
后缀树算法在舆情聚类中的应用
2012-12-26 06:59:00彭静,翟英,冯爽
河北科技大学学报 2012年1期
彭 静,翟 英,冯 爽
(1.河北科技大学信息科学与工程学院,河北石家庄 050018;2.河北经贸大学信息技术学院,河北石家庄 050061;3.河北科技大学教务处,河北石家庄 050018)
后缀树算法在舆情聚类中的应用
彭 静1,翟 英2,冯 爽3
(1.河北科技大学信息科学与工程学院,河北石家庄 050018;2.河北经贸大学信息技术学院,河北石家庄 050061;3.河北科技大学教务处,河北石家庄 050018)
针对网络舆情分析的需求背景,研究了通过后缀树算法发现文本文档之间的公共短语串,按公共短语串实现文档聚类。网页文档的标题和摘要能代表文档的主要思想,应用后缀树算法实现对标题和摘要自动聚类,从而实现舆情信息自动聚类。
网络舆情;后缀树算法;文本聚类
在网络舆情监控系统中,包括舆情采集、舆情存储、舆情分析和结果显示4个主要模块。舆情采集和存储模块对指定的网页进行抓取、解析、中文分词,按关键词索引并存储在舆情数据库;舆情分析和显示模块实现根据关键词进行舆情搜索并对搜索结果自动聚类显示[1]。
舆情聚类的过程是实时的,为了提高速度,并不是对整个网页文档的全部内容聚类,而是提取关键内容:文档标题、文档摘要、文档URL。文档摘要能够全面准确地反映文档的简单连贯的短文,比较准确地体现文档的主题[2],摘要提取本文不做讨论。舆情分析模块可以按标题、摘要和URL自动聚类。文档标题和文档摘要都看做短文本文档,研究应用后缀树算法实现短文本文档的自动聚类[3]。
1 后缀及后缀树定义
1.1 后缀定义
给定长度为n的字符串S=S1S2…Si…Sn,子串SiSi+1…Sn都是字符串S从i开始的后缀,记为S[i,…,n]。以字符串S=abab为例,它的长度为4,所以S[1,…,4],S[2,…,4],… ,S[4,…,4]都是S的后缀,空字串$也是后缀,字符串S后缀分别是:abab,bab,ab,b,$(空字串)。包含这个字符串的所有后缀的压缩 Trie[4],就是字符串S的后缀树。
1.2 后缀树定义
一个具有n个字符的字符串S的后缀树T,就是一个包含1个根节点的有向树,该树恰好带有n个叶子,这些叶子被赋予从1到n的标号。除了根节点以外的每一个内部节点,都至少有2个子节点,而且每条边都用S的一个非空子串来标志。出自同一节点的任意两条边的标志不会以相同的词开始。后缀树的关键特征是:对于任何叶子i,从根节点到该叶子所经历的边的所有标志串联起来后恰好拼出S的从i位置开始的后缀,即S[i,…,n]。把树中节点标志为从根到该节点的所有边的标志进行串联[5],如图1表示字符串S=abab的后缀树。
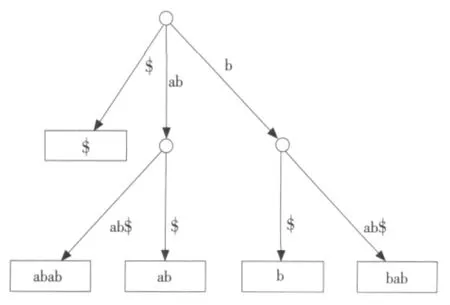
图1 字符串S=abab的后缀树Fig.1 Suffix tree of string“abab”
2 后缀树算法实现文档聚类
2.1 文档表示为后缀树[6]
有3篇英文文档,其内容分别为cat ate cheese,mouse ate cheese too,cat ate mouse too,在英文文档中,以空格分隔单词,文档中连续的多个单词为有一定含义的单词串,以下称为短语,短语能反映文档的含义,文档由多个短语构成。以这3个文档构建1棵后缀树如图2所示。
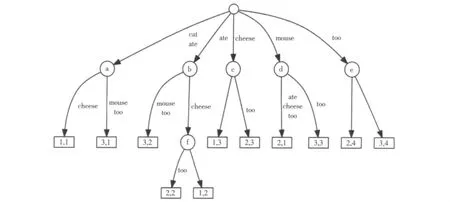
图2 文档的后缀树表示Fig.2 Suffix tree of documents
树中有10个叶子节点,每个叶子节点用一个二元组来表示,如叶子节点3,1表示第3个文档,从位置1开始的后缀“cat ate mouse too”。a,b,c,d,e,f为内部节点,从根节点到内部节点的短语在多个句子中被包含,这个单词串称为短语,比如内部节点a,从根节点到a节点的边为短语“cat ate”,称节点a的短语为“cat ate”。从a节点出发有2个叶子节点和,那么包含“cat ate”短语的文档有文档1和文档3,后缀树节点、短语和包含短语的文档之间的关系如表1所示。
如果2个文档含有多个相同短语,说明这2个文档相似。通过计算得到文档之间的相似度,超过一定阈值,文档聚为一类。
2.2 应用后缀树实现文档聚类的步骤
1)文档解析:这一步骤主要实现对文档分词,比如文档1的内容是“cat ate cheese”,以空格为分隔符,分解为3个单词cat,ate,cheese。
2)文档表示为后缀树,按短语进行文档聚类:表1中所示的节点a对应的短语“cat ate”,文档1和文档3含有该短语,文档1和文档3聚类为1个基类。每个聚类后的基类通过计算得到1个值,值较高(超过一定阈值)的再进行步骤3)。
3)基类的合并,第2步得到的基类合并为更大的文档聚类。
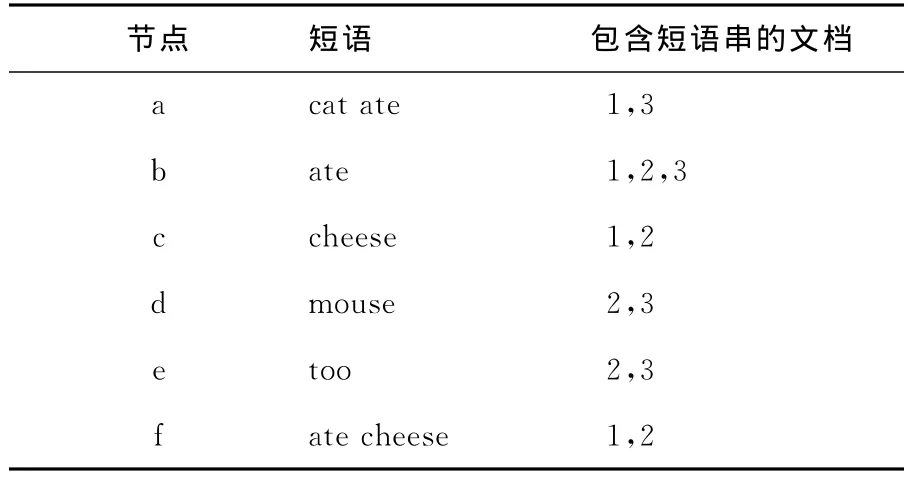
表1 后缀树节点、短语及文档之间的关系Tab.1 Suffix tree nodes,prases and documents

在步骤2)中按短语进行文档聚类,聚类的效果用一个分值来评价,这个分值相当于通常的文本分类的相似度,这里用S(m)来表示:式中:tf(w i,d)是w i在文档d中出现的次数即词频;N是文档集合中文档的总数;df(w i)是w i所在文档的个数。
第3步是基类的合并,在第2步中,确定了含有共同短语的为1个基类,然而1个文档中包含多个短语,因此不同基类中包含的文档可能是重叠的,比如c节点的短语聚类有文档1和文档2,f节点的短语聚类也包含文档1和文档2,STC算法的第3步是把不同的基类(有重叠或交叉的文档经过计算相似度超过一定阈值)合并成更大的聚类。
定义相互交叉或重叠的2个短语聚类之间的相似度用sim(mi,mj)表示,其值为
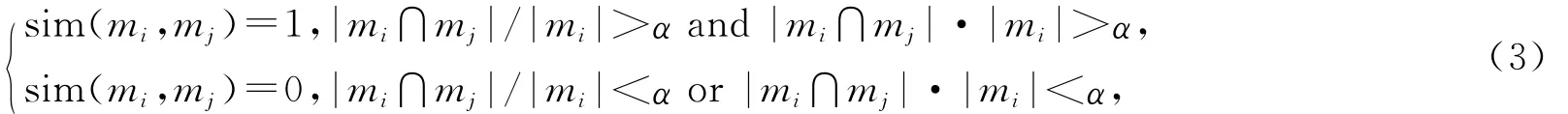
α取值在0~1之间,通常取0.7。
在表1的基础上计算所有短语聚类的相似度,α取值分别为0.7的时候,合并基类的结果见图3,聚类结果的表格形式见表2。
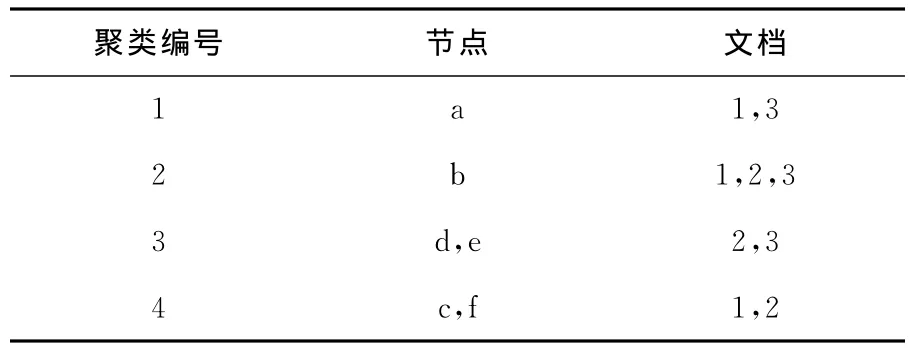
表2 短语聚类的合并结果Tab.2 Clusters identified by the phrase cluster
3 实验结果及分析
聚类的数据源采用通过雅虎搜索的100篇关于“核爆炸”的网页文档。提取标题、摘要、URL,结果用XML文档格式表示[7]。
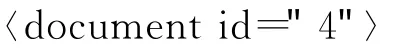
图3 短语聚类结果Fig.3 Phrase cluster graph
众所周知,火星因富含氧化铁的沙土呈现迷人的红色。但最新科学研究发现,这颗行星并非生来如此。据英国《每日邮报》4月2日的报道,一名俄罗斯科学家日前指出,巨大的核爆炸是火星如今呈现红色的真正原因,他还声称我们居住的地球在未来也可能会同样地“变脸”。

应用后缀树算法对标题和摘要自动聚类的结果如表3所示,聚类处理时间1 500 ms。

表3 网页文档聚类结果Tab.3 Clusters of web document
4 结 语
结合网络舆情分析的应用背景,研究了后缀树算法。通过对文本文档建立后缀树,发现文档之间的公共短语串,实现文本文档的聚类,不需要中文分词,公共短语串比公共关键词更能体现文档之间的相似度。在舆情监控系统中,对Web文档的摘要、标题和URL应用后缀树模型实现聚类,相当于对短文档聚类,可以大大提高速度,有助于快速准确地发现舆情热点,为进一步实现话题跟踪打下基础。
[1]汤寒青,王汉军.改进的K-means算法在网络舆情分析中的应用[J].计算机系统应用(Computer Systems and Applications),2011,20(3):165-168.
[2]廉 捷,刘 云.网络舆情中的信息预处理与自动摘要算法[J].北京交通大学学报(Journal of Beijing Jiaotong University),2010,34(5):94-99.
[3]郭 莉,张 吉,谭建龙.基于后缀树模型的文本实时分类系统的研究和实现[J].中文信息学报(Journal of Chinese Information Processing),2005,19(5):16-23.
[4]GUO Xi,YANG Xiao-chun,YU Ge,et al.Choosing meaningful structure data for improving web search[J].Journal of Southeast University(English Edition),2008,24(3):243-246.
[5]UKKONEN E.On-line construction of suffix trees[J].Algorithmica,1995,14(3):249-260.
[6]ZAMIR O E.Clustering Web docaments:A phrase-based method for grouping search engine results[D].Washington:University of Washington,1999.
[7]SONG Ming-qiu,WU Xin-tao.Content extraction from Web pagesbased on Chinese punctuation number[A].International Conference on Wireless Communications,Networking and Mobile Computing[C].Shanghai:[s.n.],2007.5 573-5 575.
Application of STC algorithm to internet public opinions clustering
PENG Jing1,ZHAI Ying2,FENG Shuang3
(1.College of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China;2.College of Information Technology,Hebei University of Economics and Bussiness,Shijiazhuang Hebei 050061,China;3.Department of Teaching Affairs,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China)
In answer to the requirement of internet opinions analysis,this paper discusses the STC algorithm for text clustering,in order to discover common phrases that can assign documents and form document clusters.Because web document titles and abstracts can express the main ideas,web document clusters are created by STC algorithm,and clusters of internet public opinions information are created by using this method.
internet public opinions;STC algorithm;text clustering
TP391.1
A
1008-1542(2012)01-0065-04
2011-06-27;
2011-11-17;责任编辑:陈书欣
河北省科技支撑计划项目(10213557)
彭 静(1970-),女,河北定州人,副教授,硕士,主要从事文本挖掘方面的研究。
猜你喜欢
电子技术与软件工程(2021年6期)2021-11-21 01:24:53
现代语文(2016年21期)2016-05-25 13:13:35
电脑知识与技术(2016年9期)2016-05-18 11:15:21
意林(绘英语)(2016年5期)2016-04-09 10:55:20
辽金历史与考古(2016年0期)2016-02-02 01:34:10
服装学报(2015年1期)2015-10-21 01:20:30
现代计算机(2015年15期)2015-09-18 01:22:19
电子与信息学报(2015年2期)2015-07-18 12:04:47
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
