
一种基于ID3的计算机等级考试成绩分析方法
2013-06-07 07:32:48司马宇
遵义师范学院学报 2013年1期
曾 旭,司马宇
(1.遵义医学院 医学信息工程系,贵州 遵义 563003;2.遵义医学院 网络技术中心,贵州 遵义 563003)
计算机等级考试是经国家教育部批准,由教育部考试中心主办,面向社会,用于考察应试人员计算机应用知识与技能的计算机水平考试体系。该考试是根据不同部门应用计算机的需要、国内计算机技术的发展状况以及中国计算机教育、教学和普及的现状确定的;它以应用能力为主,划分等级,分别考核,为专业人员择业、人才流动提供其计算机应用知识与能力水平的证明。
自医疗信息化建设提出以来,医疗卫生领域传统的纸质存档办公方式已经成为阻碍该行业发展的重要因素之一。为了加快医疗信息化建设的步伐,医学院校培养拥有办公自动化操作能力的医务人员已成为不可忽视的大学本科培养目标,因此在遵义医学院的本科课程设置中专门强调了计算机等级考试的教学与考核。为了让学生有的放矢地学习和考核,遵义医学院医学信息工程系收集了相关的考核数据并利用数据挖掘技术作出了分析,分析结果为后期教学工作的开展起到了很好的指导作用。
1 数据挖掘
数据挖掘[1]是从大量数据中发现有趣模式,其中数据可以存放在数据库、数据仓库或其他信息库中。数据挖掘的类型包括分类规则挖掘、关联规则挖掘、预测分析、总结规则挖掘、聚类规则挖掘、偏差分析和趋势分析等。其中分类算法作为数据挖掘中获取和提取知识的重要方法,在数据挖掘中起着重要作用。其中决策树算法以其直观性强、数据分析效率高等优点而倍受关注。
1.1 决策树概念
决策树由叶子结点、内部结点以及分叉构成。树的分叉表示检验的结果,树的内部结点表示某种检验属性,分类则用叶子结点表示[2]。
决策树的学习算法本质是贪心算法。决策树的构建过程是由上到下、分而治之。从根结点开始,对给定的数据样本进行测试,根据测试所得结果将数据样本划分成若干子样本集,每个子样本集合构成新子结点。迭代该建树过程,直到满足给定的终止条件。一个构建好的决策树,从根节点开始到叶子结点,每个分支对应一条规则。
1.2 决策树算法
20世纪70年代,机器学习研究者J.Ross Quinlan开发了决策树算法,称作ID3[4-6]。Quinlan后来提出了C4.5,成为新的监督学习算法的性能比较基准。1984年几位统计学家出版了分类与回归树(CART)。以上两类基础算法促进了决策树归纳的研究。
本文的数据分析算法采用ID3,其算法描述如下:
输入:样本samples;候选属性的集合attribute_list.
输出:判定树.

2 ID3对评分结果的分析
将ID3决策树规则的挖掘算法应用于遵义医学院计算机等级考试模拟评分系统中,根据现有的考试成绩可获得决策树规则。现以2010级临床专业某班级40名学生的考试成绩为例,采用决策树规则对Typing、Word、Windows、Choice、Excel和Internet 6种题型间的决策树规则进行挖掘。考试数据共包含40条记录,原表的基本结构和表中的部分数据如表1所示。

表1 原始数据
2.1 数据预处理
为了更好地进行决策树挖掘,需对给定成绩进行预处理[7-10],预处理过程是:将得分率低于0.6的题预处理为未达标,否则预处理为达标,预处理结果见表2。具体处理方法如下:
Choice题预处理规则:分段预处理为“未达标”(小于12分),“达标”(12-20分)。
Windows题预处理规则:分段预处理为“未达标”(小于6分),“达标”(6-10分)。
Typing题预处理规则:分段预处理为“未达标”(小于9分),“达标”(9-15分)。
Word题预处理规则:分段预处理为“未达标”(小于15分),“达标”(15-25分)。
Excel题预处理规则:分段预处理为“未达标”(小于12分),“达标”(12-20分)。
Internet题预处理规则:分段预处理为“未达标”(小于6分),“达标”(6-10分)。

表2 预处理后数据
2.2 构造决策树
根据ID3算法原理,按照2010级临床专业学生是否通过考试来构造决策树模型,采用以下几个步骤。
步骤1:计算2010级临床专业成绩样本分类所需的期望信息
将样本分成两类:设C1是考试通过的类,C2是考试未通过的类,则S1=22,S2=18,总计S=40。
计算给定成绩样本分类所需的期望信息:

步骤2:计算每个考试题型的信息增益
(1)计算“Choice”题型的信息增益
对于“Choice题”=“达标”的情况

对于“Choice题”=“未达标”的情况

计算出按“Choice题”划分给定样本所需的期望信息为:

这种划分的信息增益是:

(2)计算“Windows题”题型的信息增益
对于“Windows题”=“达标”的情况

对于“Windows题”=“未达标”的情况

计算出按“Windows题”划分给定样本所需的期望信息为:
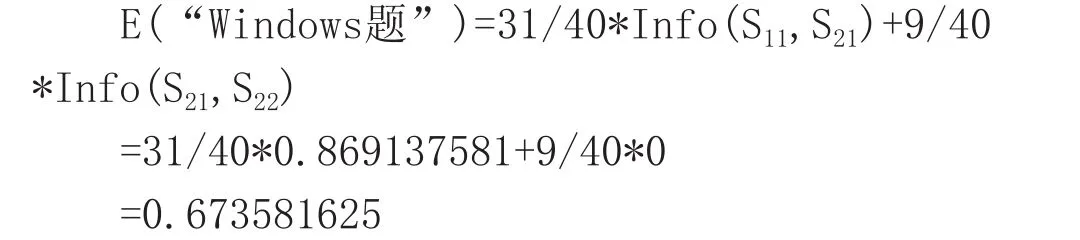
这种划分的信息增益是:

(3)计算“Typing题”题型的信息增益
对于“Typing题”=“达标”的情况

对于“Typing题”=“未达标”的情况

计算出按“Typing题”划分给定样本所需的期望信息为:

这种划分的信息增益是:

(4)计算“Word题”题型的信息增益
对于“Word题”=“达标”的情况
对于“Word题”=“未达标”的情况
计算出按“Word题”划分给定样本所需的期望信息为:

这种划分的信息增益是:

(5)计算“Excel题”题型的信息增益
对于“Excel题”=“达标”的情况

对于“Excel题”=“未达标”的情况

计算出按“Excel题”划分给定样本所需的期望信息为:

这种划分的信息增益是:

(6)计算“Internet题”题型的信息增益
对于“Internet题”=“达标”的情况

对于“Internet题”=“未达标”的情况

计算出按“Internet题”划分给定样本所需的期望信息为:

这种划分的信息增益是:

步骤3:确定测试题型
由于“Excel题”的信息增益最高,它被选为测试题型,用于建立第一个结点,并将样本分成两个部分,然后对每一棵子树按照上述方法递归计算,最后生成的决策树如图1所示。
2.3 提取决策树分类规则
在本例中可提取出以下分类规则:
(1)If “Excel题”=“达标” then “通过”
(2)If “Excel题”=“未达标” and“Windows题”=“未达标” then “未通过”
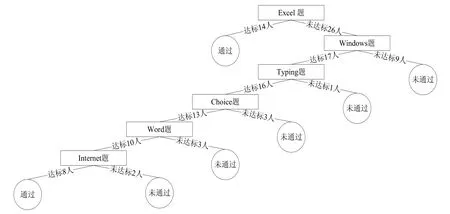
图1 生成决策树
(3)If “Excel题”=“未达标” and“Windows题”=“未达标” and “Typing题”=“未达标” then “未通过”
(4)If “Excel题”=“未达标” and“Windows题”=“未达标” and “Typing题”=“未达标” and “Choice题”=“未达标”then “未通过”
(5)If “Excel题”=“未达标” and“Windows题”=“未达标” and “Typing题”=“未达标” and “Choice题”=“未达标”and “Word题”=“未达标”then “未通过”
(6)If “Excel题”=“未达标” and“Windows题”=“未达标” and “Typing题”=“未达标” and “Choice题”=“未达标”and “Word题”=“未达标” and “Internet题”=“未达标”then “未通过”
(7)If “Excel题”=“未达标” and“Windows题”=“未达标” and “Typing题”=“未达标” and “Choice题”=“未达标”and “Word题”=“未达标” and “Internet题”=“达标”then “通过”
3 结束语
由提取的决策树规则,可得出以下几个结论:
(1)“Excel题”考试“达标”的同学熟练掌握了计算机操作的相关题型,能够在考试过程中获得高分并顺利通过考试。
(2)“Excel题”考试“未达标”的同学,必须在其他5类题型中获得高分,方可通过考试。
对2010级临床专业考生在计算机等级考试中6种题型的得分情况进行决策树挖掘,所得结论能够帮助学生发现“Excel题”为关键性题型,便于学生在学习过程中把握考试的重点。与此同时,教师也需在教学过程中突出“Excel题”的讲解,帮助学生把握考试的关键题型并提升过级率。此结论对考生和教师来说均具有较强的指导性。
[1]K P Soman, Shyam Diwadar,V Ajay.数据挖掘教程[M].北京:清华大学出版社,2003.1-3.
[2]向文燕.ID3算法在英语成绩分析中的应用研究[J].柳州职业技术学院学报,2011,11(2):31-34.
[3]Jiawei Han, Micheline Kamber.数据挖掘概念与技术[M].北京:机械工业出版社,2007.192.
[4]王永梅,胡学钢.决策树中ID3算法的研究[J].安徽大学学报,2011,35(3):71-75.
[5]陈伟,程黄金.ID3算法构造学生专升本考生以成绩分析决策树[J].电脑知识与技术,2009,5(3):744-746.
[6]吴陈,林炎钟.C4.5算法在高校教师评价中的应用研究[J].信息技术,2011,(1):133-136.
[7]邝涛.基于决策树技术在高校成绩分析中的应用研究[J].新乡学院学报,2011,28(1):49-51.
[8]何小明.基于OLAP与数据挖掘的高考招生数据分析[J].计算机科学,2012,39(6):175-178.
[9]刘美玲.数据挖掘技术在高校教学与管理中的应用[J].计算机工程与设计,2010,31(5):1130-1133.
[10]王丹.数据挖掘技术在高职院校教学管理中的应用[J].广东技术师范学院学报,2010, (3):58-60.
猜你喜欢
中学生数理化(高中版.高二数学)(2022年5期)2022-06-01 06:26:58
中学生数理化(高中版.高二数学)(2021年5期)2021-07-21 02:14:52
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
电子制作(2019年19期)2019-11-23 08:41:36
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年19期)2018-11-14 02:37:02
电子制作(2018年16期)2018-09-26 03:27:06
中学生数理化·七年级数学人教版(2017年5期)2017-11-09 03:06:21
中学生数理化·高一版(2017年2期)2017-04-25 13:17:26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
