
基于盲源分离的语音降噪研究
2013-08-10 12:46:44张小华彭首峰
湖北工业大学学报 2013年1期
张小华,彭首峰,裴 浩
(湖北工业大学电气与电子工程学院,湖北 武汉430068)
对语音背景噪声消除的研究一直是语音信号处理中的一个重要研究课题.经过各国学者的不懈努力,提出了各种语音降噪方法,这为语音降噪提供了大量的理论基础并推进其逐渐成熟.盲源分离技术是近年来发展起来的一种新的信号分离技术,它是在信号源和信道传输参数未知的条件下,仅通过传感器阵列接收到的信号去估计出源信号的过程.
目前对盲源分离的研究工作大致能够分成两类[1]:一是对瞬时混合模型的研究,在各国学者的共同努力下,对这一模型的研究已经有很多比较成熟的算法可用;二是对卷积混合模型的研究,在实际应用情况下,因为信号在传输中易受到各种干扰所导致的传输延迟等的影响,传感器所得到的信号通常不是简单的瞬时叠加,而是更接近真实信号传输的卷积等混合形式,这种模型下的信号分离目前受到更多的关注.
1 源信号卷积混合模型
麦克风采集到的真实信号是原始带噪语音信号与信道冲击响应的卷积输出.可以用一个有限脉冲响应(FIR)滤波器来描述该问题[2].设有N 个源信号S(n)= [s1(n),…,sN(n)]T,M 个麦克风采集到的观测信号为 X(n)= [x1(n),…,xM(n)]T,混合滤波器冲击响应阶数为P,则在时刻n第i个麦克风采集到的信号能够表示为
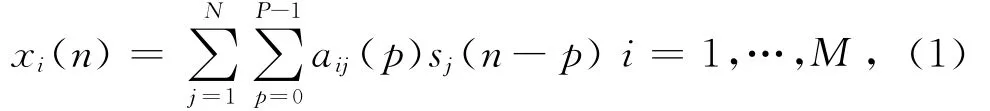
其中aij(p)表示第i个麦克风采集到的第l阶信道冲击响应系数.式(1)可以用X(n)=A*S(n)简化表示,其中A为滤波器混合矩阵,且
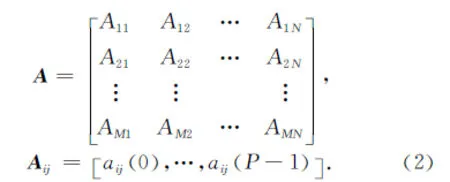
要想根据采集到的观测信号X(n)获得源信号值,就必须找到一个Q阶的分离滤波器wij,使得解卷积后输出
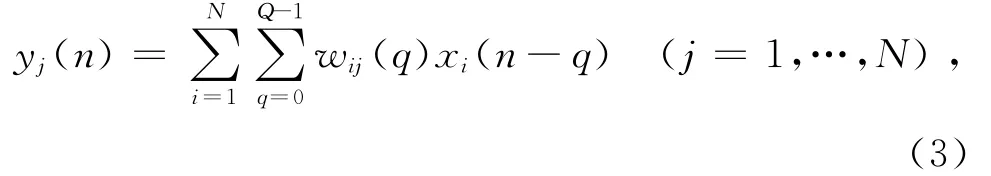
可以用Y(n)=W*X(n)简化表示.
2 分离算法
目前对卷积盲源分离问题的处理方法大多是使用短时傅里叶变换(STFT)将时域中的卷积分离问题转换成多个频域中的瞬时混合盲源分离问题[3],这样可以通过使用研究较成熟的瞬时盲源分离算法来解决分离问题.具体的做法如下.
对得到的观测数据进行长度为L的傅里叶变换:

其中ωi=2πl/L表示频率点,m表示对数据进行长度为L的傅里叶变换的段数,记利用瞬时盲源分离算法获得观测信号在频率点ωi上的分离矩阵W(ωi),使得Y(ωi)=W(ωi)X(ωi),式中其中为第m个子段中源信号的估计值的傅里叶变换.然后通过对每一段数据各频 点 上 的 值 [Y(ω0,m),Y(ω1,m),Y(ωL-1,m)](m=1,2,…,M)进行傅里叶反变换,得到每一个数据段上的时域估计值Y(m)(m=1,2,…,珨M),依次将各段时域估计值连接起来,就获得了声源信号的估计值.
由于瞬时盲源分离算法在信号分离过程中存在幅度和排序的不确定性,使得上面提到的方法在进行傅里叶反变换前需要解决排序和幅度不确定性问题.对于幅度的调整,通过采用将W(ωi)(i=0,1,…,L-1)中对应的行向量归一化,即W(ωi)←,能够取得较好的效果.对于排序的问题,Anemuller[4]等学者经研究发现,语音信号在频域中表现出同信号相邻频点之间相关性很强,但是不相同信号相邻频点的相关性较弱,这与人类声带所固有的特性有关.设y1(ωi)和y1(ωi+1)为两相邻频点的值,如果

的值大于设定的上限阈值,则说明两相邻信号具有较强的相关性,是属于同一源信号的两个频点值.反之如果小于设定的下限阈值,则认为不属于同一源信号,需要重新调整通道值顺序.一般的上限阈值取0.6,下限阈值取0.3[5].
在使用瞬时算法时,由于处理的数据是复数形式,所以必须采用能处理复数的瞬时分离算法,现有的复数算法主要有复数FastICA算法、复数infomax算法和JADE算法.这三种算法都具有较好的性能,由于本文下面仿真中使用的是JADE算法,所以下面给出该算法的主要原理和具体的算法步骤.
联合近似特征矩阵对角化(Joint Approximate Diagonalization of Eigenmatrices)是基于四阶累积量的盲源分离算法,它联合对角化下面定义的四阶协方差矩阵[6]:

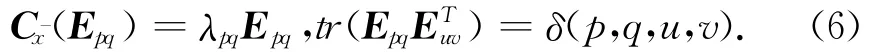
其中只有当p=q=u=v时δ(p,q,u,v)=1,其它情况取0值.λpq是每个特征矩阵Epq对应的特征值.
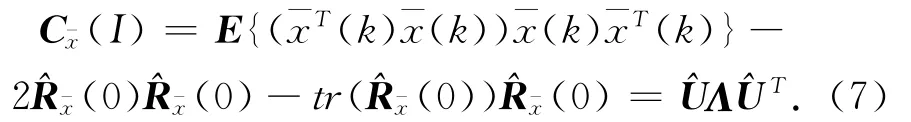
一种获得满足上面关系的特征矩阵Epq的方法是通过估计特征矩阵,产生N个四阶协方差矩阵C珔x(Ep),其中是正交阵的第p列是用来估计对角阵的正交阵.为了得到准确的对角阵,首先可以通过Ep=I的特殊四阶协方差矩阵的特征值分解粗略的估计出它的值:对N个四阶协方差矩阵C珔x(Ep)寻找正交阵U,要求它能同时使各C珔x(Ep)都尽可能对角化.一种联合对角化的方法是Givens旋转法,即为了使各Λ(Ep)=UTC珔x(Ep)U 尽可能对角化,用Λ(Ep)中非对角元素的平方和作为衡量指标,使下式的值极小:

JADE算法的具体实现步骤[7]
1)经过白化后得到预处理的数据珚x(k)=Qx(k).
2)通过Ep=I得到四阶协方差矩阵C珔x(I),并对其进行特征值分解,得到
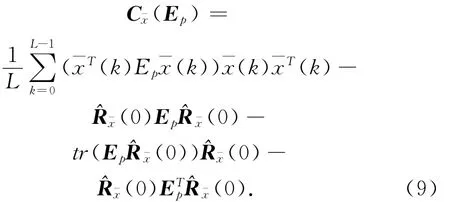
4)使用Givens旋转方法,找到一个正交矩阵U ,使得

的值小于设定的值.
3 语音降噪仿真实验
在matlab上使用语音采集程序采集了5s的带有背景噪声的语音信号,并以Wav形式文件保存,采样频率为16kHz,数据点数80 000.由于实验条件有限,将采集到的数据做简单的类似谱减法处理后作为第二路观测数据,然后将两路数据采用频域盲源分离算法进行处理,其中傅里叶变换数据长度L=256,帧移为1/2.两路观测信号和分离后的信号分别如图1、2所示.
采用matlab自带的wavplay函数将分离后的两路信号读出,用人耳听发现第一路信号基本上是背景噪声,只有少量的语音信号,第二路信号则刚好相反.这说明通过盲源分离算法基本上能够将背景噪声和语音信号分离开来,达到语音降噪的目的.为了得到更清晰的语音信号可以对分离出的信号进行小波降噪处理或谱减法降噪处理.
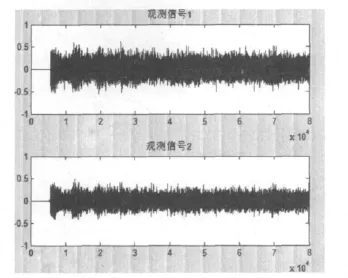
图1 两路观测信号
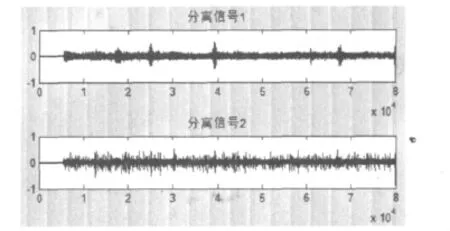
图2 两路分离信号
[1]汪 林.多通道语音信号处理中的关键技术研究[D].大连:大连理工大学图书馆,2010.
[2]张 华,冯大政,庞继勇.卷积混迭语音信号的联合块对角化盲源分离方法[J].声学学报,2009,34(2):167-174.
[3]徐 舜,陈绍荣,刘郁林.卷积混合语音的联合块对角化盲源分离算法[J].振动与冲击,2007,26(8):86-90.
[4]Anemuller J,Kollmeier B.Amplitude modulation decorrelation for convolutive blind source separation[A]// Proc.of ICA2000 [C].Helsinki:Finland,2000:215-220.
[5]姜卫东,陆佶人,张宏滔,等.基于相邻频点幅度相关的语音信号盲源分离[J].电路与系统学报,2005,10(3):1-4.
[6]李昌利.盲源分离的若干算法及应用研究[D].西安:西安电子科技大学图书馆,2010.
[7]许鹏飞.卷积混合数字通信信号的盲源分离[D].西安:西安电子科技大学图书馆,2010.
猜你喜欢
数学物理学报(2022年6期)2022-12-15 08:45:54
北京航空航天大学学报(2021年9期)2021-11-02 08:24:20
东方教育(2017年14期)2017-09-25 02:07:38
中国中西医结合皮肤性病学杂志(2016年4期)2016-07-18 10:59:54
课程教育研究·学法教法研究(2016年1期)2016-03-17 15:52:58
西南医科大学学报(2015年1期)2015-08-22 13:02:00
电测与仪表(2015年9期)2015-04-09 11:59:22
物探化探计算技术(2015年2期)2015-02-28 17:43:00
四川师范大学学报(自然科学版)(2015年3期)2015-02-28 14:07:53
海军航空大学学报(2015年4期)2015-02-27 13:45:50
