
基于Solr和Mahout在线资讯自动分类与全文搜索引擎的实现
2013-05-11 06:15熊立波
中国传媒科技 2013年17期
文|熊立波
在当前信息爆炸式增长的时代,用户对信息服务的需求已经从信息汇聚为主的广播式服务逐渐过渡到要求提供按需、定制化、定向的集成化信息服务。用户要求能按照其特定的业务需求,对信息进行预加工、过滤后,提供给他们精品化的“干货”。这对我们通讯社的信息服务方式也提出了新的要求。在大数据时代,信息量呈几何方式增长,同时我们也积累了大量的历史资讯数据,如果不能对信息进行合理的分类,我们就不能按用户的需求提供给他们需要的信息。但是,如果这些数据都按照传统的人工方式,通过记者和编辑对所有信息进行分类、加工,不仅成本巨大,而且信息加工的效率也不能满足用户对信息时效性的要求。当前,信息智能分析处理技术,特别是针对于中文的资讯智能处理技术已经有了快速的发展。通过技术创新,构建资讯自动预处理系统,减少人工成本,提高信息生产效率和服务能力是我们的必经之路。
文本自动分类与全文检索技术
文本自动分类技术
文本自动分类技术(textcategorization)主要指的是依靠基于机器学习的文本分类算法,在预先给定的类别标记(Label)集合下,根据文本内容判定它所属的类别。
目前应用比较成熟的机器学习算法主要是基于统计学的机器学习和分类算法,统计学习方法的基本思想就是让机器像人类一样通过对大量已经分类好的同类文档的观察来学习并总结经验,作为今后分类的依据。统计学习方法需要一批由人工预先进行了准确分类的文档作为学习的材料,计算机从这些文档中挖掘出一些能够有效分类的规则,这个过程被形象的称为“训练”。训练总结出的规则集合常常被称为分类器。训练完成之后,需要对计算机使用这些训练出来的分类器对从来没有见过的文档进行分类。目前应用比较普遍的分类算法主要包括朴素贝叶斯(naive bayes),KNN算法和支持向量机(SVM, Support Vector Machine)等统计算法。本文主要采用的是朴素贝叶斯算法,主要原因是朴素贝叶斯算法相对简单又有较好的准确度,执行效率高,便于实现对资讯文本进行在线实时的分类。
文本全文检索技术
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,所以分词器的好坏和效率往往在很大程序上影响全文检索的准确性和效率,本文使用的IKanalyzer开源中文分词器是目前使用比较普遍,效率也较高的开源中文分词器。
Apache Mahout与Apache Solr
Apache Mahout是Apache Software Foundation(ASF)旗下的一个开源项目,提供了一些可扩展的机器学习领域经典算法的实现。经典算法包括聚类、分类、协同过滤、进化编程等等。Mahout的中文意思是“大象的训练师”,而“大象”正是Hadoop的符号,正如Mahout名称所表达的意思,Mahout可以构架在Hadoop架构上,从而实现对大数据进行分布式,可扩展的并行计算。Mahout提供的开源分类算法中包含了朴素贝叶斯算法的Java实现。
Apache Solr同样也是Apache Software Foundation(ASF)旗下面向企业的开源搜索服务器,其核心构架在Lucene框架之上,面向企业应用,提供了基于HTTP Web接口的完整的全文检索、高亮显示、切片搜索(facet)等全文搜索功能。
在线自动分类全文检索系统的实现
统架构设计
系统的主要目标是能在线实时的对新入库的资讯文本数据进行自动的预分类和标引,要能够在线实时的被分类、标引和全文索引入库,使用户能即时检索到新入库的资讯。
资讯分类的流程主要包括“学习分类”,“全文索引”和“检索界面”三个部分。“学习分类”流程主要是机器对由人工预先分类好的资讯样本数据进行学习,得到并生成分类器,这个流程由Mahout框架实现;“全文索引”流程是对资讯文本数据进行分词和索引,并用学习分类流程生成的分类器对资讯的分类属性进行标引,这部分功能由Solr框架实现;“检索界面”流程则是开发Web检索界面,便于用户进行查询和检索,这部分功能由jQuery和Ajax-solr框架实现。
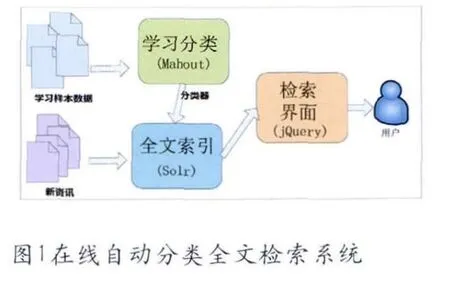
学习分类
1、样本数据
由于分类器是通过对样本数据的学习和训练得到的,样本数据所属分类信息的准确性对分类结果的准确性有很大的影响。为了保证样本的分类属性尽量的准确,本文的样本数据是从互联网专业网站上选取了11个行业资讯样本,每个样本有50篇的文本资讯,每篇文本资讯的字数在500字左右。
图2 样本数据
2、样本数据的学习
Mahout朴素贝叶斯分类器的训练学习过程主要分为五步:
1.使用mahout seqdirectory命令从训练样本数据生成Seq文件(hadoop文件);
2.使用mahout seq2sparse命令生成向量文件;
3.使用mahout split命令拆分向量文件为“学习集”和“验证集”两个集合;
4.使用mahout trainnb命令对“学习集”向量文件进行学习,生成分类器模型
5.使用mahout testnb命令用“验证集”对上一步生成得到的分类器模型的准确度进行测试和验证,对结果进行分析,如果存在问题则调整训练样本文件重新学习测试(大多数问题的原因是训练样本存在分类二义性)
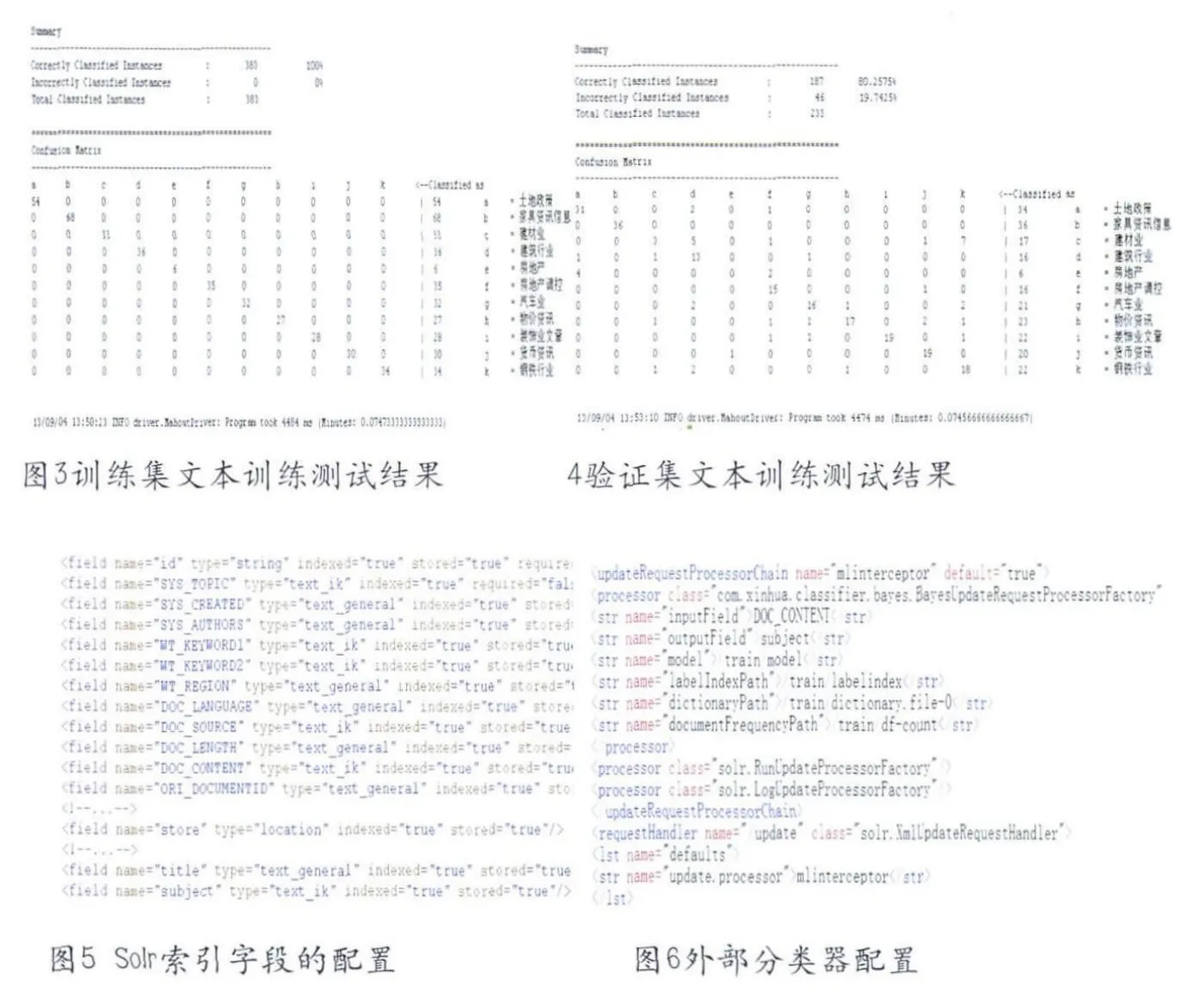
图3和图4分别是用“训练集”和“验证集”验证分类准确性进行验证的输出结果,从训练结果看,用“训练集”验证分类器模型的分类准确率是100%,用“验证集”验证分类器模型的准确率是80.2775%,从图4输出的测试矩阵可以看出,错误比较大的是“土地政策”有4篇文章被分类到了“房地产”中,“建筑行业”有5篇被分类到了“建材业”中,钢铁行业有7篇被分类到了“建材业”,但是从业务角度分析,这几个行业的确有相似的地方,80.2775%分类的准确性还是可以接受的。
全文索引
本文使用的新闻数据是新华社多媒体数据库中历时半年的部分历史资讯数据,一共是58万余条。本文使用了开源的pysolr接口,开发python程序把文本资讯写入到solr索引库中,然后使用Solr调用分类器对写入的资讯数据进行索引和分类,主要步骤是:
1.在solr的schema.xml文件中建立索引字段,由于新闻资讯数据都是中文,本文使用了IKanalyzer开源中文分词器;
2.开发程序对新闻数据文件进行解析,建立新闻数据字段与solr索引字段的映射关系,调用pysolr进行资讯的逐条写入;
3.配置solr的solrconfig.xml文件,使得solr可以调用外部的分类器对特定的字段(本文是对DOC_CONTENT字段)进行分类并进行标引。
检索界面
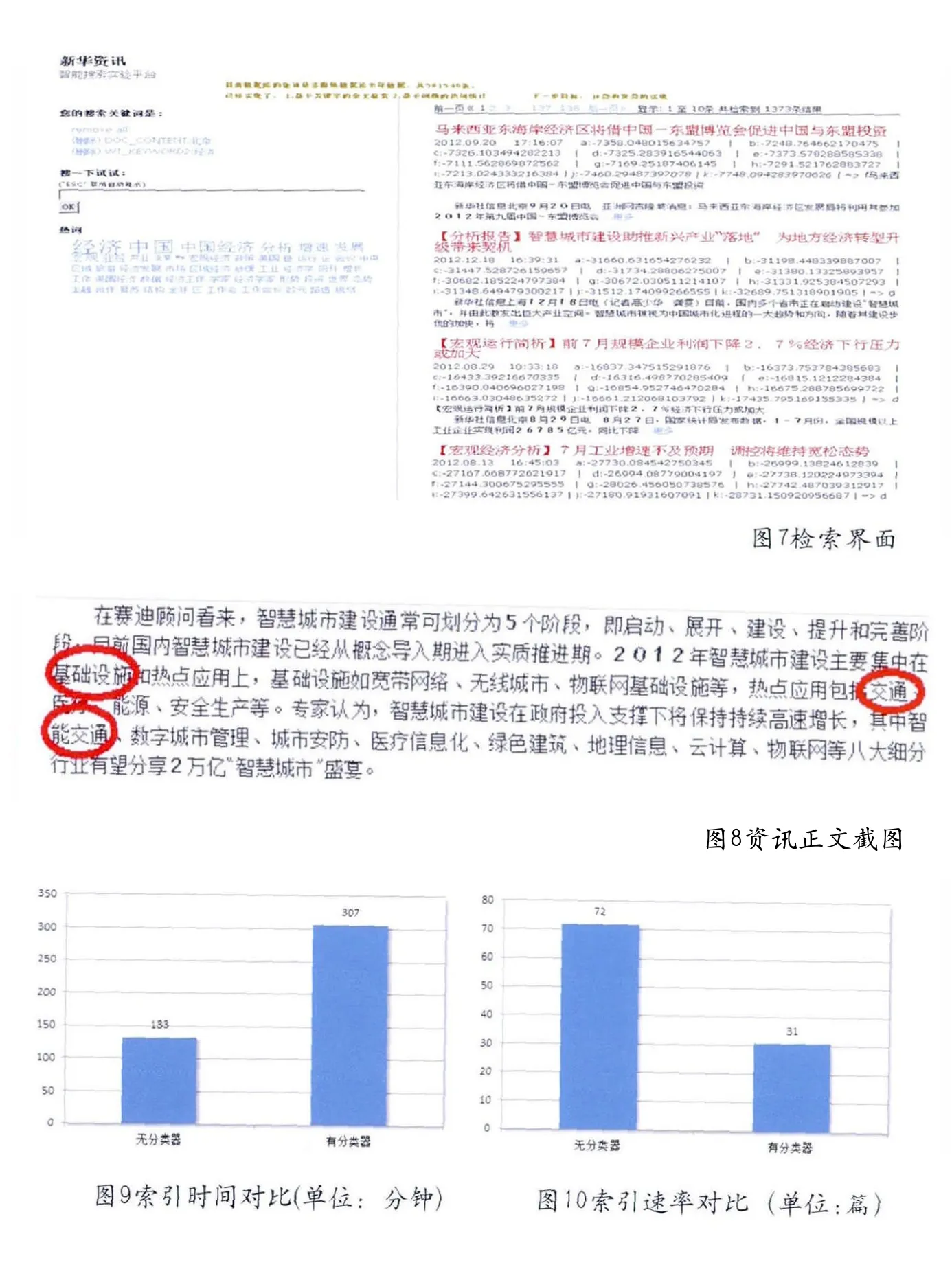
检索界面为用户提供全文检索和分类检索的功能,本文使用的是基于jQuery的ajax-solr开源框架,检索界面把用户输入的检索参数拼装成http请求,访问后台的solr检索引擎,获得的结果再回写入检索界面展示给用户。
从图7可以看出,分类器对每篇资讯所属的11个行业的可能性都进行了打分,分值最大者是最有可能属于的分类,分类器对《智慧城市建设助推新兴产业“落地” 为地方经济转型升级带来契机》这篇文章的分类判定为“g”——汽车业,通过打开正文分析,是因为文中提到了“智能交通”,所以这篇文章在需要判定的11个行业中,汽车业是最接近的(见图8)。
系统评估
本文对58万条余文本数据进行了在线的分类和索引,并对使用分类器和不使用分类器的资讯入库性能进行了对比。从图9、10中可以看出,当使用了分类器以后,较大的影响了文章索引的性能,58万数据全部完成索引的时间是307分钟,平均是31篇/秒,即1860篇/分钟,比没有分类器的索引时间多了1倍多。但是这个索引和分类速度已经可以完全满足目前新华社自有资讯业务的需求,同时由于本文的试验环境是PC虚拟机,如部署到服务器上整体性能还会有进一步提升。
总结
本文创新性的把分类算法和全文检索引擎结合到了一起,通过技术创新,提出并实现了对文本资讯的在线自动分类和全文索引,同时实现了较好的分类准确性和分类检索效率。下一步将进一步优化分类算法和提高分类索引的效率,以期尽快应用到新华社实际的采编业务流程中去。
猜你喜欢
中国-东盟博览(旅游版)(2020年8期)2020-08-19
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
现代计算机(2016年27期)2016-10-29
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
软件导刊(2015年6期)2015-06-24
数字技术与应用(2014年12期)2015-05-04
人生与伴侣·共同关注(2009年18期)2009-08-31
中外会展(2009年6期)2009-08-07
