
基于DBSCAN的最优密度文本聚类算法
2012-11-30 03:18:36袁津生
计算机工程与设计 2012年4期
李 群,袁津生
(北京林业大学 信息学院,北京100083)
0 引 言
目前大多数的搜索引擎使用的是基于关键词匹配的全文检索技术,国内著名的百度和国外著名的Google等就是采用这种检索方式,它的特点是查全率较高。随着互联网上承载信息量的日益加大,它的缺点也越来越明显:
(1)全文检索搜索引擎当用户输入关键词后,通常在返回用户需要网页的同时,还会返回大量冗余的信息,其主要原因是在通常情况下很多的网页描述的都是一个内容。例如当日的新闻就有很多的网站都进行转载,结果导致出现大量的网页重复,因此在查询时也就出现很多相同的结果。
(2)全文检索搜索引擎是通过关键词条对全文的内容进行匹配来达到查询目的。这种检索方式的主要的缺点是参与匹配的关键词条有时候可能出现二义性,导致查询的结果只有具体字面的意思,而不一定是词条本身所要表达的含义。因此这样的检索就会出现查非所查、检非所检的结果。
(3)全文检索搜索引擎缺乏人性化方面的设计,信息的查询仅由用户输入的关键词来决定,而没有更进一步的“人机交流”,这也是导致检索效果不尽人意的一个原因。
我们希望在使用搜索引擎查询信息的时,可通过人机交互的方法,使得搜索引擎逐渐接近于人的思维,以此来提高检索的有效性和查询精度。
通过文本聚类技术能挖掘词条间相互联系的诸多信息,这些信息对于考察用户的查询意图,为用户提供更加准确更加全面的查询结果有很大帮助。通过聚类对同主题文档进行合并、冗余消除、信息融合、消除词义二义性等。
本文提出了一种动态求解的最优密度聚类算法并加以实现。该算法采用密度聚类算法DBSCAN与层次聚类算法BIRCH(balanced iterative reducing and clustering using hierarchies)相结合的方法,构建了一颗簇关系树,同时对聚类参数ε进行动态求解,以达到参数ε的最优。该算法与其它文本聚类算法相比最大的区别就是查询的结果与用户感兴趣的主题具有很大的相关度,对于二义性的词条有较高的查准率。这样可以用户的搜索范围相对缩小,有利于快速搜索信息。
1 算法比较
1.1 聚类原理分析
聚类方法的设计思路是对一组给定的具体的或抽象的对象或数据集进行分组,每一个独立的分组叫簇,分组要达到的目的是在同一个簇内的对象是相似的,而在不同簇中的对象是不同的。我们可以用 “物以类聚”来形容这种划分。目前已有多种传统的聚类分析算法,本文的讨论仅涉及3种:基于划分的方法、层次聚类方法、基于密度的方法。
1.2 聚类方法介绍
(1)划分方法:基于划分的方法具体细分为K中值算法和K均值算法。K均值算法是一种基于质心的聚类技术,详细的介绍可参见文献 [1]。在需要聚类的数据集非常巨大的情况下,K均值算法处理的聚类效果较好,但该算法的对极端值很敏感,比如一个集合中有一个特别偏离和分散的对象,就会对整个结果造成很大影响。K中值算法对于极端值不敏感,但它的计算量与K均值算法比起来要大得多,更加适用于数据量小的集合。
(2)层次方法:层次聚类方法就是对给定的对象或数据集合进行层次上的分解。详细介绍可参见文献 [2]。该算法可细分为凝聚法和分裂法两种,这两种算法的代表分别是AGNES(agglomerative nesting)算法和DIANA (divisive analysis)算法。它们的分解过程是一个互逆的过程。
凝聚的层次聚类与分裂的层次聚类算法过程如图1所示。
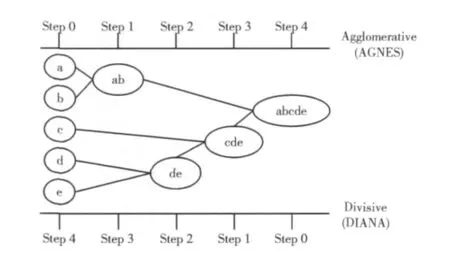
图1 层次聚类
层次方法中有一种典型算法 (BIRCH),是把集合中的对象构造成层次树,用树的结构划分聚类,并根据设定的阈值构建一个聚类特征树,然后在以后的阶段对构建的聚类特征树进行重建,以此来达到更好的聚类目的。
(3)基于密度聚类方法
前面两种算法都是基于对象间距离的考察,适用于发现圆形簇。密度方法可以适用于任意形状的簇。典型的算法是DBSCAN密度聚类算法,该算法是先检索数据集中的核心对象,并建立新簇,然后迭代地聚合其直接密度可达对象,不断重复这个过程到没有新对象加到任何簇完成聚类过程。
DBSCAN算法需要设定两个重要参数:一个是对象半径ε内的邻域;另一个是最小数目的核心对象MinPts[2]。本文将在后面详细讨论关于参数的设定。
1.3 算法比较测试
本文选取了以 “北京林业大学”为关键词并具有不同主题的10个网页进行聚类测试,在本测试中选取了3种算法:K均值法、AGENES算法和DBSCAN算法。测试的网页及其主题如表1所示。

表1 选取的测试网页
我们对这3种算法在相同的条件下进行对比,经过实验测试,得到表2。
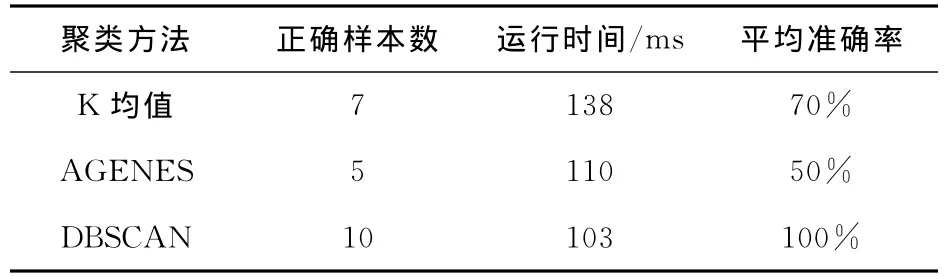
表2 聚类结果对比
表2显示的对3种算法的运行时间和准确率进行了统计,聚类结果对比明显,我们看出K均值算法运行的时间最长,而准确率居中;AGENES聚类算法运行的时间居中,但准确率最低;DBSCAN聚类算法准确率最高,运行时间最短。前两种聚类算法为之所运算的时间较长,是因为它们在运算过程中使用大量的时间进行迭代,复杂度为O (k(n-k)2),最后一种聚类算法DBSCAN的计算复杂度是O(nlogn)。通过上述实验我们得出结论DBSCAN聚类算法优于基于划分和基于层次的聚类算法。
2 最优化密度聚类算法
在上述实验的基础上我们提出一种改进的DBSCAN算法,叫最优化密度聚类算法。DBSCAN聚类算法需要有两个参数ε邻域和MinPts。其中MinPts可选择3、4或者5。而参数ε在对网页进行聚类时是很难确定的。若ε值设定的较大,其结果是得到高密度的簇,也就是说得到的网页相关性就会很高,甚至是完全相同的网页。若ε值设定的较小,其结果是形成低密度的簇,得到的网页相关性就会很低,甚至是完全不相关的网页也聚到了一起。参照以往的经验,ε是在 [0.3,0.9]之间的区间进行变化,变化方向为由大到小,变化幅度为0.1。
参数ε幅度均匀变化并逐渐降低的算法有可能会出现在某个ε邻域内,合并的网页数量太多,即合并了许多噪声对象,也可能会出现在某个ε邻域内网页的数量极少的现象,即仅合并了完全相似的对象。因此,按照固定值的参数ε进行聚类的做法并不可取。针对输入参数ε的设定,本文在此提出一种对参数ε进行动态求解的方法。
2.1 输入参数ε的求解
对输入参数ε的计算需要设定两个参数P和N,其中:P=# (εN)表示人们在通常情况下在点击到最后希望得到的网页的数量;N表示人们在通常情况下能忍受的点击“相关查看”的次数。如图2所示。
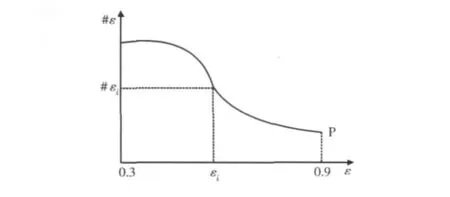
图2 参数求解曲线
在图2中,我们假设用i来表示用户点击相关查看的次数,那么有

根据上面的公式可以得到
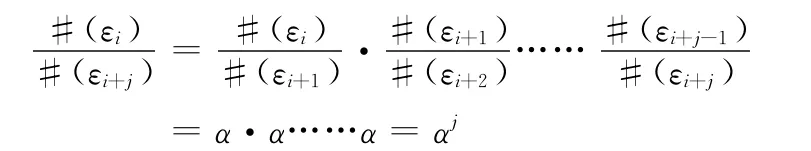
在点击到第N次相关查看后,可以得到公式

一般来说,用户在点击N次之后,期望看到的剩余网页的数量为P,N和P是两个常量,则根据式 (2)有:αN=于是得到公式
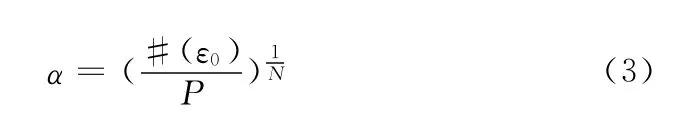
如果出现:# (ε0)<P时,就不需要对网页进行聚类运算了。在通常情况下,# (ε0)>P的。
由式 (3)得到了α,根据α可以求出:#(εi)= #(ε0)·α-i,设ε0=0.3,就可以解出ε1,ε2,……,εi。
使用数据拟合的方法来求解参数ε,在很小的范围内将参数ε的变化用一条下降的直线来代替,这样处理后对参数ε的求解就简化成对这条直线方程的求解,如图3所示。
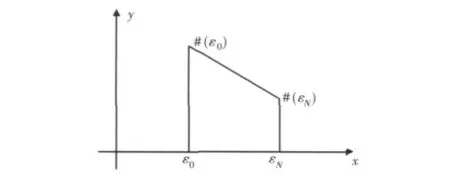
图3 参数求解方程
由图3的曲线可以得到连接ε0和εN的直线方程为
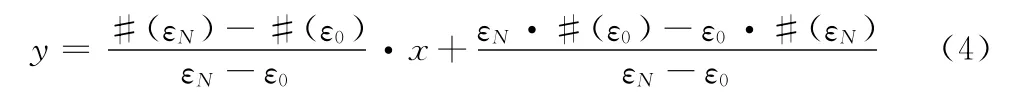
可以求出:y= #(εi)= #(ε0)α-i,对应的x为
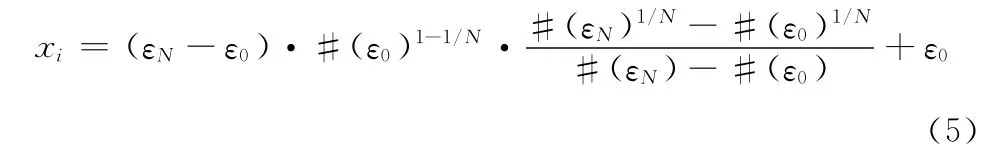
这样,就求解出了xi也就是ε1,ε2,……,εi。
2.2 算法流程
DBSCAN算法中涉及的两个参数ε和MinPts,我们可以将参数ε理解为半径,MinPts是一个限制条件。该算法的目的就是在ε这个半径内查找样本数n,当满足条件n>=MinPts时,就是核心样本点。算法步骤描述:
(1)设定MinPts的值和计算出参数ε的值;
(2)对集合内所有对象依次遍历,确定目标对象result-Object;
(3)查询目标对象的邻域n,对访问过的对象做标记;
(4)如果n是核心对象,就做标记为Key_Object;
(5)如果n是非核心对象,就做标记为Noise_Object;
(6)对核心对象Key_Object进行递归,直到满足设定的初始条件。
对于参数ε的设定,我们可以使用式 (5)来得到;对于聚类方法,我们采用将密度聚类算法DBSCAN与层次聚类算法BIRCH相结合的方法,形成一棵聚类的簇关系树。如图4所示。
由簇关系数图看出,簇2的分枝里包含了簇3、簇4和簇5,但并不一定簇2就完全由簇3、簇4、簇5构成。通常还有一部分在这一层次被定义为噪声的对象。通过关系树,就可以ε的值返回到高层次的聚类,或进一步深入的查询,比如在聚类结果中再进行更深入的查询等,我们将这种簇关系树应用在搜索引擎中可完成不同层次的聚类。增加ε的值就可以得到较高层次的聚类;减少ε的值就可以进入更深层次的聚类。
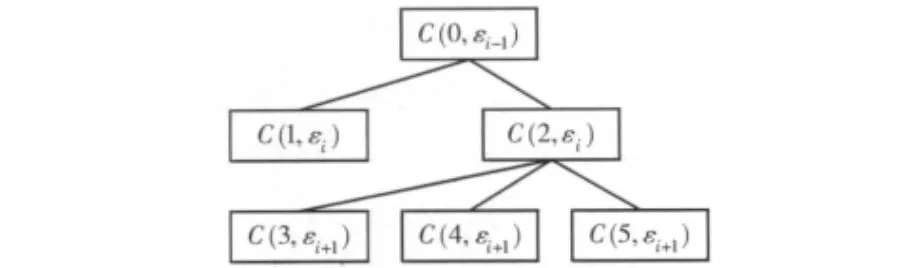
图4 簇关系树
设C为全部簇的集合,则有公式Ci,ε∈C,其中Ci,ε簇指的是i的ε邻域的簇,Oi为簇Ci,ε中包含的全部对象的集合。对于任意Ci,ε存在方法
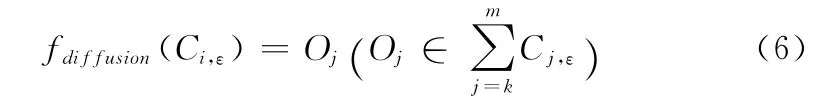
假定当前的层次为εi,若用户查想看更深层次的内容,我们有方法
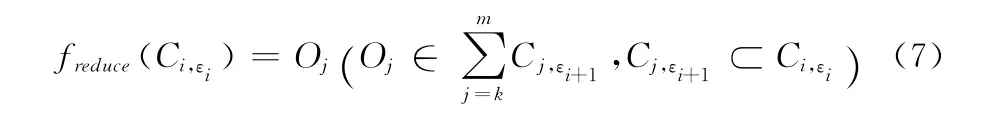
假定当前的层次为εi,若用户查想看更多的内容,我们有方法
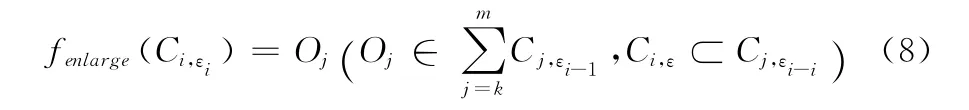
式 (7)是查找找比当前层次更高密度的对象,也就是扩大查询范围;式 (8)是查找比当前层次更低密度的对象,也就是更深入准确定位查询信息。
利用这棵关系树,我们可以设计一个引导机制来完成搜索引擎与用户之间的交互操作,使用户进行更深入、更广泛的信息查询。例如,当用户输入关键词 “日本”后,搜索引擎在返回的结果页面上出现相关的引导按钮,这时,用户根据自己的需求点击此按钮进入到相应的页面,来对查询的信息更准确的定位。
3 性能评价
为了测试算法的性能,本文构建了一个搜索引擎,并选取了一些目前比较热门,关注度比较高的词条。为满足测试的需要,我们抓取了新浪网站上面的国际新闻板块里面的1259个网页,在去掉网页中包含的多媒体信息之后,我们选取两类词来进行验证,一是具有新闻代表性的词“利比亚”、“卡扎非”;另一个是中性词 “土豆”。
我们选择著名搜索引擎百度与在本算法基础上实现的搜索系统进行性能上的对比,主要是对输入关键词后返回的查询结果进行对比分析。由于百度搜索引擎返回的数据量巨大,我们仅选取其搜索结果的前5个页面的数据,如表3所示。
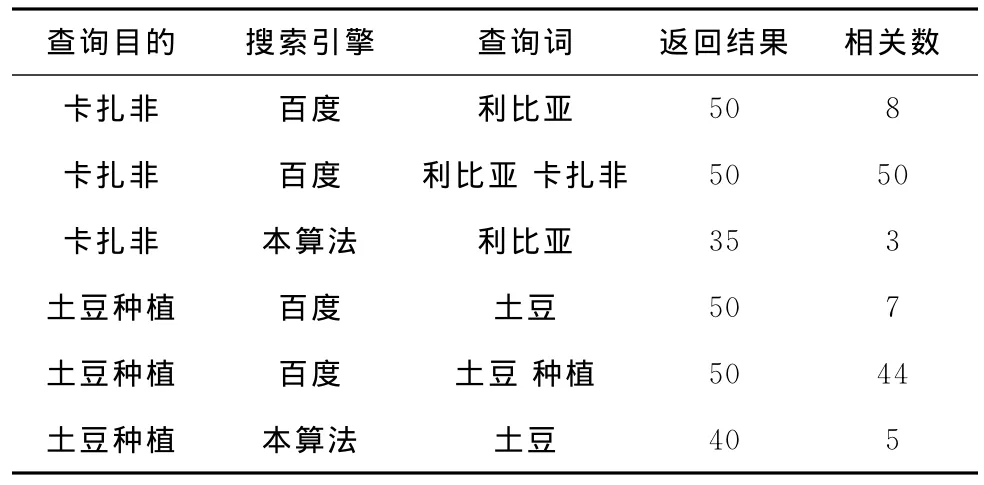
表3 测试结果比较
在表3可以看出,当输入多个关键词的情况下,百度的查准率高些,但如果用户仅输入单一或较少关键词的时候,准确率就不高。实验中我们输入 “利比亚”这个词,目的是希望得到利比亚卡扎非的相关信息。在返回结果栏目下,百度的前50个结果中只有8条是关于卡扎非的信息,若输入 “利比亚 卡扎非”则百度相关数栏目下就达可到50条信息。本算法在返回结果的35条记录中,虽然只有3条,但可以使用 “相关查询”的操作,就能准确定位利比亚卡扎非的有关信息。再比如,我们在百度搜索中输入关键词 “土豆”,返回的前5页中出现的都是土豆网中的内容,有关土豆种植的信息就非常少了。但在本算法中,通过提示按钮,用户就可以得到土豆种植的相关信息了。
综上所述,当用户在能对自己需要查询的信息准确定位,使用的关键词描述精确全面的情况下,百度等搜索引擎查询能得到较好的结果;当用户不能准确定位词条,或输入的关键词具有二义或歧义的情况下,本系统通过改进聚类处理之后得到的结果比较理想。
4 结束语
本文提出了一种动态求解的最优密度聚类算法,并测试了该算法基础上实现的搜索引擎的性能。该算法的关键是对参数ε进行动态求解,以达到参数ε的最优化值,以及将密度聚类与层次聚类相结合形成簇关系树。实验证明该算法可以有效的弥补全文检索算法的不足,提高含义不同词条的查准率。该系统通过人性化的设计加入了 “用户干预”,使得搜索引擎能进一步明确用户的查询意图,去除冗余,返回给用户准确有效的信息。
[1]LIU Yanli,LIU Xiyun.K-means clustering algorithm based on density [J].Computer Engineering and Applications,2007,43(32):153-155 (in Chinese).[刘艳丽,刘希云.一种基于密度的K-均值算法 [J].计算机工程与应用,2007,43 (32):153-155.]
[2]DUAN Mingxiu.Hierarchical clustering algorithm of the researchand application [D].Changsha:Central South University,2009:15-16(in Chinese).[段明秀.层次聚类算法的研究及应用 [D].长沙:中南大学,2009:15-16.]
[3]CAI Yue.A feasible text clustering algorithm of search engine[D].Beijing:Beijing Forestry University,2010:10-13 (in Chinese).[蔡岳.一种应用于搜索引擎的文本聚类算法 [D].北京:北京林业大学,2010:10-13.]
[4]LI Xinliang.Improved research of hierarchical clustering algorithm [J].Software Guide,2007,6 (10):141-142 (in Chinese).[李新良.基于层次聚类算法的改进研究 [J].软件导刊,2007,6 (10):141-142.]
[5]Anagnostopoulos A,Broder A,Punera K.Effective and efficient classification on a search-engine model[J].Knowl Inf Syst,2008,16(2):129-154.
[6]Leung K Wai-Ting,Wilfred Ng,LEE D L.Personalized concept-based clustering of search engine queries [J].IEEE Transactions on Knowledge and Data Engineering,2008,20(11):1505-1518.
[7]LI Xiaoguang. Text clustering approach based on content characteristic[J].Computer Engineering,2007,33 (14):24-26(in Chinese). [李晓光.一种基于内容特性的文本聚类方法[J].计算机工程,2007,33 (14):24-26.]
[8]Mike Thelwall.Quantitative comparisons of search engine results[J].Journal of the American Society for Information Science and Technology,2008,59 (11):1702-1710.
[9]XIAO Zhuocheng,JING Jinhua.User interest based search engine [J].Computer Applications and Software,2007,24 (9):134-136(in Chinese).[肖卓程,荆金华.基于用户兴趣的搜索引擎 [J].计算机应用与软件,2007,24 (9):134-136.]
[10]ZHANG Yulian.Clustering of search engine query log [J].Computer Engineering,2009,35 (1):43-45 (in Chinese).[张玉连.搜索引擎查询日志的聚类 [J].计算机工程,2009,35 (1):43-45.]
[11]Mecca G,Raunich S,Pappalardo A.A new algorithm for clustering search results [J].Data & Knowledge Engineering,2007,62 (3):504-522.
[12]HE Xiaofei,Jhala P.Regularized query classification using search click information[J].Pattern Recognition,2008,41(7):2283-2288.
[13]RU Y,Horowitz E.Automated classification of HTML forms on E-commerce web site [J].Online Information Review,2007,31 (4):451-466.
[14]LIAO Yichun.A weight-based approach to information retrieval and relevance feedback [J].Expert Systems with Applications,2008,35 (1-2):254-261.
[15]LI Qun,HUANG Xinyuan.Research on text clustering algorithms[C].Wuhan,China:Proc of 2nd International Workshop on Database Technology and Applications,2010:734-736.
猜你喜欢
电子制作(2018年10期)2018-08-04 03:24:38
电子测试(2017年15期)2017-12-18 07:19:27
电子制作(2017年2期)2017-05-17 03:54:56
电子测试(2015年18期)2016-01-14 01:22:58
智能系统学报(2015年4期)2015-12-27 09:38:39
中国卫生(2015年12期)2015-11-10 05:13:38
电子设计工程(2015年6期)2015-02-27 12:04:53
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
计算机与网络(2014年7期)2014-03-25 10:57:07
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
