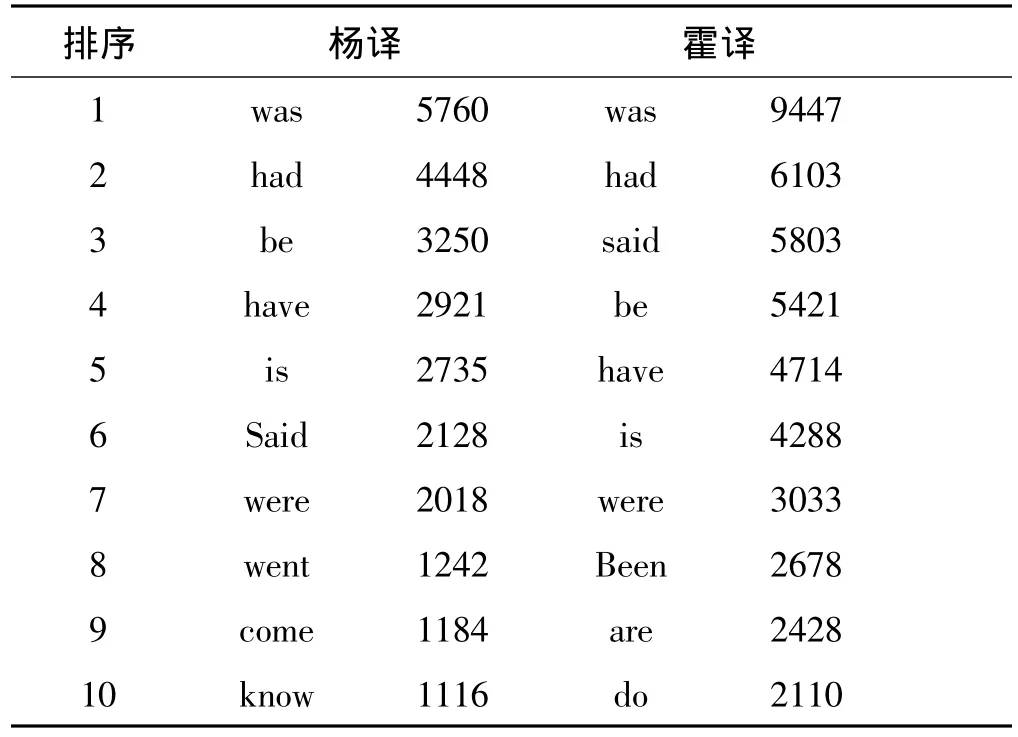
表4 高频词表
由表4可知:(1)两译文在翻译时都多用过去式,完成时和一般现在时,在时态的把握上基本没有明显差别(2)be动词(包括它的各种形态)的使用频率都较高,说明不论母语是英语还是汉语的译者,在翻译时都倾向于使用be动词及其变体作为句子的谓语动词(3)不同于霍译,杨译文中一些短暂性动词,如go,come使用频率较高,这种非延续性动词和一般现在时使用时表示一种已经确定、计划或安排好的状况;单独使用时多强调动作发生的方向、状态等等,杨译文中短暂性动词使用较多体现了杨戴夫妇对原文的心理认知与霍克斯不同:杨戴译者熟悉中国文化,对原文中所描述的文化现象持一种理解、接受的心理,因而多用这种表示计划、安排的表达;相反,霍克斯可能对原文文化持有一种怀疑的态度,不敢轻易使用。总之,译文的高频词表能够提供许多有用的信息,对译文的对比分析起着重要的作用。
三、小结
本文采用语料库的统计分析方法,对《红楼梦》两译文的用词特征,即用词变化、词长统计、词汇密度和常用词表做了具体的分析统计,其结论为:(1)译文取相同的长度时,杨译文的词汇结构要比霍译文的更具变化性(2)霍译文的整体用词难度要稍大于杨译的难度(3)霍译的句子结构和语法结构比杨译的更加严谨一些(4)霍克斯等人对原文的文化现象和文化背景仍持有一种怀疑的态度,译文对原文中文化信息的传递不如杨译。从上述结论我们可以看出,不同的文化背景对翻译实践有着非常重要的影响,它总会无时无刻且悄无声息地体现在译文中;两译文各有各的优势,然而更明显的是不足;语言和文化总是相伴而行的,翻译似乎无形中分离了这两者。因此,在以后的翻译中我们可以尝试中西合璧的途径来翻译原文,或许可以弥补双方的不足,使译文达到最佳的平衡状态。
虽然采用这种定量与定性相结合的分析方法,为分析结论提供了具体的数据依据,避免了主观臆断对分析译文的干扰,体现了语料库分析方法的优越性;但其也有不足之处,如数据过于庞大,分类统计时有些费时;有些数据不够典型等。总之,使用语料库研究译本具有客观具体性,是值得借鉴的途径。
注 释:
① Concordance 软件下载:http://www.concordancesoftware.co.uk/concordance-software-download.htm。
② 表3中所计各虚词的数目皆是按照常用虚词的数目来统计的,可能会有一定的误差。
[1]陈 耀.《红楼梦》及其英译本在中国的研究现状[J].探索与争鸣,2007(11).
[2]刘泽权,田 璐.《红楼梦》叙事标记语及其英译——基于语料库的对比分析[J].外语学刊,2009(1).
[3]卫乃兴,李文中.语料库应用研究[M].上海:上海外语教育出版社,2005.
[4]王家义.译文分析的语料库途径[J].外语学刊,2011(1).
[5]王家义.《我的童年》两英译文风格的语料库考察[J].翻译研究,2009.
[6]王克非,胡显耀.基于语料库的翻译汉语词汇特征研究[J].中国翻译,2008.
[7]王克非,黄立波.语料库翻译学十五年[J].中国外语,2008(6).
[8]王 青,秦洪武.基于语料库的《尤利西斯》汉译词汇特征研究[J].外语学刊,2011(1).
[9]谢 军.霍克斯英译《红楼梦》细节化的认知研究[D].长沙:湖南师范大学,2009.
[10]杨惠中.语料库语言学导论[M].上海:上海外语教育出版社,2002.
[11]杨 梅,白 楠.国内语料库翻译研究现状调查─基于国内学术期刊的数据分析(1993 -2009)[J].中国翻译,2009.
[12]张 夏.《红楼梦》词汇研究[D].济南:山东大学,2009.
[13]Graeme Kennedy.An Introduction to Corpus Linguistics[M].外语教学与研究出版社,2000.
[14]John Sinclair.Corpus Concordance Collocation[M].上海:上海外语教育出版社,1999.
猜你喜欢
——以“人”“彳”字部为例
福建教育学院学报(2022年1期)2022-11-23
——以满洲里学院为例
呼伦贝尔学院学报(2020年6期)2021-01-27
校园英语·上旬(2020年5期)2020-08-02
青年文学家(2019年20期)2019-08-13
校园英语·上旬(2019年1期)2019-02-26
校园英语·上旬(2017年16期)2018-01-27
辽宁教育(2017年7期)2017-03-11
北方文学·下旬(2016年6期)2016-05-14
——以霍克思英译《红楼梦》为例
上海理工大学学报(社会科学版)(2016年1期)2016-04-04
外语教学理论与实践(2015年1期)2015-06-11
