
基于自适应近邻图嵌入的局部鉴别投影算法
2013-07-25 03:38王永茂徐正光
电子与信息学报 2013年3期
王永茂 徐正光 赵 珊
①(北京科技大学自动化学院 北京 100083)
②(河南理工大学计算机科学与技术学院 焦作 454000)
1 引言
降维是高维数据压缩、可视化和分类的重要预处理手段之一。PCA(Principle Component Analysis), FDA(Fisher Discriminant Analysis)[1]是最流行的降维方法,但其本质上是线性的,不能有效描述高维数据的非线性变化。基于流形的非线性降维方法是近年来兴起的一类降维方法,等距映射(ISOMAP)[2],局部线性嵌入(Locally Linear Embedding, LLE)[3]和拉普拉斯映射(Laplacian Eigenmap, LE)[4]是其典型代表,它们通过在降维过程中保持数据的局部信息来学习非线性流形结构,但是基于流形的降维方法的一大缺陷是不能直接映射新的测试点[5],为了解决这一问题,许多学者先后提出局部保形投影(Locality Preserving Projection,LPP)[6],近邻保形嵌入(Neighborhood Preserving Embedding, NPE)[7]等基于流形的线性降维算法,它们分别为LE算法与LLE算法的线性逼近。尽管LPP, NPE在降维过程中能够保持数据的局部信息,但在降维过程中未利用数据的类别信息,是一种无监督的降维方法,而传统的FDA是一种有监督的线性降维方法,在降维过程中不能保持数据的局部信息。为此,文献[8]将LPP的基本思想引入到FDA中提出了LFDA(Local Fisher Discrimiant Analysis)算法,在人脸识别[9]、人耳识别[10]等领域取得了较好的效果。然而LFDA在处理高维数据时仍有一些不足:(1)LFDA未考虑不同类别数据间的近邻关系,相距较远的不同类别间的数据在类间离差度量时占据较大比重,以致在处理某些数据时得不到正确的最优投影方向[11];(2)为描述数据的局部信息,LFDA需要寻找数据的近邻点,同其他基于流形的降维算法一样,近邻点个数的选择对于最优的投影方向影响较大[12]。
为了解决LFDA存在的不足,本文提出了一种新的局部鉴别分析方法:基于自适应近邻图嵌入的局部鉴别投影(neighborhood graph embedding based Local Adaptive Discriminant Projection,LADP)算法,根据数据分布自适应构造描述局部信息的类内与类间近邻图,避免了近邻点个数对于投影子空间的影响,在得到的低维子空间内,使得相同类别的近邻点尽量靠近,而不同类别的近邻点尽量分离。
2 局部Fisher鉴别分析(LFDA)
2.1 通用图嵌入框架
许多降维方法可以利用通用图嵌入框架进行解释[13],其形式化描述如下:由n个样本组成的样本集记作X=[x1,x2,…,xn]D×n,样本xi是一个D维向量,li∈L={1,2,…,Nc}为样本xi的类别标号,Nc为类别总数,nl定义为第l类样本个数。线性降维是按照某种最优化标准得到一个D×d变换矩阵V,将样本集X投影到低维空间得到Y=VTX=[y1,y2,…,yn]d×n,其中yi是xi的低维投影,维数为d,且d<D。在此框架中优化准则通常可以表示为


2.2 LFDA的权值矩阵
在LFDA中,权值矩阵Ww和Wb定义为

Aij是样本xi和xj之间的一种相似性度量,xi和xj差别越小,Aij值越大,反之越小,这里用高斯函数定义Aij,即

其中Nk(xj)表示样本xj同类别的k个近邻点集合,从式(2)和式(3)可以看出,LFDA中的权值体现了鉴别信息与局部信息,与xi和xj是否同类以及是否相邻有关。
在式(3)权值矩阵的定义下,式(1)中VTX(Db-Wb)XTV对应为LFDA算法中的局部类间离差矩阵,由不同类别的所有样本点以及同类别近邻点决定,VTX(Dw-Ww)XTV对应为LFDA算法中的局部类内离差矩阵,仅由同类别的近邻点决定。
2.3 LFDA的不足
在LFDA中,最优投影方向依赖于近邻点个数k值的选择;同时在计算类间离散度时,未考虑不同类别数据之间的近邻关系,对于某些数据,LFDA得不到正确的最优投影方向,下面通过两个例子加以说明。
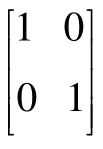
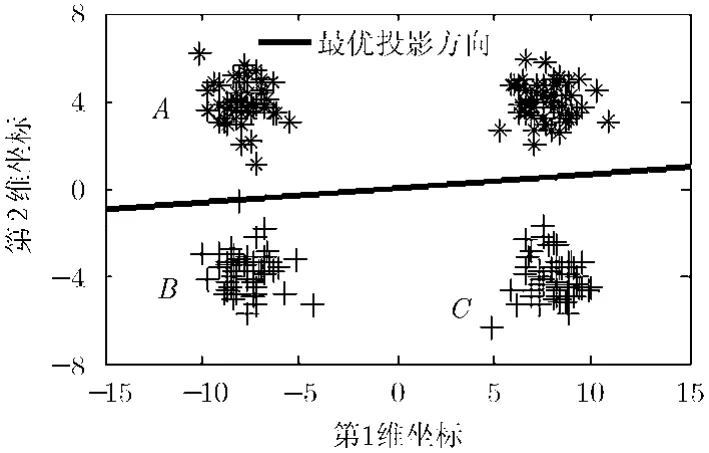
图1 人工数据 1
(1)不考虑不同类别数据之间的近邻关系对于最优的投影方向的影响 在图1中,聚类A与聚类B的距离小于聚类A与聚类C的距离,显然最优的投影方向应该为垂直方向,但LFDA在类间离差度计算中所有不同类别的数据点间的距离的系数都是相同的,均为1/n,距离越大在类间离差度所占的比重也越大,因此,在图1中,AC之间的距离占主导地位,在水平投影方向上AC之间的距离要大于在垂直方向上的投影,因此得到的最优投影方向为水平方向。相反,如果考虑不同类别数据之间的近邻关系,这时C中的数据点就不会成为A中数据点的近邻点,类间离差度仅由类间近邻点决定,这时,应该使得AB两个聚类有最大分离程度,显然在垂直方向上满足要求。因此在定义权值矩阵时需要考虑不同类别数据之间的近邻关系。

(2)近邻点个数k的选择对于最优投影方法的影响 很显然,对于图 2(a)~图 2(d)中的人工数据,最优的投影方向均为水平方向,但是数据与其距离最远的数据点之间的距离随着垂直方向上方差的增加而不断增大,因为数据点与不同类别的数据点之间的权值均相等,因此与最远端的数据点之间的距离在类间离差度的计算中占有比较大的比重,又因为在垂直方向的方差远大于水平方向上的方差,因此投影方向随着方差的增加而逐渐向垂直方向靠近,这时就需要增加类内近邻点的个数,也就是k值来抵消远端数据点在类间离差度中所占的比重,图3为对于图2(d)中的数据,投影方向随近邻点个数k的变化情况,图中的直线代表不同近邻点个数k对应的最优投影方向。
从图 3可以看出随着k值的增加,投影方向逐渐向水平方向靠近。因此近邻点个数k对于最优的投影方向有较大的影响,需要根据数据的分布自适应确定数据之间的近邻关系。
3 基于自适应近邻图嵌入的局部鉴别分析算法
基于上节提到的LFDA的不足,本文提出一种新的局部鉴别分析算法:基于自适应近邻图嵌入的局部鉴别投影算法(LADP)。LADP算法的步骤如下:
步骤 1 根据数据分布特性以及数据间的相似度自适应计算数据类内以及类间的近邻点;
步骤 2 根据数据的类内类间近邻点的个数定义局部类内与类间离差矩阵中的权值矩阵;

图2 人工数据2
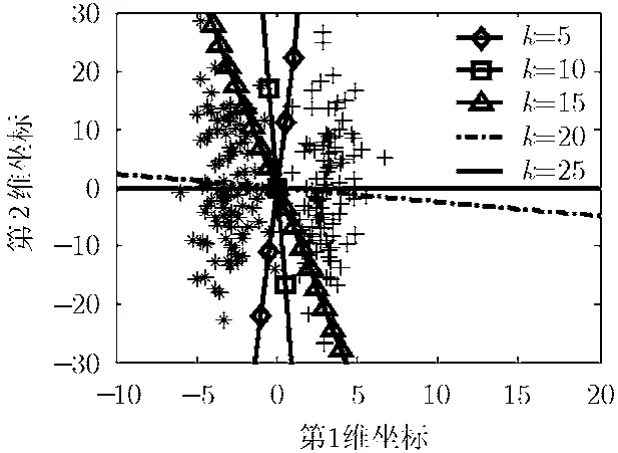
图3 LFDA在不同k值下的最优投影方向对比
步骤 3 最大化局部类间离差度最小化局部类内离差度,得到最优子空间。
3.1 自适应近邻点计算
首先根据式(4)计算样本xi与所有其他样本之间的平均相似度AS(xi)。

其中参数β取式(5)定义的所有样本之间的欧式距离的平均值。
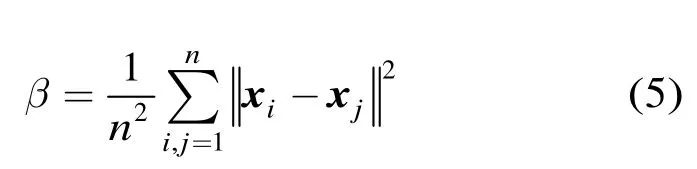
接着,根据式(6)和式(7)自适应确定xi的类内近邻点集合Nw(xi)以及xi的类间近邻点集合Nb(xi)。
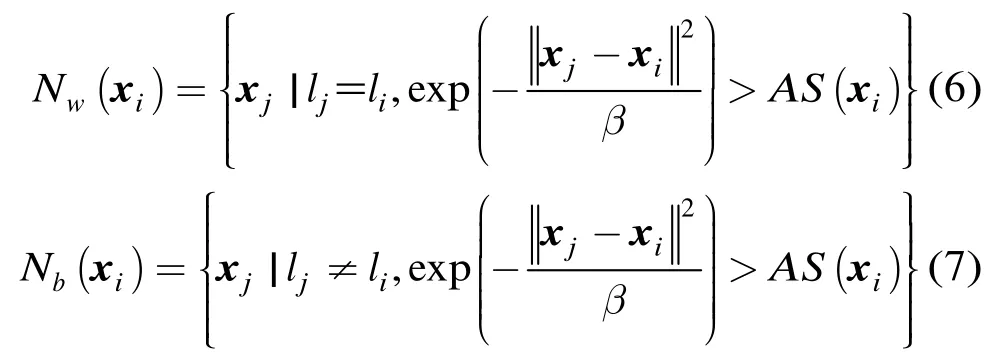
根据式(6)和式(7)的定义,Nw(xi)为相似度大于平均相似度的与xi同类别的样本集合,Nb(xi)是相似度大于平均相似度的与xi不同类别的样本集合。
3.2 权值矩阵
这里,依据样本的类内类间近邻点的个数定义式(1)中的权值矩阵Ww和Wb:

其中kw(i)为样本点xi同类别的近邻点的个数,其值为类内近邻点集合Nw(xi)中样本点的个数,kb(i)为样本点xi不同类别的近邻的个数,其值为类间近邻点集合Nb(xi)中样本点的个数。
3.3 最优嵌入
为提高算法的灵活性,与式(1)优化准则不同,在本文采用的优化准则中,类间离差度与类内离差度所占的比重不同。
最大化式(1)等价于:
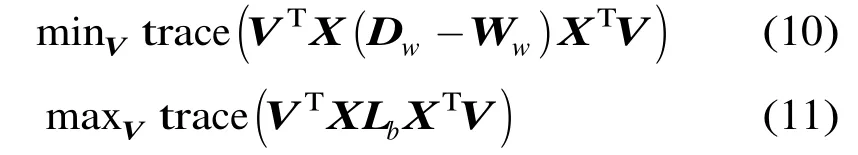
其中Lb=Db-Wb。
在约束条件VTXDwXTV=I下,最小化式(10)等价于最大化式(12):
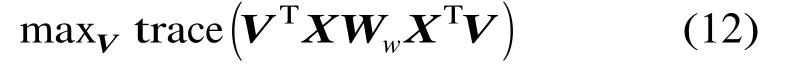
因此,由式(11)和式(12),最优化问题变为

其中0≤α≤1为调节参数,令B=αLb+(1-α)·Ww,式(13)变为
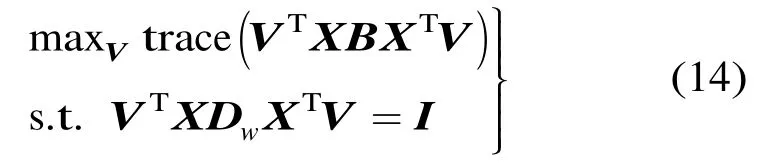
式(14)的最优化问题转换为广义特征向量的求解:

令v1,v2,…,vd为式(15)最大的d个特征值对应的特征向量,则最优的变换矩阵为V=[v1,v2,…,vd]D×d。
3.4 时间复杂度分析
LFDA与LADP算法的时间复杂度主要由两个方面决定:(1)类内类间近邻点的计算;(2)广义特征向量的求解。
在LFDA算法中,类内类间近邻点计算的时间复杂度为O(Dn2+kn2),其中O(Dn2)代表计算任意两个样本的欧式距离的时间复杂度,D为样本的维数,n为样本的个数,O(kn2)代表寻找同类别k个近邻点的时间复杂度,又有局部类内类间离差矩阵均为D×D矩阵,求解广义特征向量的时间复杂度为O(D3),可知 LFDA算法的时间复杂度为O(Dn2+kn2+D3),由于k远小于样本维数D和样本个数n,O(kn2)的变化趋势远小于O(Dn2)与O(D3),所以 LFDA算法的时间复杂度近似于O(Dn2+D3)。LADP与LFDA区别在于自适应确定类内类间近邻点,计算任意两个样本的相似度的时间复杂度为O(Dn2),得到每一个样本的平均相似度的时间复杂度为O(n2),与平均相似度进行比较确定类内和类间近邻点集合的时间复杂度为O(n2),求解广义特征向量的时间复杂度为O(D3),所以LADP算法的时间复杂度为O(Dn2+2n2+D3),由于O(2n2)的变化趋势远小于O(Dn2)与O(D3),LADP算法的时间复杂度近似于O(Dn2+D3)。因此LADP与LFDA的时间复杂度相当,仅由样本的个数n和维数D决定。
4 实验与结果
为了评估算法的性能,我们设计两类实验,实验1将LADP应用分类任务,比较LADP与经典的PCA, FDA以及LFDA等算法的分类性能;实验2通过低维特征抽取时间比较LFDA与LADP算法的运算效率。
4.1 分类识别
为了验证本文提出的LADP算法在分类识别任务中的有效性,本文在ORL人脸库,COIL20图像库以及ISOLET语音库上进行实验,比较LADP算法与 PCA[1], FDA[1], LFDA[8]等算法的分类识别性能。
4.1.1数据集介绍ORL人脸库是由英国剑桥大学建立,共有40个人,每人10张图像,共有400张人脸图像,图像的面部表情和面部细节有着不同程度的变化,人脸姿势也有相当的程度变化,比较充分地反映了同一人不同人脸图像的变化和差异,图4是ORL人脸库的部分样本。COIL20图像库由20个物体的1440幅图像组成,每一个物体旋转一周每隔5°采集一幅图像共有72幅图像,图5是COIL20图像库中的部分样本。ORL人脸库以及COIL20图像库中的图像经剪切后大小均为 32×32,用一个1024维的向量表示。ISOLET语音库是UCI机器学习数据集中的一个标准数据库,由30个人的1560个语音样本组成,采集每个人诵读26个字母的语音各 2次共 52个语音样本,每一个语音样本用一个617维的向量表示。

图4 ORL人脸数据库中的部分人脸图像

图5 COIL20图像库中的部分样本图
4.1.2调节参数α选择本节讨论 LADP算法中类内和类间离散度的调节参数α对于识别性能的影响。这里采用交叉验证方法进行调节参数α的选择。在ORL人脸库,COIL20图像库以及ISOLET语音库上分别随机选择4幅图像作为训练样本,其余所有图像作为测试样本,进行 10次重复试验,取10次的平均识别率,图6显示了在调节参数α不同取值的情况下,LADP算法的平均识别率。可以看出,调节参数α对于识别性能有较大的影响,α的值越大,识别性能越好,在后续的实验中取α=0.9。

图6 平均识别率随调节参数α的变化情况
4.1.3识别性能比较本节分别在 ORL人脸库,COIL20图像库以及ISOLET语音库对比本文提出的LADP算法与PCA, FDA, LFDA等算法的识别性能,使用最近邻分类器完成分类识别。在实验中,从每类图像中随机选取i张图像作为训练集,剩下的作为测试集,重复进行10次,共获得10对不同的训练集和测试集,用iTrain表示不同数量的训练样本数,取10次实验的平均识别率。图7~图9分别为ORL人脸库,COIL20图像库以及ISOLET语音库上的平均最高识别率。
4.1.4讨论
(1)由于实验所用的样本的维数很高,其存在的冗余信息可能影响图像的识别率,从实验结果也验证了这一点,在PCA, FDA, LFDA以及LADP等降维算法得到的低维子空间内的识别率高于在原始空间内的识别率;
(2)FDA, LFDA以及LADP的识别率高于PCA方法,这是因为FDA, LFDA以及LADP在寻找最优子空间的过程中利用了数据的鉴别信息,而PCA寻找的最优子空间其重构误差最小,没有考虑有利于分类的鉴别信息;
(3)LFDA与 LADP在降维的过程中能够保持数据的局部信息,尤其在训练样本不足的情况下,其性能要优于全局降维方法FDA;

图7 ORL人脸数据库上平均最高识别率
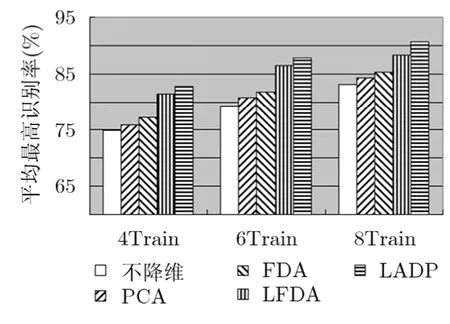
图8 COIL20图像库上的平均最高识别率
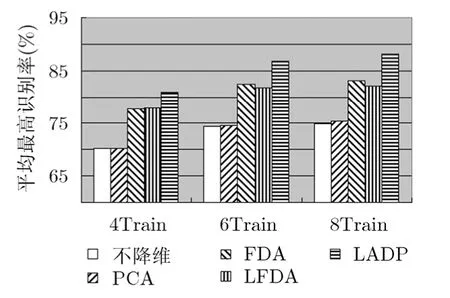
图9 ISOLET语音库上的平均最高识别率
(4)LADP的识别率是最高的,这主要取决于以下几个方面:(a)LADP充分考虑类内近邻以及类间近邻点对于分类结果的影响;(b)自适应确定类内以及类间近邻点的个数,避免了近邻点个数对于分类结构的影响;(c)在定义目标函数时,类内离差度与类间离差度所占比重不同。
4.2 低维特征抽取时间比较
本节利用低维特征抽取所花费的时间来比较LFDA与LADP算法的效率。LFDA与LADP算法采用 matlab7.0编写,在配置主频为 2.93 GHz的CPU(Intel酷睿2双核E7500)以及2 G内存的计算机上运行。在 ORL人脸库,COIL20图像库以及ISOLET语音库上分别随机选择4幅图像作为训练样本,其余所有图像作为测试样本,表1为LFDA与LADP算法进行低维特征抽取所花费时间。可以看出LFDA与LADP算法进行低维特征抽取所花费的时间相当,也就是说LADP算法在提高识别性能的同时算法的执行时间并没有增加。
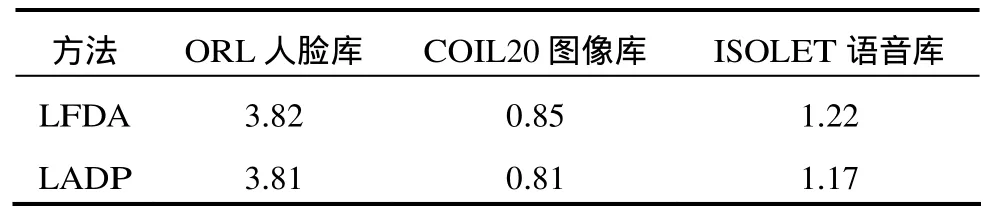
表1 低维特征抽取时间(s)
5 结束语
在分析了LFDA算法不足的基础上,本文提出了一种新的基于局部保持的鉴别分析方法:基于自适应近邻图嵌入的鉴别投影方法,自适应计算数据的近邻点集合,不仅能够很好保持流行的局部结构,同时也能够保持数据的鉴别信息,在人工数据以及标准数据库上均取得了较好的效果。LADP本质上是一种线性降维方法,在应用LADP算法时,需要将图像的2维结构转换为向量形式,这就容易出现小样本问题,基于张量表示的LADP算法是下一步研究的重点。
[1]Martinez A and Kak A. PCA versus LDA[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2001, 23(2): 228-233.
[2]Tenenbaum J, Silva V, and Langford J. A global geometric framework for nonlinear dimensionality reduction[J].Science,2000, 290(5500): 2319-2323.
[3]Roweis S and Saul L. Nonlinear dimensionality reduction by locally linear embedding[J].Science, 2000, 290(5500):2323-2326.
[4]Belkin M and Niyogi P. Laplacian eigenmaps for dimensionality reduction and data representation[J].Neural Computation, 2003, 15(6): 1373-1396.
[5]张大尉, 朱善安. 基于核邻域保持判别嵌入的人脸识别[J]. 浙江大学学报(工学版), 2011, 45(10): 1842-1847.
Zhang Da-wei and Zhu Shan-an. Face recognition based on kernel neighborhood preserving discriminant embedding[J].Journal of Zhejiang University(Engineering Science), 2011,45(10): 1842-1847.
[6]He Xiao-fei and Niyogi P. Locality preserving projections[C].Proceedings of the 16th Advances in Neural Information Processing Systems, Vancouver, 2003: 153-160.
[7]He Xiao-fei, Cai Deng, Yan Shui-cheng,et al.. Neighborhood preserving embedding[C]. Proceedings of the 10th IEEE International Conference on Computer Vision, Beijing, 2005:1208-1213.
[8]Sugiyama M. Dimensionality reduction of multimodal labeled data by local fisher discriminant analysis[J].Journal of Machine Learning Research, 2007, 8(5): 1027-1061.
[9]Huang Hong, Feng Hai-liang, and Peng Cheng-yu. Complete local Fisher discriminant analysis with Laplacian score ranking for face recognition[J].Neurocomputing, 2012, 89(7):64-77.
[10]Huang Hong, Liu Jiamin, Feng Hailiang,et al.. Ear recognition based on uncorrelated local Fisher discriminant analysis[J].Neurocomputing, 2011, 74(17): 3103-3113.
[11]谢钧, 刘剑. 一种新的局部判别投影方法[J]. 计算机学报,2011, 34(11): 2243-2250.
Xie Jun and Liu Jian. A new local discriminant projection method[J].Chinese Journal of Computers, 2011, 34(11):2243-2250.
[12]Raducanu B and Dornaika F. A supervised non-linear dimensionality reduction approach for manifold learning[J].Pattern Recognition, 2012, 45(6): 2432-2444.
[13]俞璐, 谢钧, 朱磊. 一种基于目标空间的局部判别投影方法[J].电子与信息学报, 2011, 33(10): 2390-2395.
Yu Lu, Xie Jun, and Zhu Lei. A local discriminant projection method based on objective space[J].Journal of Electronics&Information Technology, 2011, 33(10): 2390-2395.
猜你喜欢
车主之友(2022年4期)2022-08-27
无线互联科技(2020年22期)2021-01-11
弹箭与制导学报(2020年2期)2020-09-01
海峡姐妹(2019年12期)2020-01-14
中国惯性技术学报(2019年6期)2019-03-04
传感器与微系统(2018年7期)2018-08-29
自动化学报(2017年4期)2017-06-15
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
火控雷达技术(2016年1期)2016-02-06
