
基于决策树的燃煤锅炉运行优化规则的提取
2013-02-27 03:10:04王文欢潘秉超潘卫国
上海电力大学学报 2013年2期
王文欢,潘秉超,潘卫国
(上海电力学院能源与机械工程学院,上海 200090)
电厂数据的传统分析手段主要集中在计算机组的主要运行特性指标计算方面,如锅炉热效率、汽轮机热耗率、发电煤耗率、供电煤耗率、高压缸效率、中压缸效率等.传统的报表已经不能满足电力企业现代化生产的需要.随着电力企业向大型化、自动化、现代化方向的发展,以及适应“厂网分开、竞价上网”的需要,提高发电机组的运营管理水平、节能降耗、增强企业竞争力,已成为发电企业面临的最为紧迫的问题.
如果能充分利用数据仓库、联机分析处理、数据挖掘技术,结合火电机组自身的特点,对机组的安全经济运行状况进行联机分析和数据挖掘,多角度、全方位展现数据,并发现隐藏在生产数据中有用的知识,揭示电力企业历年积累的数据背后所蕴含的规律和规则,并据此来判定机组当前的运行情况,发现存在的隐患,就能指导机组的安全经济运行,为决策提供更加有力的科学依据,提高电厂的信息化水平、管理水平和市场竞争力.
1 决策树的基础理论
1.1 数据挖掘
数据挖掘(Data Mining)就是从大量的、不完全的、有噪音的、模糊的、随机的原始数据中,提取隐含在其中的、人们事先不知道的,但又是潜在有用、可信、新颖的信息和知识的过程.它是一门广义的交叉学科,它的发展和应用涉及不同领域,尤其是数据库、人工智能、数理统计、可视化、并行计算等.
数据挖掘也被称为数据库中知识发现(Knowledge Discovery in Database,KDD),对它的研究主要基于3大技术支柱,包括数据库、人工智能和数理统计.图1简要描述了数据挖掘技术的形成过程.
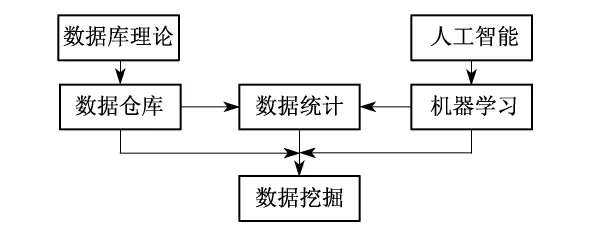
图1 数据挖掘的形成过程
数据库理论的发展促成了数据仓库的形成,人工智能的发展促进了机器学习的进步,同时这些技术与传统的数理统计理论的结合,最终促成了数据挖掘技术的形成.
由此可见,数据挖掘是一门交叉学科,它把人们对数据的应用从低层次的简单查询,提升到从数据中挖掘知识,提供决策支持.在这种需求牵引下,汇聚了不同领域的研究者,尤其是数据库技术、人工智能技术,以及数理统计、可视化技术、并行计算等方面的学者和工程技术人员,他们把这些高深复杂的技术封装起来,使人们不需要自己掌握这些技术也能完成同样的功能,并且更专注于自己所要解决的问题.
目前,最流行的几种数据挖掘方法有决策树、神经网络、遗传算法、近邻算法和关联规则等.本文重点介绍电厂优化运行的决策树模型.
1.2 决策树模型
决策树方法[1]是目前应用最广泛的归纳推理算法之一,也是一种逼近离散值函数的方法.它是以实例为基础的归纳学习算法,通常用来形成分类器和预测模型,着眼于从一组无次序、无规则的事例中推理出用决策树表示的分类规则.分类在数据挖掘中是一项非常重要的任务,目前在商业中应用最多.
所谓决策树就是一个类似流程图的树型结构,其中树的每个内部结点代表对一个属性(取值)的测试,其分支则代表测试的每个结果,而树的每个叶结点就代表一个类别,树的最高层结点就是根结点.常用的决策树方法有ID3,C4.5,CART,CHIAD,PUBLIC.最为典型的决策树学习算法是ID3算法[2],它采用自顶向下不回溯策略,保证找到一个简单的树.由于C4.5算法对ID3算法做出的较大改进[3],并且凭借其独特的特点和突出的优势,已经在金融、医疗等行业得到了成功的应用.在文中笔者利用C4.5算法对锅炉运行的历史数据进行挖掘分析,并给出分析结果.
1.3 C4.5算法介绍
C4.5算法[4]除了拥有ID3算法的功能外,还引入了新的方法,增加了新的功能.例如:用信息增益率的概念;合并具有连续属性的值;可以处理具有缺少属性值的训练样本;通过使用不同的修剪技术以避免树的过度拟合;k交叉验证;规则的产生方式等.
C4.5在本质上和我们前面给出的决策树推导方法相同:在选择测试属性时,通过信息熵公式计算出各属性的信息增益.C4.5采用启发式搜索来选择导致最大信息增益率(GainRatio(A))的属性A作为扩展属性进行分枝,整个算法是个递归过程,直到无法分裂出新的结点为止.
GainRatio(A)方法认为应当选择信息增益好的属性,一个属性的信息增益率可用公式表示为:
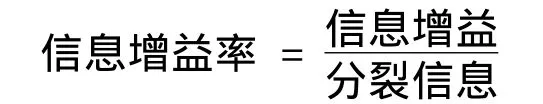
可见,C4.5采用的信息增益率表示了由分枝产生的有用信息的比率,这个值越大,分枝包含的有用信息越多.
ID3算法最初假定属性为离散值,但在实际环境中,很多属性值是连续的.对于连续属性,C4.5处理过程如下:
(1)根据属性的值,对数据集排序;
(2)用不同的阈值将数据集进行动态划分;
(3)当输出改变时确定一个阈值;
(4)取两个实际值的中点作为一个阈值;
(5)取两个划分,所有样本都在这两个划分中;
(6)得到所有可能的阈值、增益及增益率;
(7)每一个属性会变为两个取值,即小于阈值或大于等于阈值.
C4.5算法与ID3算法比较,主要特点有以下几点:
(1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择属性值多的属性的缺陷;
(2)通过使用不同的修剪技术以避免树的过度拟合;
(3)能够对不完整数据进行处理,即可以处理具有缺少属性值的训练样本;
(4)合并具有连续属性的值,即能够将连续值属性转换为离散的二值属性,转换的原则是对连续值属性进行分割,对各种可能的分割分别计算信息增益率,选择具有最大信息增益率的分割.
电厂锅炉效率的海量数据是一组连续性的属性值,而且其中存在缺少属性值的数据.采用基于决策树模型的C4.5算法完全符合电厂需求,可以有效处理电厂数据.
2 基于决策树的锅炉数据运行优化
本文主要通过基于Java平台的Weka软件作为数据挖掘工具,以决策树分析中的C4.5算法为基础,以锅炉效率为目标属性,选择与锅炉运行相关的参数进行分类,并提取有用的分类规则,指导锅炉优化运行.
2.1 数据预处理
锅炉运行参数调整受机组负荷的影响较大,因此选择某一负荷下的参数样本数据进行分析会更有意义,本文选取600 MW机组负荷燃烧状况较优时的运行数据,对经过模糊粗糙集[5]预处理后约简的共1 533组数据7个属性进行决策树分析.
锅炉效率是表征锅炉运行经济性的指标,可作为决策树算法中的决策属性,本文将锅炉效率离散化为3组,分别表示锅炉效率偏低、正常和高效.离散化结果如表1所示.

表1 发电煤耗率离散化区间
2.2 决策树的生成
利用Weka软件选择C4.5算法进行决策树分析(选取叶节点的最小实例数为50),得到的树形图如图2所示.
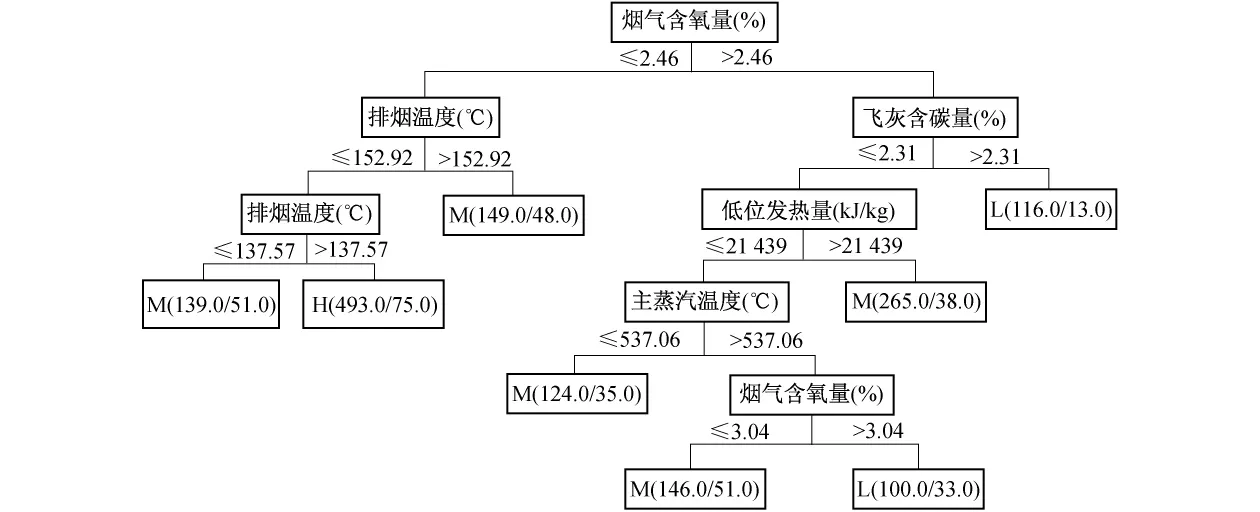
图2 决策树树形图
决策树树形图的基本组成部分包括决策节点、分支和叶子.决策树最上面的根节点是整个决策树的开始.决策树以烟气含氧量作为根节点,说明烟气含氧量的大小是锅炉效率高低的关键因素,一共产生了7个叶节点,可以提取7+1条分类规则.
2.3 结果分析
C4.5算法从树的根节点处的所有训练样本开始,选取一个属性来区分这些样本,对属下的每个值产生一个分支,分支属性值的相应样本子集被移到新生成的子节点上,这个算法递归地应用于每个子节点上,直到节点的所有样本都分区到某个类中,到达决策树叶结点的每条路径表示一个分类规则.这样,对节点属性值的选择就成为自顶向下决策树生成算法的关键性决策.
我们可以根据决策树树形图的路径生成8条规则,将部分规则列举如下.
规则1 当烟气含氧量大于2.46%和飞灰含碳量大于2.31%时,锅炉效率偏低,即当锅炉效率低的时候先考虑飞灰含碳量是否过大,其原因可能是锅炉炉膛燃烧不充分.操作人员可以调节相关参数来提高锅炉效率.
规则2 当烟气含氧量小于2.46%和排烟温度为137.59~152.92℃时,锅炉处于高效运行,即排烟温度直接影响锅炉燃烧状况的好坏.要使锅炉运行效率处于高水平状态必须严格控制排烟温度.
规则3 当烟气含氧量小于2.46%和排烟温度大于152.92℃时,锅炉效率处于正常水平.此时可以不做调节,但如果要提高锅炉效率,操作人员可以根据规则2进行调节.
3 结论
(1)C4.5算法由于易于转化为图像显示的特点,因而使用范围很广.通过数据预处理、构造和修剪决策树、进行分析和评估、生成分类规则等步骤,完成了分类数据的挖掘.但由于选择的属性不同,模型的精度也会不同,因此在今后的实验过程中应该尽可能全面顾及各个影响参数,改善不足之处,以提高模型的精确度.
(2)根据电力行业的特点和火电厂运行特性,运用C4.5决策树数据挖掘的方法,对电厂锅炉运行效率进行分析,树状图形象地反应了锅炉效率与烟气含氧量、主蒸汽温度和机组效率之间的关系.通过分类提取有用分类规则,根据预期锅炉效率来控制烟气含氧量、飞灰含碳量等参数,为锅炉的优化运行提供指导.
[1]杨清,杨岳湘.基于决策树的学习算法[J].湘潭师范学院学报,1999,20(3):56-60.
[2]杨明,张载鸿.决策树算法ID3的研究[J].微机发展,2002,12(5):6-9.
[3]吴楠,宋方敏.用C4.5算法对局域网数据包进行行为分类[J].计算机技术与发展,2006,16(7):1-3.
[4]QUINLAN J Ross.C4.5:Programs for machine learning[M].SanMate,CA:Morgan Kaufmann Publishers,1993:6-26.
[5]ANDREW Kusiak.Rough set theory:a data mining tool for semiconductor manufacturing[J].IEEE Transactionson Electronics Packaging Manufacturing,2001,24(1):44-50.
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
大众投资指南(2021年35期)2021-02-16 01:06:26
电子制作(2019年19期)2019-11-23 08:41:36
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年19期)2018-11-14 02:37:02
电子制作(2018年16期)2018-09-26 03:27:06
电力与能源(2017年6期)2017-05-14 06:19:37
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
信息通信技术(2015年6期)2015-12-26 01:16:46
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
