
一种基于取证哈希的数字视频篡改取证方法
2013-01-01 02:10杨高波
电子与信息学报 2013年12期
魏 晖 杨高波 夏 明
(湖南大学信息科学与工程学院 长沙 410082)
1 引言
数字媒体的数字化本质以及图像/视频编辑工具的发展,使得它们可能被故意篡改伪造,传统的“眼见为实”的观念正在被颠覆。为了鉴别数字媒体的来源和真实性,近些年出现了主动取证和被动取证两类数字媒体取证技术[1]。其中,主动取证需要在数字媒体内容生成过程中,预先嵌入数字水印或者感知哈希等辅助数据,被动取证则仅凭数字媒体本身判别其是否经历篡改等处理。
根据取证所采用的特征,视频被动取证分为成像设备的一致性[2],伪造过程遗留的痕迹[3]和自然视频本身统计特性[4]3类。然而,绝大多数被动取证方法都只对某种特定的篡改手段有效,且只能提供其真伪的二值判断。此外,视频被动取证仍然停留在设备追溯和篡改检测的阶段。随着各种视频编辑工具软件的推出,实际的视频篡改伪造往往联合使用多种手段,以尽可能地掩盖遗留的痕迹。在取证科学应用中,如果能够准确地估计数字视频所经历的完整处理历史,将有力地增强取证的说服力。
尽管单独的篡改手段都会留下细微的痕迹,但多种篡改手段的痕迹相互叠加和混淆时,如果缺乏关于原始数字媒体的先验知识,特别是边信息(side information)时,纯粹的被动取证技术难以满足深层次取证的要求。文献[5,6]结合传统的感知哈希与被动取证,提出一种基于取证哈希的图像取证框架。取证哈希是从篡改取证的角度出发,通过预先考虑篡改时原始视频可能发生的改变,提取能够反映这种改变的统计特征作为边信息。取证哈希组件的构造综合考虑了计算复杂度、哈希长度和取证能力的要求。其中,对齐组件(alignment component)通过提取SIFT[7]特征点作为边信息,并以特征点本身的参数作为参考,实现图像的几何变换恢复。在同尺度和角度(common ground)的情况下,利用分块边缘方向直方图构造完整性检测组件(integrity check component),对可能存在的内容篡改进行定位。该方法取得了较好的篡改定位取证效果,且能有针对性地估计整个图像所经历的操作。此外,针对图像的内容认证分析,文献[8]提出了取证签名的概念,通过提取自适应的Harris角点[9]作为图像的特征点,再根据邻域特征点的统计构造紧凑的取证签名。本质上,这里的取证签名与文献[5,6]的取证哈希是一致的,它们都是从方便取证的角度,通过预计可能出现的篡改操作,从源图像提取对篡改手段鲁棒的特征而构造的。
然而,视频取证分析相对于静止图像来说更为困难,原因在于:(1)数字视频总是经压缩后存储的,高的压缩比会削弱或者破坏篡改过程遗留的痕迹;(2)视频数据量大,取证的计算复杂度高;(3)视频具有不同于静止图像的独特性,几乎所有的图像篡改手段都可以对视频帧进行,并且可扩展到时间维。尽管已经出现了少量的图像取证哈希/签名的文献,但还没有视频取证哈希的文献报道。本文在文献[5-7]的启发下,结合视频篡改伪造的特点,提出了一种基于取证哈希的视频篡改取证方法,尝试估计可疑视频的处理历史。本文提出的方法暂时只考虑了背景静止的视频。本文工作的价值在于:(1)以模块化的方式构建了视频取证哈希的框架,在取证哈希的鲁棒性,篡改定位能力与长度之间进行了有效的折中,且具有可伸缩性;(2)考虑了视频的时域相关性,取证哈希组件更为紧凑;(3)内容感知的视频缩放是一种新的视频篡改手段,本文针对基于seamcarving的内容感知视频缩放技术[10],构造了相应的取证组件并进行取证。
本文内容组织如下:第2节阐述视频取证哈希框架,并构造了几种视频取证哈希组件;第3节是实验结果与分析;第4节总结全文。
2 视频取证哈希组件的构造与篡改估计
本节提出的视频取证哈希框架如图1所示。采集的视频经过预处理后,提取能够反映其统计特征和内容特征的边信息,构造取证哈希组件。取证哈希通过密钥加密后,安全地粘附于视频一起进行传输。取证时,对接收到的视频(可能经历了篡改伪造)按照相同的方法提取取证哈希,并与原始取证哈希进行匹配,从而完成必要的取证分析。本文的取证哈希组件主要有3个:几何变换估计组件h1,运动对象增删检测组件h2和篡改定位检测组件h3,它们以模块化的方式一起工作。
2.1 取证哈希组件的构造
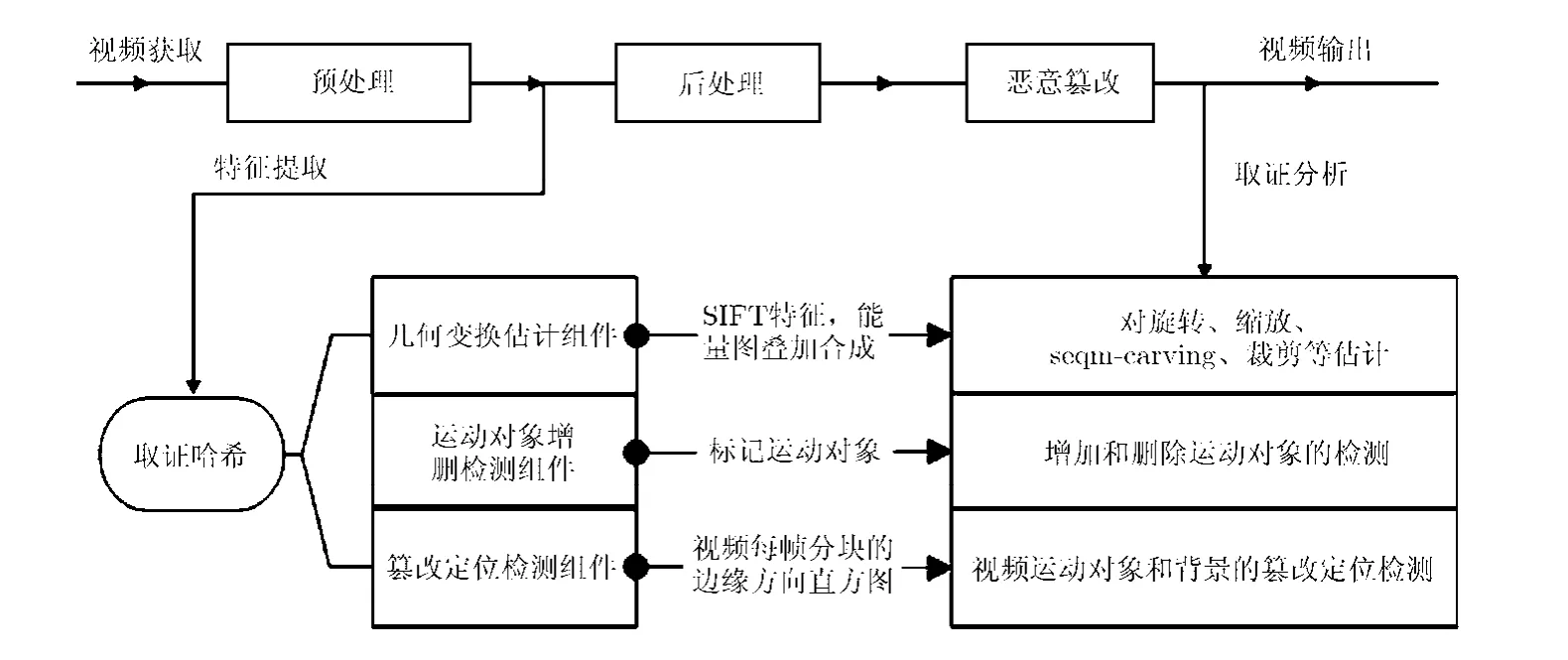
图1 视频取证哈希框架
2.1.1 几何变换估计组件 几何变换估计是指对待测视频的旋转、缩放等几何变换和基于 seam-carving的感知缩放位置进行恢复。在位置、尺度和角度相同的条件下,通过对比原始视频和可疑视频,进行深层次的取证分析。构建几何变换估计组件首先要选取特征点。根据SIFT, SURF和PCA-SIFT各自的特点,在大部分视频哈希中,多采用 SURF或PCA-SIFT[11]作为视频特征点生成哈希,原因在于:SURF和PCA-SIFT的描述符数据量和运算速度优于SIFT,更符合视频数据量大,复杂度高的自然特征;但根据几何变换组件的构建目标,几何变换恢复的准确性应该最先考虑,由于 SIFT匹配的数量足够多且准确率高,因而恢复效果更佳[12]。另外,采用码簿(codebook)可实现SIFT特征点128维描述符的降维[13],此处利用 SIFT作为特征点更能满足该组件的要求。SIFT点的128维描述符,用于判断SIFT点是否相似,但描述符数据量较大,故在生成几何变换估计组件前,先对原始视频的 SIFT特征点描述符进行分层聚类,将聚类集合表示成码簿用于哈希的紧湊表示。每个 SIFT特征点描述符可用码簿中的编码所表示,此方法类似文本检索。码簿由数据发送者和接收者共享,只需生成一次就可以在以后每次的检测中使用。
将原始视频序列V的第1帧定义为I,提取I中SIFT响应值在0.05以上[6]的所有特征点,响应值越大特征点越稳定,数量也越少。然后利用码簿将描述符映射成不同的码字,每个码字有1个对应的ID。每个SIFT点除描述符外还有相应的尺度ρ,方向θ和图像中的位置x和y,这 4个量可用来对几何变换进行估计,所以最终1个SIFT特征点可表示为一个5维向量Si( ID,x,y,ρ,θ),几何变换估计组件哈希则为h1={S1,S2,… ,Si, … ,Sn},其中Si表示I中第i个SIFT特征点向量。在1000个码字组成的码簿中,每个Si需要大约50 bit,相比文献[14]利用1000 bit只能生成5~10个SIFT特征点,此方法提升了哈希的紧凑性。
2.1.2 运动对象增删检测组件 运动对象的增加和删除是一种常见的视频篡改方式,出于对背景静止视频只有运动对象在变,背景不变的考虑,可将运动对象与背景分别用1和0的比特位进行标记。该组件生成的哈希为一串比特流,检测时复杂度低,易于判断视频中运动对象的增加和删除,具体方法见2.2.2节。
首先, 根据文献[15],对视频所有帧在x-t方向使用prewitt算子,提取运动对象,如式(1)和式(2):
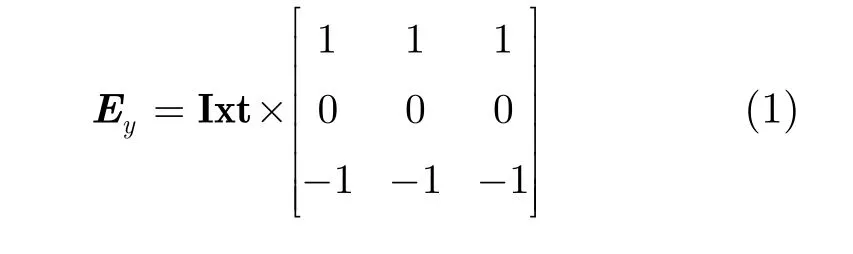
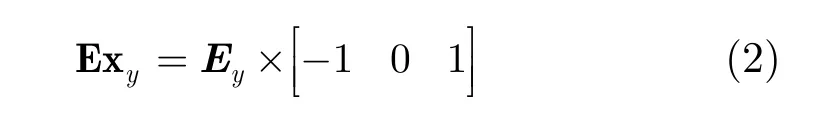
其中y= { 1 ,2,… , r ow},row表示帧图像的行数,Ixt表示视频所有帧在x-t方向像素构成的图像,共row幅,Ey和Exy表示Ixt利用prewitt算子所求的垂直方向能量图和总能量图,再生成视频的总能量图,即E=[E x1; E x2; … ; E xrow]。该方法能有效地提取出每帧运动对象的能量边缘,如图2所示。
然后,利用最大似然估计确定每帧各自的阈值。将生成的能量图分割成大小为N×N不重叠的块,以当前帧所有分块均方差的集合为估计总体S,求得最大似然估计值作为当前帧的阈值,如式(3)所描述。
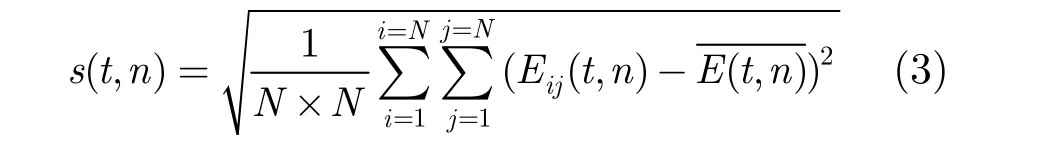
其中s(t,n)表示第t帧的第n个分块的均方差,Eij(t,n)表示每个像素的能量值,i和j表示当前分块中的行和列,表示分块能量均值。
最后,大于当前帧阈值的区域标记为 1,表示运动对象,否则用0标记表示背景,所有分块的比特标记编码成运动对象增删检测组件h2。因为从时间轴方向上看,若该分块位置在所有帧上都为背景,则该分块全部为 0,其它分块位置也一样,时间轴上连续1和连续0比较多,所以若h2采用游程编码(run length coding),能提高哈希长度的压缩效率。
2.1.3 篡改定位检测组件 视频恶意篡改的目的就是为了改变视频所表达的含义,背景和运动对象的变化都会直接导致视频内容发生变化,所以对视频篡改进行定位才能灵活地区分视频中可信和不可信的部分,这更有利于取证分析的进行,此组件就是从该角度出发。

图2 视频各帧中在x-t方向上prewitt算子提取的能量图
文献[5]和文献[14]说明采用分块边缘方向直方图的方法能有效地对篡改进行检测,该方法拥有较好的紧凑性,对尺度和旋转变换具有鲁棒性。本文同样采用边缘方向直方图的方法[5],将像素梯度方向非均匀量化到 4 个方向[0°, 45°, 90°, 135°]并计算分块的方向直方图。但是,在哈希h3的生成过程中,将背景和前景分开考虑,见图 3。首先,生成背景的方向直方图,将视频每一帧同一分块位置上h2中标记为0的块的方向直方图提取出来,剔除该分块位置上偏差较大的帧分块,求剩余该位置分块的平均方向直方图。如果遇到特殊情况,即该分块位置上每帧的标记都为 1,则此分块的背景方向直方图各方向全为 0,待进一步在运动对象边缘方向直方图中检测。接着,依次对h2中标记为1的运动对象的位置生成方向直方图。这样,由背景和运动对象两组方向直方图组合为哈希h3。背景和运动对象分开生成边缘方向直方图,使哈希更紧凑,因为对于背景来说,只用生成一组背景边缘方向直方图,且能检测所有帧背景是否发生了修改。
2.1.4 哈希的可伸缩性 如果确定视频没有进行几何变换,可以不需要h1中的参数ρ和θ;如果确定视频没有进行seam-carving的重缩放,可以不需要位置参数;如果只需要对运动对象进行检测,可以只生成h2;如果针对其它篡改手段添加新的组件,搭建的框架同样适用。
2.2 视频取证哈希篡改估计方法


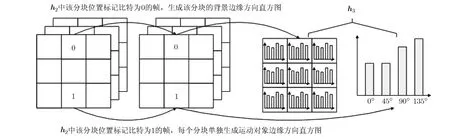
图3 生成h3中各分块边缘方向直方图
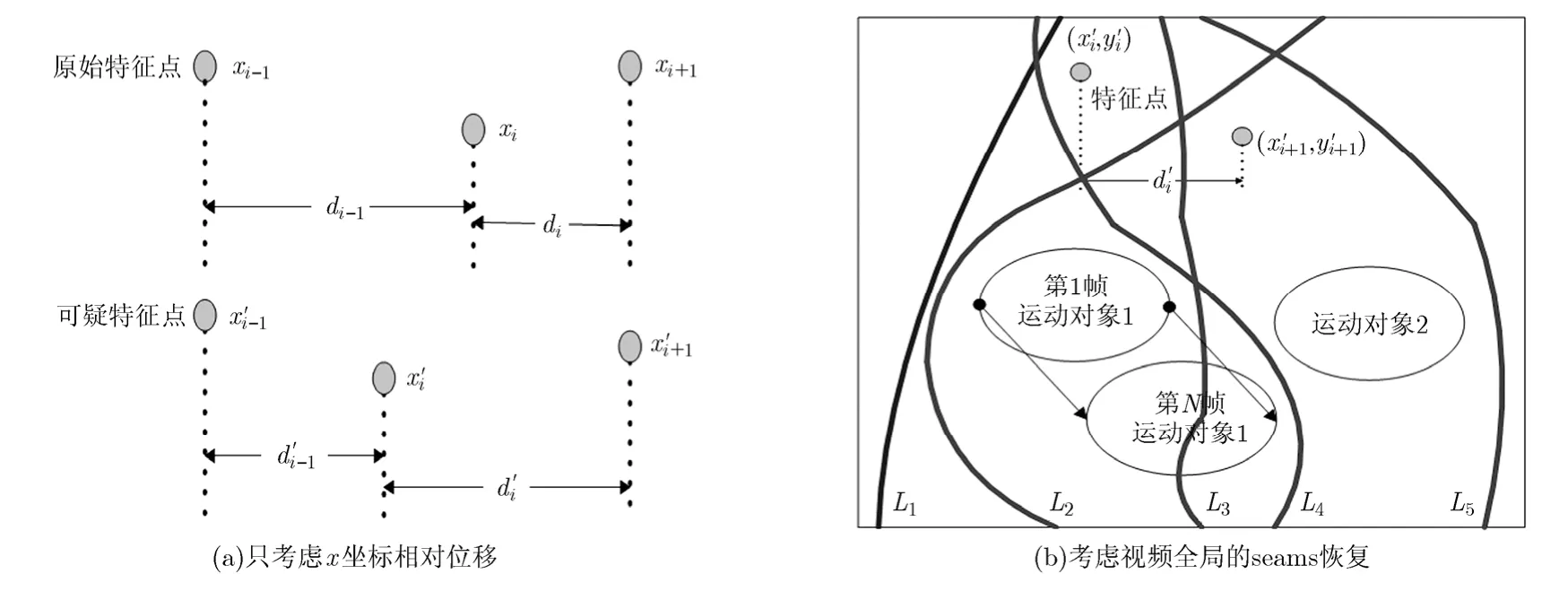
图4 seams的估计与恢复
视频中最引人注目的必定是运动对象,seamcarving视频感知缩放需要在保持运动对象时域一致的情况下进行。图4(b)中,曲线L2是唯一符合要求的seam,只要增加两个约束就可很好地恢复视频的seams变化。一是恢复的seams不经过所有帧的运动对象。图5是将所有帧按时间轴方向叠加,只要seams恢复时不经过该能量叠加图中白色部分即可,图中白色部分为运动对象的能量边缘;二是seams恢复的位置,应该在每行有所约束。

图5 视频各帧中运动对象叠加图
几何变换估计组件能很好地估计视频几何变换和seam-carving感知缩放的操作历史,若需要对视频的裁剪(cropping)进行检测,该方法也是可行的,直接利用位置信息即可检测到。

2.2.3 视频篡改定位分析h3和都包含了背景边缘方向直方图和运动对象分块边缘方向直方图。首先比较背景边缘方向直方图,通过对应分块直方图的欧氏距离来判定该位置是否被篡改,如式(4)所示。
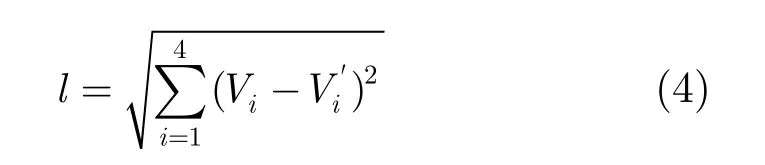
其中Vi和表示某分块的边缘方向直方图量化值,i表示量化的4个方向的索引值。
为了提高运算效率,对于运动对象分块边缘方向直方图,在运动对象增删检测的基础上,只对h2和中标记比特相同且都为1的分块位置进行篡改定位检测。同样,根据哈希对应分块的欧氏距离判别该位置是否被篡改。欧氏距离大于阈值的表示分块直方图所对应的分块不相似,该分块可能被篡改。
3 实验结果及分析
选取背景静止的视频进行预处理,且分成小段视频序列,实验在小段视频序列中进行。视频大小为480×360生成下列4类篡改视频:
(1)验证几何变换估计组件的性能 先将原始视频生成5种seam-carving感知缩放尺寸的篡改视频,分别为原始尺寸的80%(见图6),90%, 110%和120%, 150%(要防止视频的Jittery效应,还无法进行过大的视频seam-carving删除[10]),然后进行几何变换,分别将它们旋转3°, 10°, 15°, 45°和90°,尺度缩放因数为0.5, 0.8, 1.2, 1.5。
(2)运动对象增删检测 添加的运动对象来自同源视频,将视频解码成连续的单帧图像,将运动对象逐帧覆盖视频背景中对应区域,该方法虽然复杂,但对视频质量影响较小,如图 7(a);类似,在背景上添加静止的小车的视频如图7(b)所示。
3.1 视频几何变换估计与恢复
几何变换估计结果如表1所示。可以看出,估计的结果比较理想,旋转估计平均错误在0.5°以下,尺度因数估计平均错误不到1%。几何变换不能完全恢复原始视频的原因在于:特征点虽然经过了RANSAC提纯,但仍可能存在误匹配点,并且特征点的尺度和方向也不能完全精准地估计出几何变换的参数。

图6 seam-carving感知缩放为原始尺寸80%的视频帧

图7 视频帧的篡改
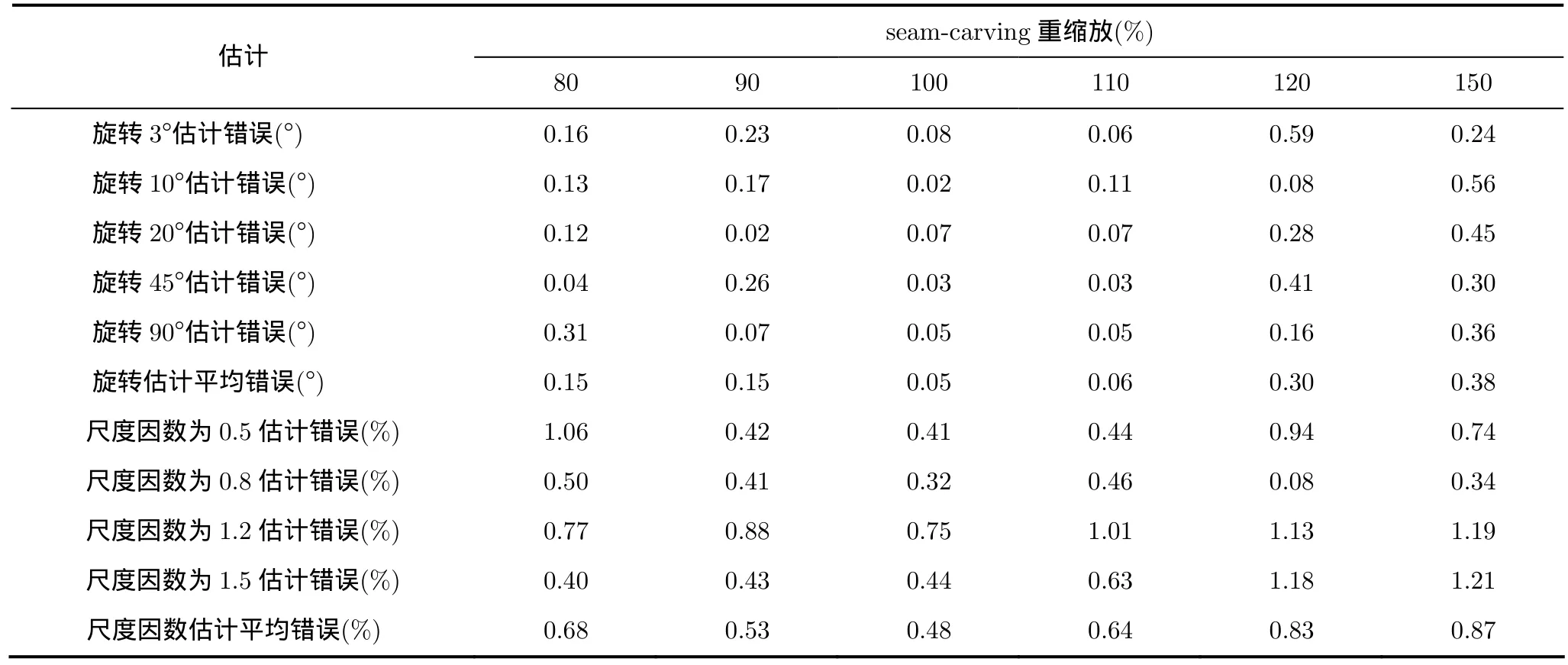
表1 取证哈希的几何变换估计
图8是视频第50和100帧seam-carving恢复的情况。从图 8(a)中可以看到,直接以图像取证哈希的方式恢复 seams会造成运动对象产生 Jittery现象,而本文方法考虑了视频全局,从而保持了运动对象的一致性,同时提高了seams恢复的准确性,如图8(b)所示。为了定量比较两种方法进行恢复的正确率,定义:
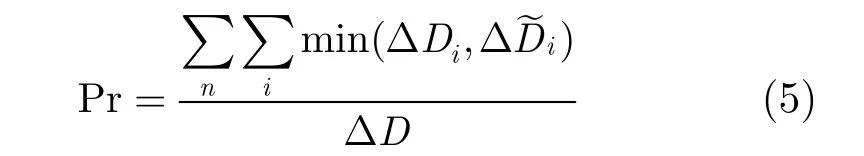
其中ΔDi表示实际两相邻特征点的 seams像素数量,ΔD˜i表示两种方法检测得到的seams像素数量,n表示视频序列的帧数。结果为:将文献[6]的图像取证哈希方法直接扩展到视频时,恢复的正确率为68.75%,而本文方法的正确率为84.01%。
3.2 运动对象增删检测结果
选取分块尺寸N=32,对运动对象的检测结果如图9所示。灰白色的区域为所添加的运动对象,与原始视频帧(图 2(a))比较可知,该方法能比较完整地检测出添加运动对象的位置。但是,由于不能精确定位运动对象的边缘,在运动边缘处会产生误判。当然,对于运动对象删除的情况,检测的结果也大致一样。
为了讨论该组件的检测准确性,定义该组件的漏检率PFN和误检率PFP如下:

图8 视频帧seam-carving恢复

图9 视频添加运动对象的检测结果
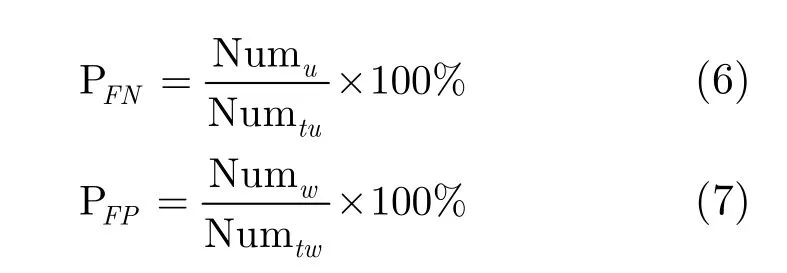
其中Numu表示每帧篡改区域中未检测出的像素数量,Numw表示每帧可信区域中误判为篡改的像素数量,Numtu表示每帧中篡改区域的像素数量,Numtw表示每帧中可信区域的像素数量,实验共有500帧图像。从图10中可以看出,该组件对运动对象增删的漏检率不到3%,误检率不到10%。
3.3 篡改定位检测结果
因为篡改定位的精度要求更高,采用分块尺寸N=16生成边缘方向直方图,各直方图归一化后判决阈值为0.05的实验结果比较理想。如图 11(a)所示,修改视频某处篡改定位效果相当好,出现误判的位置是因为背景的平均边缘方向直方图有量化误差,但这不影响对篡改定位结果的判断。相比文献[14]所提方法,本文算法在误检率不到8%时,正确率达到90%,如图11(b)所示,说明该组件具有良好的检测性能。之所以检测正确率有误差,主要是因为少量被篡改块中的像素没有使边缘直方图发生显著变化。
4 结束语
结合几种视频篡改操作的特点,通过构造取证哈希组件,提出了一种基于取证哈希的视频主动取证方法。它以模块化的方式构建,且具有可伸缩性,能够根据取证的要求调整取证哈希的长度。实验结果表明,提出的视频取证哈希能够有效地估计静止背景的原始视频可能经历的篡改方式,实现了更深层次的取证。进一步的研究将考虑如何将现有的哈希组件运用到运动背景的视频中,并且针对基于帧的视频操作,包括添加/删除视频和帧重组,构造相应的帧操作取证哈希组件,使本文的取证框架能够同时实现帧操作的取证。此外,希望通过对不同篡改方式所遗留的混淆处理效应进行分离,并借助处理链模型,估计视频处理历史,更好地还原视频编辑处理过程。
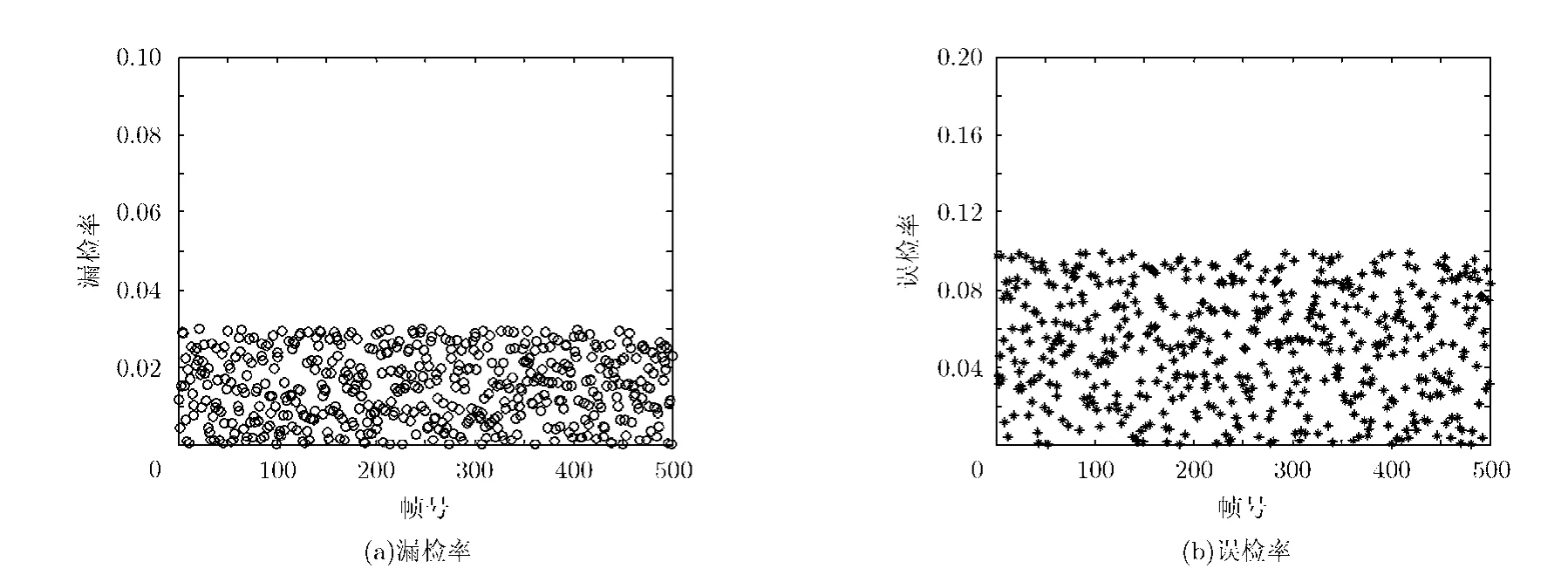
图10 运动对象增删检测的漏检率和误检率
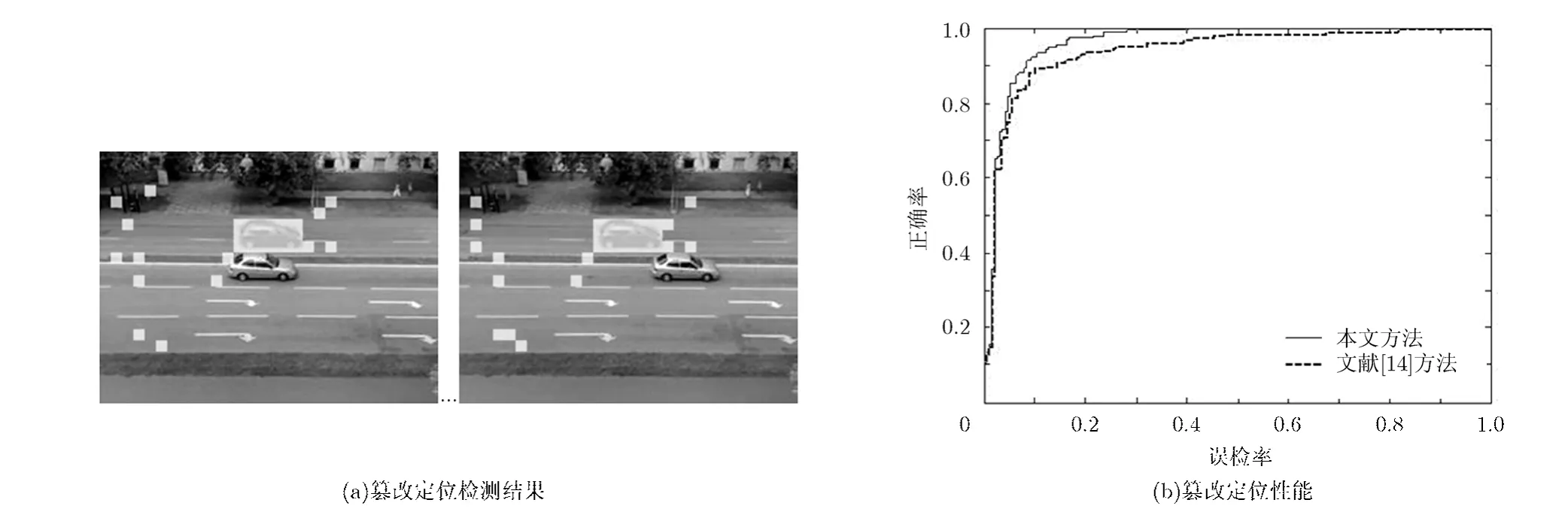
图11 篡改定位检测
[1] Milani S, Fontani M, Bestagini P,et al.. An overview on video forensic[J].APSIPA Transactions on Signal and Information Processing, 2012, 1(e2): 1-18.
[2] Kang Xin-gui, Li Yinxiang, Qu Zhenhua,et al.. Enhancing source camera identification performance with a camera reference phase sensor pattern noise[J].IEEE Transactions on Information Forensics and Security, 2012, 7(2): 393-402.
[3] Wang W H and Farid H. Exposing digital forgeries in ballistic motion[J].IEEE Transactions on Information Forensics and Security, 2012, 7(1): 283-296.
[4] Dong Q, Yang G, and Zhu N. A MCEA based passive forensics scheme for detecting frame-based video tampering[J].Digital Investigation, 2012, 9(2): 151-159.
[5] Lu W, Varna A L, and Wu M. Forensic hash for multimedia information[J]. Proceedings of the SPIE on Media Forensic and Security, 2010, 7541: 39-48.
[6] Lu W, Varna A L, and Wu M. Multimedia forensic hash based on visual words[C]. Proceedings of 2010 IEEE 17th International Conference on Image Processing, Hong Kong,2010: 989-992.
[7] Lowe D. Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision, 2004,60(2): 91-110.
[8] Wang X, Xue J, Zheng Z,et al.. Image forensic signature for content authenticity analysis[J].Journal of VisualCommunication and Image Representation, 2012, 23(5):782-797.
[9] Zhao W, Gong S, Liu C,et al.. Adaptive Harris corner detection algorithm[J].Computer Engineering, 2008, 34(10):212-214.
[10] Rubinstein M, Shamir A, and Avidan S. Improved seam carving for video retargeting[J].ACM Transactions on Graphics, 2008, 27(3): 1-9.
[11] Yang G, Chen N, and Jiang Q. A robust hashing algorithm based on SURF for video copy detection[J].Computers and Security, 2012, 31(1): 33-39.
[12] Juan Luo and Gwun O. A comparison of SIFT, PCA-SIFT and SURF[J].International Journal of Image Processing,2009, 3(4): 143-152.
[13] Csurka G, Dance C R, Fan L,et al.. Visual categorization with bags of keypoints[C]. Proceedings of ECCV Workshop on Statistical Learning in Computer Vision, 2004: 1-22.
[14] Roy S and Sun Q. Robust hash for detecting and localizing image tampering[C]. Proceedings of IEEE International Conference on Image Processing. Singapore, 2007, Vol.6:117-120.
[15] Slot K and Truelsen R. Content-aware video editing in the temporal domain[D]. [Master dissertation]. Department of Computer Science, Copenhagen University, 2008.
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
房地产导刊(2022年4期)2022-04-19
电脑爱好者(2020年20期)2020-10-22
山东农业工程学院学报(2020年12期)2020-03-19
摄影之友(影像视觉)(2018年12期)2019-01-28
初中生世界·八年级(2017年3期)2017-03-24
湖州师范学院学报(2016年2期)2016-08-21
潍坊学院学报(2016年6期)2016-04-18
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年13期)2015-09-10

- 电子与信息学报的其它文章
- 基于Clean处理的MIMO-SAR正交波形分离