
支持低延迟通信与容错的计算资源共享环境构建
2012-11-30 03:18:22许爱军
计算机工程与设计 2012年4期
许爱军,张 岳
(1.广州铁路职业技术学院 信息工程系,广东 广州510430;2.中国科学院 数学与系统科学研究院,北京100120)
0 引 言
计算资源共享环境 (computing resource sharing environments,CRSE)可以通过中间件软件的方式把各种异构的、多域网络环境下的计算资源充分利用与聚集起来,完成某种分布式的、计算量大的任务的系统[1-5]。目前关于构建广域网或局域网上的CRSE,国内外已经有很多相关的项目,取得了很有价值的研究结果[6-11]。研究表明为了提高CRSE的计算性能,除了高效的任务调度算法外[12],低延迟通信与容错策略也十分重要,同时还必须改进应用的编程模型,扩大CRSE的应用领域。
本文提出与描述的LF-CRSE (low latency and fault tolerance CRSE)也是这种类型的计算资源共享环境。LFCRSE由担任各种不同角色的功能节点自愿的组成,包括客户端节点、任务服务器节点、工作机节点和工作机服务提供器节点等。LF-CRSE和当前的某些项目类似,也是充分运用Java的跨平台特性、对象序列化技术和字节码技术,使LF-CRSR具有跨平台性、通用性和可扩展性。LF-CRSE也有自己的特点:支持低通信延迟、容错特性和分支界限技术 (branch and bound)。分支界限技术能使LF-CRSE支持最基本的主-从 (master-slave)风格的并行计算外,还支持具有数据依赖的分布式旅行商 (travelling salesman problem)问题,这样LF-CRSE的应用范围就大大增加。
通过构造LF-CRSE的测试环境,选择了典型的并行计算问题进行了测试。测试结果表明了LF-CRSE的加速比稳定增加,低延迟通信与容错策略也具有很好的性能。在同等配置的硬件环境条件下,优于当前的一些项目。
1 LF-CRSE的系统结构
1.1 系统概况
根据LF-CRSE的工作机制,承担了4个不同的功能角色。客户端,任务服务器,工作机服务提供器 (Worker service provider)与工作机。
客户端 (Client)首先是用来提交并行计算任务的,这往往是具体的用户或者并行应用程序开发员,同时客户端也负责请求计算的临时结果和返回结果,如果某些应用有图形的显示需求,可以在客户端上开发更加多的界面组件模块。客户端只和工作机服务提供器的组件交互,此时工作机服务提供器都以服务组件代理的形式提供。
工作机服务提供器 (WSP)管理着网络中的任务服务器。例如当一个任务服务器将加入到LF-CRSE平台的时候,它首先和工作机服务提供器通信。WSP将通知新来的任务服务器节点如何加入到合适的任务服务器网络之中。
任务服务器 (Task server)用来存储任务对象。每个任务对象都是已经被划分好的任务但是还没有开始计算,它可以是一种Java字节码的形式,同时包含着一些相关的数据文件与参数。任务服务器可以在内部平衡化即将到达的任务。每个任务服务器的下属有一些工作机依附于它。当一个工作机请求任务执行的时候,任务服务器返回一个任务给工作机,如果工作是空闲的时候,将让其执行。如果工作机出现了异常,任务服务器将重新分配该任务给另外的工作机。
工作机 (Worker)是LF-CRSE中的任务的具体执行者,同时返回任务的临时结果给工作机服务提供器,它的角色类型是愿意提供空闲计算资源的自愿者,一般来说,工作机数目越大,LF-CRSE的计算能力就越强大。
1.2 工作机制
当一个客户端登录到LF-CRSE中时,工作机服务提供器将广播该登录到所有的任务服务器,同时任务服务器也将传递这些广播消息到其下属的所有工作机。当一个客户端离开的时候,工作机服务提供器也广播该离开消息到所有的任务服务器,同时任务服务器汇总资源的消费信息到所有的下属的工作机。这些信息随后会陆续的被收集到工作机服务器中,然后被传递到客户端。目前LF-CRSE平台中任务服务器的网络拓扑结构如图1所示。所有的划分/聚集操作、登录和离开操作都是通过一个任务服务器的网络拓扑维护来完成。
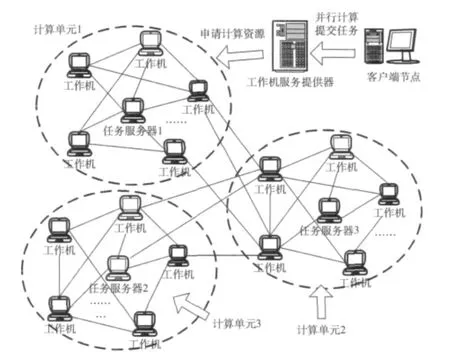
图1 LF-CRSE的工作机制
从图1中看出,该LF-CRSE系统具有3个任务服务器,任务服务器是一种二维的拓扑,每个任务服务器下面依附了5个工作机,该客户端只是和工作机服务提供器交互。任务对象封装了计算过程,任务对象是一种序列化了的Java对象或者可跨平台运行的Java字节码,它们的输入和输出都是通过LF-CRSE平台来管理,任务的执行的个数是随着工作机的增加而提升的,任务对象同时支持对工作机的透明性和任务容错处理。
1.3 应用编程模式
并行分布式计算的任务往往被开发员划分成许多可以并行执行的子任务,任务与子任务之间可以形成一个任务图。应用的任务图中的节点和边分别表示了任务划分的方式 (主从模式或分治模式)、任务之间的数据依赖关系,任务都是通过共享对象来访问的。共享的语义表示了并行计算的上下文,对象的共享是异步与阻塞模式的。这种限制导致了共享在某些情形下不可用。但是通过分支界限模式(branch and bound),LF-CRSE可以处理很多情况下的交互优化问题,LF-CRSE中运用了该技术。
子任务是应用编程接口的核心,它们通过执行Execute方法来封装了计算的细节。Execute方法具有一些环境参数,这个是重点需要考虑的。假设A是一个任务,它有一组输入对象,它返回一个输出对象,该输出对象是下一个任务的输入 (假设为A’),也许A’又被分解成一组子任务,同时返回一个临时结果。最后临时结果的返回值是关于任务A的环境参数。这种任务的分解由一个大的任务划分后完成,任务分解后又有新的子任务产生。独立的子任务可以通过隐式的消息传递完成。它可以改善工作机的利用率,也很方便容错。从这个分析可以看出,任务的关系图对于LF-CRSE是透明的,任务的调度是在执行的时候完成的。
在LF-CRSE中,子任务的访问通过一个通用环境对象完成,通用环境对象是在整个计算过程中的一个只读的输入对象,并且对于共享对象是可变化的。例如当运行TSP分布式旅行商问题的时候,用户可能希望调整距离矩阵到输入对象之中,子任务通过环境中的GetShared()方法来访问共享对象,同时通过SetShared()方法来更改。一个共享对象是实现了Shared的接口,它包括isNewerThan()方法。
虽然共享之间的语义比较虚弱,但是它是适合分布式计算的。当共享对象改变的时候,它的值也被通知出去。当环境中接收到共享对象的新的值的时候,它将通过is-NewerThan()方法来判断它是否比当前的值更新,例如在TSP问题中的旅行的距离就可以作为共享对象。那么当一个新的旅行被发现了后,它的整体距离将被共享。如果提出的整体距离少于当前的最优的旅行距离,在这个情况下isNewerThan()方法将返回True的值。但是在分布式计算中主-从编程模式并不是经常发生这种情形。
2 低延迟通信与容错
2.1 低延迟的处理
LF-CRSE的低延迟通信处理依赖于任务缓存、任务预获取和任务服务器计算等策略。
任务缓存:当任务在划分成为子任务的时候,首先被构造的子任务被下载并缓存在工作机上,计算完成后,根据工作机的需求来请求任务服务器获得下一个任务。任务的缓存的情况是根据应用开发员划分需要来控制的。
任务预获取:并行应用也可以根据任务的预获取来减少通信的延迟。分为显式模式和隐式模式。在显式模式下,如果一个任务再不能划分成子任务则称为原子。子任务类中有一个类型为Boolean的方法isAtomic()来控制。默认的情况下该方法是返回真。当调用子任务的Execute()方法的时候,工作机就需要调用isAtomic()方法,如果返回真,那么工作机在调用任务的Execute()方法的时候,通过另外的线程将预获取另外一个任务。隐式模式:当一个子任务对象的isAtomic()方法的返回值是假,那么程序将跳转到一个新的执行点上,该点处可以保证不需要构造任何的子任务,它又可以调用环境对象中的预获取方法。这样也可以使工作机请求到任务服务器中的另外的线程。
任务的预获取技术覆盖了工作机从当前任务的执行到下一个子任务的请求。这样可以刺激应用开发员:鉴定原子任务类、让工作机的空闲时间尽可能满足每个原子子任务类。
任务服务器计算:如果任务的封装的计算是稍微复杂点的,那么在任务服务器上计算所消耗的时间比在工作机上计算往往要少。这个是因为从任务服务器到工作机,把代码和数据的序列化时间和反序列化的时间代价很大。如果把这些任务直接在任务服务器上计算还可以减少网络的延迟。比较常见的操作,例如求最大值Max,求和Sum都可以在任务服务器上直接执行,而不需要分配到工作机。在实现这个策略的时候,通过一个名称为ExecuteOnServer()的Boolean型方法来完成。
当一个任务准备执行的时候,任务服务器将调用ExecuteOnServer()方法,如果返回为真,任务服务器将在本地执行。该操作由应用程序员在编程的时候自己控制。整体来说通过这些策略保证了LF-CRSE功能节点之间的低延迟通信,减少了任务执行的代价。
2.2 容错的处理
当一个任务服务器探测到某些工作机的异常的时候,工作机上的代理对象可以负责容错,周期性的发送心跳消息给任务服务器,如果任务服务器的通信出现了异常,通过设置一个超时时间间隙和延迟域值,它将试图重新通信一直到成功完成,如果超过了时间间隙,工作机上的代理对象将返回工作机的任务相关的代码和数据,以便用来重新分配任务,随后它将从任务服务器的网络中删除。这就使LF-CRSE在某种程度上具有一定的可靠性。
因为是面向子任务的容错策略,所以LF-CRSE的任务的重新分配代价是比较小的,由于系统支持的主要编程模型是主-从 (Master-Slave)和分治 (divide-and-conquer)模式,节点之间的通信量很小,只要节点有非正常退出,LFCRSE可以给新取代的节点再次分配子任务相关的参数与代码。例如在分布式旅行商的TSP问题中,任务的划分是比较复杂的,只有当前正在执行的任务才需要被重新计算。测试中显示TSP的每个子任务的平均执行时间是2s,重新从失败中恢复的大约时间是1s,这些是代价和整体的运行时间比较是很小的。
3 实验与讨论
3.1 实验环境
LF-CRSE的实验环境的配置是通过某个科研机构的局域网组成,不同的机器担任客户机、工作机服务提供器、工作机和任务服务器的角色。不同的角色的节点上都安装好了LF-CRSE的中间件软件,它们都是Jar包的形式。机器的配置如表1所示。
并行计算的案例程序选择了需要分支界限法的分布式旅行商TSP问题,使用了TSPLIB中的kroB200的数据。为了保证该算法有很好的提高速度,系统设置了最初的上限,运用分支界限技术优化旅游长度,使其达到最小的旅游长度。最后每一轮都搜索同一个搜索树,子任务的平均执行时间大约为2.05s。
3.2 实验过程
在每个实验中,启动了工作机服务提供器,随后启动一个任务服务器,随着后面的任务服务器的加入,它们分别开始聚集大量数目的工作机。整体来说64个工作机,依附于8个任务服务器上,这些机器共同协同与合作来完成一个大的并行计算任务,由客户机上启动TSP的应用,提交到工作机服务器上,如图2所示。
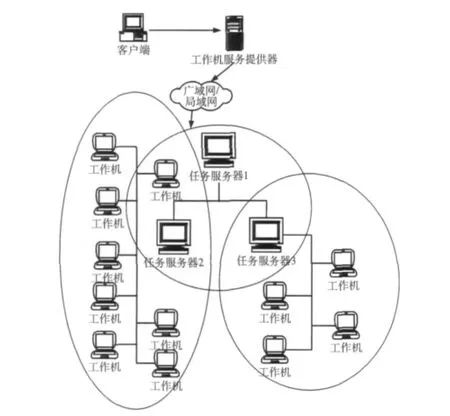
图2 LF-CRSE的网络拓扑结构
应用由可变化的负载组成,它有一些不平衡的任务关系图。整体计算的时间是应用从提交任务到最后接收到汇总子任务结果的输出的时间。LF-CRSE可以通过自动的分支界限技术保证了该应用的递归迭代过程,完成低延迟的通信优化。由于处理器都是双核的,所以如果取的工作机的数目是60,那么就有120个处理器,系统能够获得了一定的速度提高。测试的时间取了3次的平均值。
在容错性能的测试中,LF-CRSE在任务服务器上启动了32个处理器。系统运行1500s后,大约经过了3/4的计算过程后,通过采用手动的方式关闭某些任务服务器。把整体的计算过程的时间记录下来,把它和理想的执行时间进行了比较。
为了测试整个系统中的任务服务器与工作机之间的低延迟通信开销,体现系统的低延迟通信性能,在任务服务器上运行了22个处理器,把它和一个任务服务器和一个处理器的情形进行了比较,该实验也运行了3次,记录了平均值。
3.3 结果讨论
图3中显示了TSP并行案例程序的运行速度测试结果,在功能上,LF-CRSE除了能够很好的完成计算外,还以较快的速度完成了并行计算。在不同的工作机数下,完成相同的子任务的时间明显减少,特别是在工作机的数目达到16个以上后,加速比提高更快。这是由于在LF-CRSE中使用了分支界限技术,可以让新的子任务不停产生,同时利用低延迟的通信使整体完成的时间代价减少。在同等硬件配置条件下,由于任务划分粒度好,每个子任务的完成时间不超过2s,LF-CRSE的性能优于当前的一些Javalin和JAVM 等项目[13-15]。
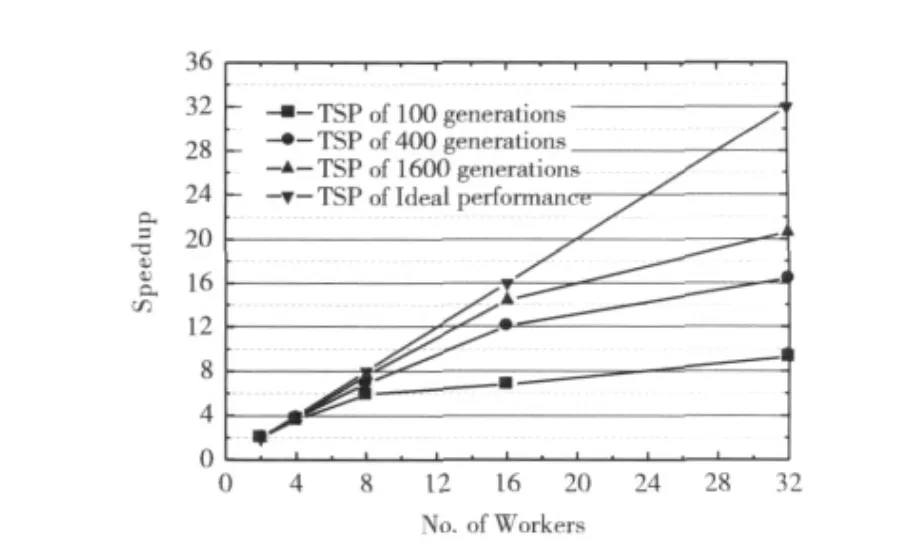
图3 分布式旅行商TSP的测试结果
在TSP问题中,Pmin是最低的边界处理器数目,它可以更加好的优化并行粒度性能。在这里设置的Pmin的值为1857,那么1857就是处理器的最低边界,这样就可以把完成时间降低到Tmin,大约为37s。LF-CRSE的容错测试结果如表2所示。它可以把一个异常的任务由失败到重新分配到新的工作机,但是它需要一些开销。从表中可以看出,这些时间开销不超过整体时间的10%。
最后测试了任务服务器和工作机之间的通信延迟开销。测试结果表明,如果把简单的操作直接在任务服务器上执行,而不是分配到工作机上,可以使整体的通信开销减少,这个是因为对于TSP算法来说,任务服务器上的任务划分比较简单,整体的完成时间减少。
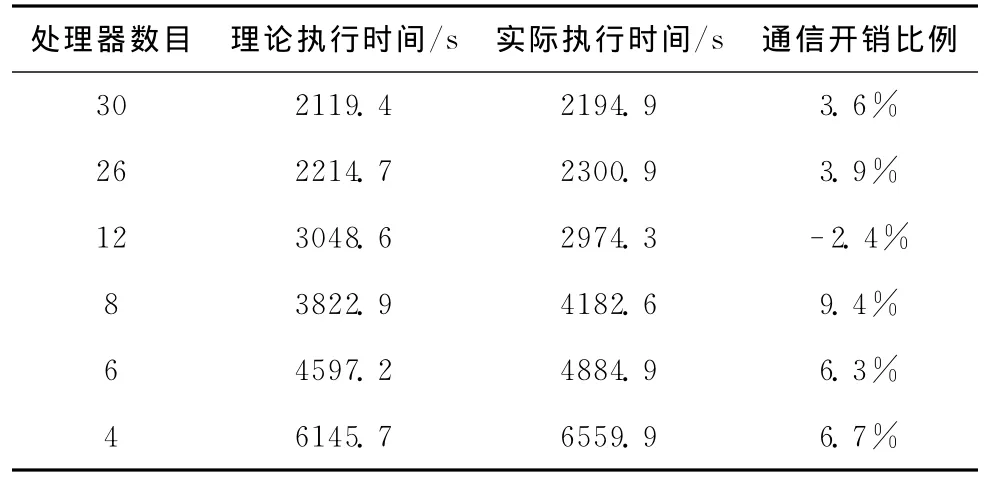
表2 LF-CRSE的容错测试结果
4 结束语
本文提出与描述了一个支持低延迟通信与容错的计算资源共享环境LF-CRSE,它通过中间件的方式可以完成广域网/局域网上的计算资源共享。在具体案例测试与容错测试等方面,LF-CRSE的功能测试与性能测试体现出良好的性能。本文的后续工作是调整后台节点的应用相关的调度策略,分析新的应用编程模式,改进节点上的负载,充分提高计算资源的利用率。
[1]Franck Cappello,Samir Djilali,Gilles Fedak,et al.Computing on largescale distributed systems:XtremWeb architecture programming models security tests and convergence with grid[J].Future Generation Computer System,2005,21 (3):417-437.
[2]Anderson D P.BOINC:A system for public-resource computing and storage [C].Proceedings of the Fifth International Workshop of Grid Computing.Washington,DC:IEEE Computer Society Press,2004:4-10.
[3]Andrade N,Cirne W,Brasileiro F,et al.Ourgrid:An approach to easily assemble grids with equitable resource sharing[G].LNCS 2862:9th Workshop on Job Scheduling Strategies for Parallel Processing.Seattle, Washington:Springer-Verlag,2003:61-86.
[4]Anglano C,Canonico M,Guazzone,et al.G peer-to-peer desktop grids in the real world:The share grid project[C].Lyon,France:Proceedings of 8th IEEE International Symposium on Cluster Computing and the Grid,2008:621-626.
[5]Akshay Luther,Rajkumar Buyya,Rajiv Ranjan,et al.Alchemi:A .NET-based enterprise grid computing system [C].Las Vegas,USA:Proceedings of the 6th International Conference on Internet Computing,2005:27-30.
[6]Great internet mersenne prime search project [EB/OL].http://www.mersenne.org/,2011.
[7]Shudo K,Tanaka Y,Sekiguchi S.P3:P2P-based middleware enabling transfer and aggregation of computational resources[C].Proc of the IEEE International Symposium on Cluster Computing and the Grid,2005:259-266.
[8]Michele Amoretti,Francesco Zanichelli,Gianni Conte.SP2A:A service-oriented framework for P2P-based grids [C].Proceedings of 3rd International Workshop on Middleware for Grid Computing.New York:ACM Press,2005:1-6.
[9]Patoli Z,Gkion M,Al-Barakati,et al.How to build an open source render farm based on desktop grid computing[C].Hussain DMA,Rajput AQK,Chowdhry BS.Proceedings of IMTIC,2008:268-278.
[10]Kondo D,Taufer M,Brook C,et al.Characterizing and evaluating desktop grids:An empirical study [C].18th International Parallel and Distributed Processing Symposium.Santa Fe,New Mexico,USA:IEEE Computer Society,2004:26-35.
[11]LUIS F G Sarmenta.Volunteer computing [D].Department of Electrical Engineering and Computer Science,MIT,2001.
[12]Neary M O,Cappello P.Advanced eager scheduling for Javabased adaptively parallel computing[J].Concurrency and Computation:Practice and Experience,2005,17 (7-8):797-819.
[13]Neary M O,Phipps A,Richman S,et al.Javelin 2.0:Javabased parallel computing on the internet[G].LNCS 1900:6th Int’l Euro-Par Conference.Springer Verlag, 2000:1231-1238.
[14]Cappello P,Mourloukos D.CX:A scalable robust network for parallel computing[J].Scientific Programming,2001,10(2):159-171.
[15]LAU L F,Ananda A L,TAN G,et al.JAVM:Internetbased parallel computing using Java[M].Annual Review of Scalable Computing,Singapore University Press/World Scientific,2000:59-74.
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09
铁道通信信号(2019年9期)2019-11-25 01:44:58
传媒评论(2018年4期)2018-06-27 08:20:24
传媒评论(2018年4期)2018-06-27 08:20:16
电子测试(2018年10期)2018-06-26 05:53:34
意林(2018年3期)2018-03-02 15:17:24
知识产权(2016年8期)2016-12-01 07:01:13
厦门理工学院学报(2016年1期)2016-12-01 04:50:48
网络空间安全(2016年3期)2016-06-15 20:27:10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
