
适用于中国外语学习者的英文作文全自动集成评分算法
2013-04-23 07:55刘建达
中文信息学报 2013年5期
李 霞, 刘建达
(1. 广东外语外贸大学 思科信息学院,广东 广州 510006; 2. 广东外语外贸大学 外国语言学及应用语言学研究中心,广东 广州 510420)
1 引言
作文自动评分是指通过计算机技术对作文进行评价和分数预估的过程[1-3]。随着国内英语认证考试参加人数的逐年上涨,英语考试作文评分的工作量也逐年大幅上升。在二语习得(Second Language Acquisition)方面的许多研究表明[4-7],随着写作任务的加重,作文的计算机自动评分成为一个必然的趋势,它可以消除传统人工评分过程中由于人工阅卷员之间的地域性、经验性、语言能力、评卷的严厉度等方面的差异而导致的评分结果的一致性、准确性、客观性和可靠性的降低。同时使用计算机对作文进行自动评分具有即时性、客观性、经济性和公平性等优点。
目前国外对以英语为母语的英文作文自动评分技术的研究相对较为成熟,几个作文自动评分系统已被用于英语母语写作评分中,比较有代表性的系统包括: PEG(Project Essay Grade)[8-9]、IEA(Intelligent Essay Assessor)[9-10]、E-rater(Electronic Essay Rater)[9-11]和IntelliMetric[3,9]等,这些系统分别从内容或形式上提取特征,并利用机器学习中的分类或回归技术来实现作文的自动评分,并取得了较好的效果。然而,受中国文化和汉语思维习惯的较大影响,中国学生在英语写作的语言特征如词汇、句法和篇章结构等层次上与国外以英语为母语的学生所写的英文作文差异较大[12-14]。例如,中国学生更容易出现高频率的词汇、短语搭配、介词使用、句法等方面的错误,更多使用话语虚词(如well、now、anyway、however等)、连接词语和形容词等语言特征,而以英语为母语的学生则更注重句型的变化性与灵活性等方面,如作文长度更长,更多使用各种从句等。已有自动评分技术对语言质量的分析主要考虑作文中的句法多样性等母语学生的写作特点,而忽略了非母语学生写作中特有的语言特征,这使得已有的作文自动评分系统无法很好的适用于中国学生的英语作文自动评分中[15]。
由于考生的作文分数普遍位于中等水平位置,即分数高和分数低的作文相对较少,因此,作文评分数据具有不平衡数据分布的特点,这使得传统的分类算法在对作文进行分类评分时效果不佳,通常大类样本数据(在本文中为中等水平作文)分类效果要好于小类样本数据(在本文中为高水平和低水平作文)。为此,本文首先依据中国学生的写作特点,在提出基于高频相邻搭配词组特征选择方法的基础上,利用不充分抽样bagging算法对大类数据进行多次随机抽样,并对多次分类结果进行组合,最终结果为各分类结果的投票得分。对中国英语学习者语料[16]大学英语四、六级不同主题作文下的1 115篇英文作文的评分结果表明,本文提出的算法能够较好的提取反应中国学生写作特点的特征,并有效适用于不平衡数据的分类,在类内和类间的正确率、召回率和F度量值上均有较大幅度的提升。
2 特征提取
传统的特征选择方法通常以分好的单个词为单位,依据所提取的特征对文本构建向量来进行分类处理。以单个词为单位的特征选择方法在作文自动评分中会导致对文字完全相同但顺序打乱前后的两篇作文评为相同的分数,这是因为单个词特征提取时没有考虑到词与词之间的前后顺序关系。依据中国学生英文写作的特点,如对介词和连词等掌握相对不是很好、习惯使用短语词组等特点,一方面避免出现词序打乱后的作文被误评,同时又能充分体现中国学生英文写作的特点,本文提出基于高频相邻搭配词组特征选择方法,该方法既考虑到词的前后顺序关系,同时也符合中国学生在英文写作中习惯使用短语词组的特点。
在提取特征时,本文没有过滤通常意义上的停用词,这是因为在一般的文本分类中诸如of,to,that等词由于具有较低的分类贡献度而通常被做为停用词过滤掉。但在英文作文中,介词、连词等的正确使用往往是衡量一个学生英文写作水平的一个重要方面,同时它也是很多短语词组的搭配词,为此本文在提取作文特征时,并没过滤任何停用词,详细特征选择算法描述如下。
输入:n篇已知分数档的英文作文;
输出: 有效词组特征;
1. 对英文作文依据空格分词得到词列表{t1,t2,….,tn};
2. 依据从左至右的顺序提取相邻二元搭配词组,得到词组列表titj(i=0,…,n;j=0,…,n,i≠j);
3. 计算每个相邻二元词组的信息增益值;
4. 对所有相邻二元词组的信息增益值排序;
5. 对横坐标为特征维数,纵坐标为相应二元词组特征的信息增益值为点对画散点图,计算急剧变化的点所对应的维数k,k为该训练集的有效特征维数;
6. 输出前k个相邻二元词组特征作为该训练集的有效特征。
文本分类领域常用的特征选择方法有文档频率(DF)方法、信息增益(IG)方法、互信息方法(MI)等[17],本文采用应用广泛的信息增益(IG)方法来提取取作文特征,本文所采用的信息增益的计算公式描述如式(1)所示:

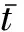
为了验证我们所理解的中国学生英文写作的特点,我们利用信息增益特征选择方法分别对来自中国英语学习者语料库中大学英语四级作文中主题为Global Shortage of Fresh Water的290篇作文以及大学英语六级作文中主题为Haste Makes Waste下的344篇作文,分别以单词为单位和以相邻二元词组为单位进行了特征提取,提取结果如表1和表2所示。表1结果表明,相邻二元词组特征选择方法所提取的特征能较好的反应中国学生的写作特点,例如,较多使用固定搭配、中国式英语、主动句等。如在大学英语四级库中主题为Global Shortage of Fresh Water下290篇作文所提取的相邻二元词组特征中有较多的固定词组搭配以及反应中国学生写作特点的词汇,如is_important(非常重要…),use_them(使用他们…),under_the(在…下),are_also(也是…),very_shortage(非常缺乏…), must_be(必须), at_present(目前…), in_recent(最近…), already_used(已经使用…)等。在大学英语六级库中主题为Haste Makes Waste的344篇文章中所提取的相邻二元词组特征中也同样反应了中国学生的写作特点,例如,try_to,it_must,easy_to, much_time, is_easy,makes_us,everyday_life, i_can,all_kinds等。从这些结果中可以看出中国学生习惯使用短语词组和习惯使用主动句等写作习惯。通过提取这些特征,能够较好地提升中国英语学习者英语作文的分类评分效果。

表1 主题为Global Shortage of Fresh Water共290篇大学英语四级作文中所提取的特征对比
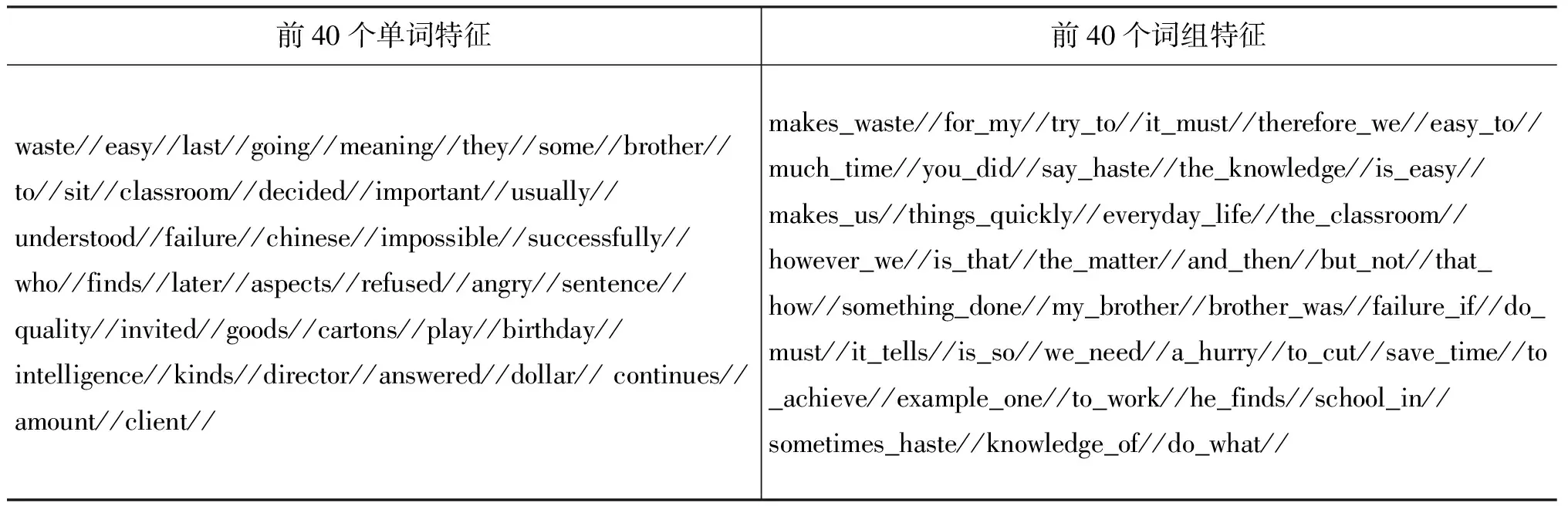
表2 主题为Haste Makes Waste共344篇大学英语六级作文中所提取的特征对比
3 英文作文的表示
采用文本分类中广泛使用的向量空间模型(Vector Space Model)[18]来表示作文,每篇作文对应于一个空间向量,其格式为V(dj)=(〈t1,w1〉,…,〈ti,wi〉,…,〈tm,wm〉)(i=1,2,…,m),这里的ti(i=1,2,…,m)为训练作文数据中选出的m个相邻二元词组特征,wi(i=1,2,…,m)为每篇作文dj(j=1,2,…,n)的第i个相邻二元词组特征所对应的权重值,权重值的计算方法主要包括: 词频方法(TF)、逆文档频率方法(IDF)、词频—逆文档频率方法(TF-IDF)[19],在中国学生英文作文数据上的分类评分结果显示,逆文档频率相对其他两个权重公式具有较优结果,其计算公式如式(2)所示:
其中,w(ti,dj)为特征词组ti在作文dj中的权重,tf(ti,dj)为特征词组ti在作文dj中出现的次数,N为训练作文文档的总数,df(ti)为作文训练集中包含特征词组ti的作文文档个数。在本文算法中,逆文档频率IDF的计算效果最好。作文向量之间的相似度采用余弦相似度来计算,计算公式描述如式(3)所示:
(3)
(i,j=1,2,…,n)
其中sim(di,dj)表示第i篇作文和第j篇作文之间的相似度,而wik(k=1,2,…,m)表示第i篇作文的第k个词的权重值,wjk(k=1,2,…,m)表示第j篇作文的第k个词的权重值,m为表示整个作文数据中所有作文采用的相邻二元词组特征总数。
4 基于随机抽样和算法组合的不平衡作文数据分类评分算法

其中 V为所有二元词组特征的总数,Nk表示第k个相邻二元词组特征wk在作文d中出现的次数,P(wj|ci)表示相邻二元词组特征wj在分数档ci的作文中出现的概率,其计算公式如式(5)所示:
其中Nji为第j个相邻二元词组特征在分数档ci的作文文档中出现的次数,Nci表示分数档ci的所有作文文档中二元相邻词组的总数。
4.2基于随机抽样和算法组合的不平衡作文数据分类评分算法 由于作文数据具有分布不平衡的特点,简单使用传统适用于分布均匀的分类算法将不能有效适用于作文的自动分类。以大学英语四级主题为“GlobalShortageofFreshWater”290篇英文作文为例,分别对其进行基于信息增益的特征选择,特征维数为100,使用多项式朴素贝叶斯进行评分结果如表3所示。在该结果中,2分档和5分档的召回率和F度量值均为0.4和0.5左右,低于大类数据3分档和4分档的R值和F值近30%,这说明传统基于均匀分布样本的分类算法不能很好的应用于作文的自动评分上。
表3多项式朴素贝叶斯分类算法在GlobalShortageofFreshWater主题290篇作文上的分类结果

分数档作文个数PRF2分档200.6920.450.5453分档1270.7720.8270.7984分档1220.7640.7950.7795分档210.6430.4290.514
为了改变作文特征受大类作文数据的影响,本文提出了一种基于多次随机抽样及算法组合的不平衡数据分类评分方法,所提出的算法通过多次不充分抽样来平衡数据样本,并对多次评分结果进行投票获得最终评分结果,具体算法描述如下:
输入: 待预测作文x,不充分抽样次数m;
输出: 预测类别;
1. for(inti=1;i≤m;i++)
2. {
3. 利用Bagging方法随机从大类数据中抽样得到与小类数据大小相同的样本;
4. 将小类作文数据与抽样得到的大类作文数据合并作为训练集;
5. 使用基于多项式模型的朴素贝叶斯分类算法对训练集进行分类,得到分类结果yi;
6. }

8. 返回预测作文x的预测类别y′。
5 实验结果
采用由桂诗春和杨慧中老师主编的中国学习者英语语料库(Chinese Learner English Corpus,CLEC)[16]作为测试数据,该语料库包含了大学英语四级和大学英语六级等不同级别考试的作文,并对所有作文进行了手工错误标注和分数归类。考虑到实际计算机作文评分时,是不包含有错误标注信息的,我们对所测试的不同主题的作文的错误标注信息进行了清除,使其尽量保持原始作文状态。
为了较为全面地测试本文的评分算法,分别选取了CLEC语料中大学英语四级作文库(ST3子库)和大学英语六级作文库(ST4子库)中来自四个主题的共计1 115篇英文作文进行评分测试。其中大学英语四级作文选取了Global Shortage of Fresh Water主题作文290篇和Getting to Know the World Outside the Campus主题作文202篇。大学六级作文选取了Haste Makes Waste主题作文341篇和My View on Job-Hopping主题作文282篇。按照大学英语四、六级的评分标准,进行评分时先把作文划分成5个分数等级,这5个登记分别是2分档,5分档,8分档,11分档,14分档。在本研究中,由于所有作文语料没有2分档的作文,为此本文将评分范围划分成了4个分数段: 5分档、8分档、11分档和14分档,并将其当作类标号,所测试的1 115篇作文按照分数档划分的详细信息如表4所示。

表4 1 115篇作文按分数段划分分布表
算法评估指标采用分类准确率P、召回率R和F度量值来进行评价,对某个分数或分数档类别ci,该类别样本分类的正确率Accuracy、准确率P、召回率R、F度量值的定义如下:

其中,Nci→ci表示类别ci中正确分类的作文个数,Ncj→ci表示属于类别cj且别分类为类别ci的作文个数,Nci→cj表示属于类别ci且别分类为类别cj的作文个数,其中ci和cj表示不同的分数或分数段类别。
整个实验是在一台配置32位Win7操作系统,安装内存为2G,处理器为Intel Celeron G530 2.4GHz 的台式机器上进行,程序用VC++6.0 实现,所有实验结果均采用十则交叉验证后得到。
表5为本文算法与传统多项式朴素贝叶斯分类算法在大学英语四、六级不同不平衡作文数据中的分类结果对比,为了让结果具有可对比性,所有数据均为提取特征维数为100时的结果。从该结果可以看出,本文算法在特征维数为100的基础上,不仅平均分类评分精度、召回率及F度量值有所提高,其中F度量值均提高10%以上,且大类作文数据和小类作文数据都取得了较平均和较好的P、R和F值,这证明本文的算法是有效可行的。
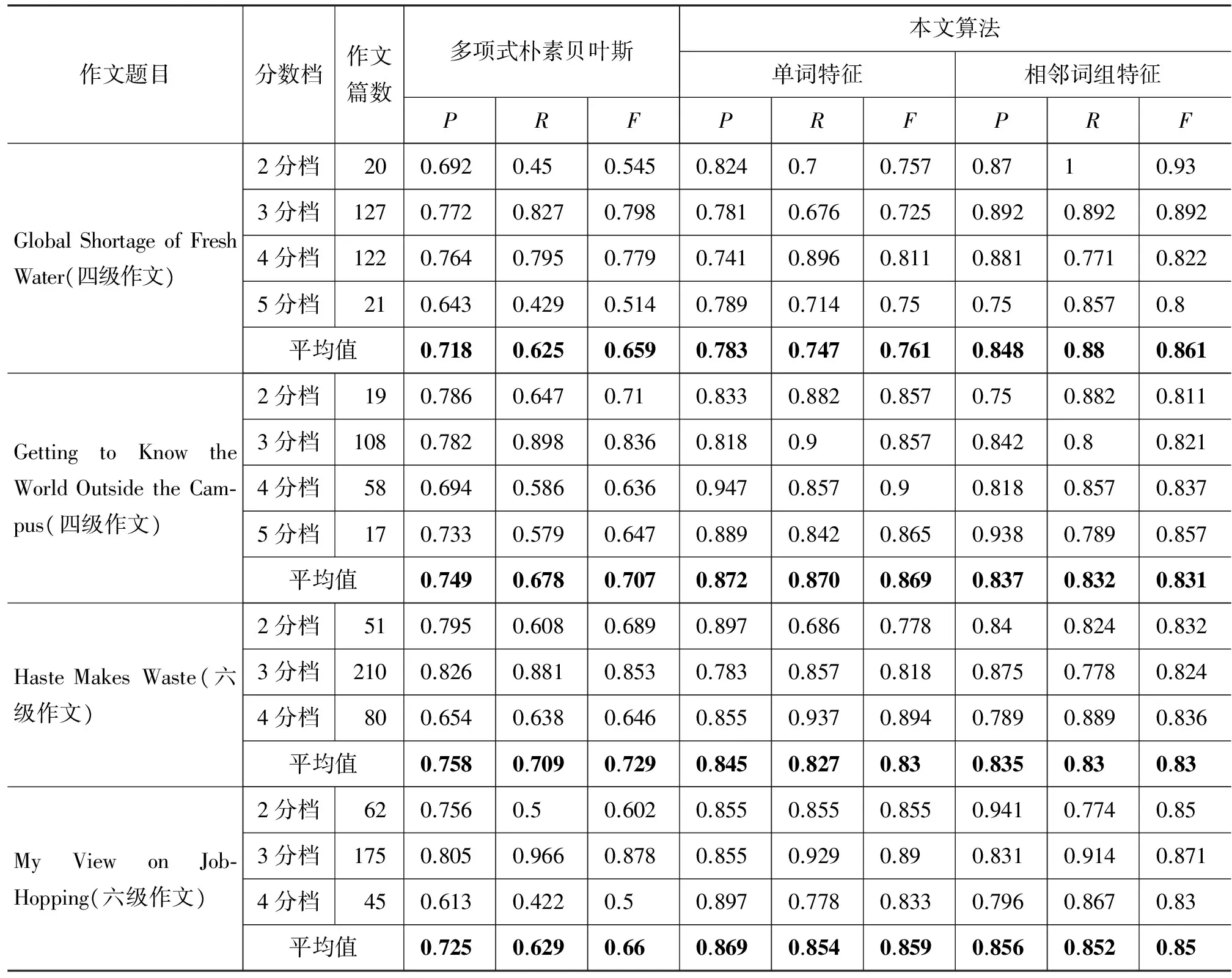
表5 本文算法与多项式朴素贝叶斯算法在四、六级作文上的分类结果对比
表6显示了多项式朴素贝叶斯分类算法和本文算法在自动计算最佳特征维数时所得到分类评分结果的对比,其中本文算法中全部采用基于二元词组特征。从实验结果可以看出,本文所提出的算法无论是在P值、召回率或是F度量值上都是最优的,并且相比传统多项式朴素贝叶斯分类算法在单词特征上的分类结果具有较大幅度的提升。
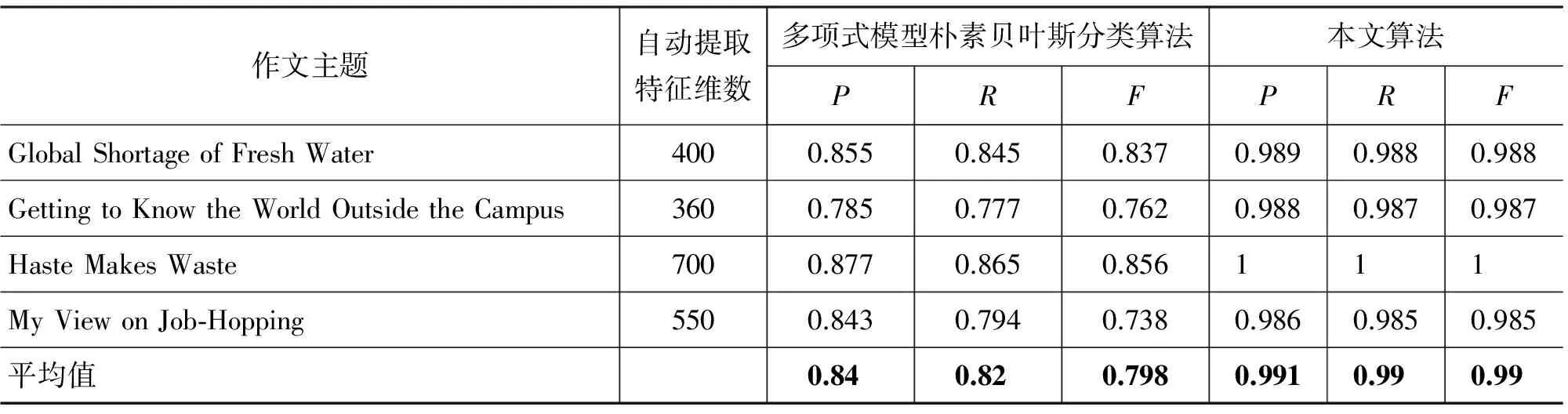
表6 不同算法在1 119篇作文上的分类结果对比
6 结论
利用计算机实现作文自动评分是自然语言处理领域一个比较崭新的研究方向,它拥有广阔的应用前景。本文结合中国学生受汉语影响以及所特有的写作特点,如介词掌握不好、短语搭配掌握不好等特征,提出了适用于中国英语学习者以及不平衡分布作文数据的集成分类评分算法,通过在CLEC语料库中大学英语四级和六级一共1 115篇作文中的分类评分结果显示,所提出的算法相比传统面向分布均匀数据的分类方法具有较高的准确率,能够有效应用于中国英语学习者的作文自动评分中。另外,由于本文的实验数据仅限于大学四、六级作文数据,并且每篇主题作文均不超过400篇,样本量还是比较小,在接下来的工作中,将继续探讨高考英文作文的分类评分处理以及大样本作文数据下的评分效果分析。
[1] Sherm is, M.D., J. Burstein. Automated Essay Scoring: Cross-disciplinary Perspective. Computational Linguistics[J]. 2004,30(2):245-246.
[2] Rudner, Lawrence, Phill Gagne. An overview of three approaches to scoring written essays by computer. Practical Assessment[J], Research & Evaluation, 2001, 7(26).
[3] S Valenti, F Neri, A Cucchiarelli. An Overview of Current Research on Automated Essay Grading[J]. Journal of Information Technology Education,2003,2(1):319-330.
[4] Hamp-Lyons L. On Second Language Writing[M].Lawrence Erlbaum Associates,2001.
[5] Kukich K. Beyond Automated EssayScoring[C]//Proceedings of the debate on automated essay grading. IEEE Intelligent systems,2004:22-31.
[6] Hamp-Lyons L. Fourth Generation Writing Assessment[M].Lawrence Erlbaum Associates,2001.
[7] Weigle S C. Assessing writing[M].Cambridge University Press,2002.
[8] Shermis M, Mzumara H R, Olson J, et al. On-line grading of student essays: PEG goes on the world wide web[J]. Assessment & evaluation in higher education, 2001, 26(3).
[9] 梁茂成,文秋芳.国外作文自动评分系统评述及启示[J].外语化教学,2007,17(2):18-24.
[10] Dikli S. Automated Essay Scoring[J]. Turkish Online Journal of Distance Education, 2006,7(1).
[11] Yigal Attali, Jill Burstein. Automated Essay Scoring With E-rater v.2.0[M]. Princeton,2005.
[12] 方清.中西方思维模式的不同及其对中国学生英语作文的影响[D].中山大学,2003.
[13] 马广惠. 中美大学生英语作文语言特征的对比分析. 外语教学与研究. 2002,34(5):345-380.
[14] 葛诗利,陈潇潇.大学英语作文自动评分研究中的问题及对策[J].山东外语教学,2009,3:21-26.
[15] Jill Burstein, Martin Chodorow. Automated Essay Scoring for Nonnative English Speakers[C]//Proceedings of a Symposium on Computer Mediated Language Assessment and Evaluation in Natural Language Processing. 1999: 68-75.
[16] 桂诗春,杨惠中.中国学习者英语语料库[M].上海外语教育出版社,2003.
[17] Yang Yiming. A comparison study on feature selection in text categorization[C]//Proceedings of the Fourteenth International Conference on Machine Learning (ICML 1997), Nashville, Tennessee, USA, July 8-12, 1997: 412-420.
[18] Salton G, Wong A, Yang C S. A vector space model for automatic indexing [J]. Communications of ACM, 1975, 18(11):613-620.
[19] G Salton, C Buckley. Term-weighting approaches in automatic text retrieval. Information Processing and Management [J]. 1998, 24 (5):513-523.
[20] Andrew Mccallum, Kamal Nigam: A Comparison of Event Models for Naive Bayes Text Classification. In: AAAI-98 Workshop on ‘Learning for Text Categorization’, 1998.
[21] Rudner L M, Liang T. Automated essay scoring using Bayes’ Theorem [J]. The Journal of Technology, Learning and Assessment, 2002: (2).
[22] Larkey L, Croft W B. A Text Categorization Approach to Automated Essay Scoring[C]//Proceedings of Shermis M.D. and Burstein J. (eds.), Automated Essay Scoring: A Cross-Disciplinary Perspective, Lawrence Erlbaum Associates, Inc., Hillsdale, NJ, 2003: 55-70.
猜你喜欢
数学小灵通·3-4年级(2021年6期)2021-07-16
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
趣味(数学)(2019年12期)2019-04-13
鄱阳湖学刊(2016年6期)2017-01-16
中国远程教育(2016年6期)2016-12-07
财经(2016年19期)2016-08-11
中国远程教育(2016年5期)2016-06-29
高中生学习·高三版(2014年3期)2014-04-29
