
基于实例相似度的本体映射方法研究
2012-11-06 06:29沈亦军吕刚
重庆科技学院学报(自然科学版) 2012年3期
沈亦军 吕刚
(合肥学院,合肥230601)
基于实例相似度的本体映射方法研究
沈亦军 吕刚
(合肥学院,合肥230601)
提出利用贝叶斯理论计算实例相似度,定义集合相似度和概率相似度两个概念,推导出计算模型,得到一个完整的解决实例映射方案。用实例相似来优化映射,该方案的查全率和查准率比传统方法有所提高。
本体映射;实例相似度;贝叶斯概率
本体映射是信息集成、语义Web和知识管理等领域的一个关键问题[1]。在实现本体映射的各类方法中,基于相似度计算的本体映射是最常用的一种方法。在某些场合必须用实例映射才能得到正确的本体映射对,因为实例才真正反映了概念节点的语义含义,于是可以用实例相似来优化映射效果[2]。
检索是语义WEB的中心环节,而相似度计算是实现语义检索的核心技术,其计算方法的好坏直接决定了实例检索的质量和可靠性。因此,在构建和管理基于实例推理系统时,相似度计算起到了非常关键的作用[3]。许多实例相似度计算根据实例的属性特征,采用相似度函数来计算实例之间的相似度,有的是利用计算两个概念所对应实例集的公共部分所占总实例的比例来衡量[4]。文献[5]提出了丰富度和平衡度的概念,实现实例相似度的计算。本文基于贝叶斯方法,给出了一个比较有效的计算本体实例相似度的方法。
1 改进的实例相似度计算方法
实例实际上是一个概念的文本集合,两个实例集的公共元素在一定程度上反映了这两个集合的相似性。同时,很多时候一个元素是由多个词组合构成的,必须先对其进行预处理。贝叶斯决策就是在不完全情报下,对部分未知的状态用主观概率估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最优决策,从而提高查准率和查全率。
1.1 实例预处理
贝叶斯理论的基础公式是P(A|B)=P(B|A)P(A) /P(B),借用概率这个概念来表示相似度,即A与B的相似度就是A与B相似的概率。
定义1实例文本集:某概念所对应的若干实例组成的集合,记为Ic。
一个本体中的每个概念都有自己的实例文本集,而给本体构造实例文本集也是实例预处理的首要步骤。首先为本体树中每个概念节点在各实例中对应的元素值分别构造文本集,得到本体的实例文本集;然后,对集合中的多词进行分词,得到新的由多词集合构成的实例文本集。
计算实例相似度的基础原理,这里计算实例相似度主要基于两个假设:
(1)两个概念所包含的公共实例越多,实例集越相似。
(2)某个实例集中元素在另一实例集中出现的频率越高,实例集越相似。
对于假设(1),可以将两个实例文本集看成是两个简单的集合,然后计算它们之间交集和并集的比,作为相似度;对于假设(2),基于贝叶斯决策来计算某个实例文本集中元素在另一个实例文本集中出现的频率,来求基于贝叶斯理论的相似度,最后将这两个计算结果相结合。
1.2 集合相似度
定义2集合相似度:两个实例集的集合相似度,将这两个实例集看成集合后,计算出交集与并集的比值。这个比值越大,则表示两个实例文本集的公共部分所占比重越大,即两个实例文本集越相似,反之亦反。然而在分词过后的实例文本集中,一个多词分成了多个词元,于是就有两种方法可以计算集合相似度:
(1)将所有词元看成是一个集合。
(2)将每个多词表示成由词元组成的集合,而实例文本集便是由这些集合组成的集合。
对于第一种设计,会把每个多词拆开,于是词元充分独立,这样处理就忽略了多词本身的含义,结果比较片面,不够准确,所以本文中选用第二种方案。于是,两个实例文本集就转换成集合的集合,在寻找公共元素时,只要某对多词集合含有一个公共词元,则这对多词集合就是两个实例文本集中的一个公共元素。
假设这两个实例文本集分别是si和sj,其中:si= {g1,g2,g3,…,gm},sj={g1,g2,g3,…,gn}。而gi={w1,w2,w3,…,wp},这里gi为多词集合,而wi(1≤i≤p)为词元。对于本身就是一个词元的元素,则gi即是它自身构成的长度为1的集合。
接着我们定义si*sj和si∪sj:gk∈si*sj,当且仅当gk∈si∧{wp∈gk∧(gt∈sj→wp∈gt)}或gk∈sj∧{wp∈gk∧(gt∈si→wp∈gt)},即si*sj是由si和sj中含有公共词元的多词集合构成的集合。
最后,实例文本集的集合相似度pl(si,sj)=|si*sj|/| si∪sj|。
1.3 概率相似度
假设两个实例文本集si和sj,其中si={g1,g2,g3,…,gm},sj={g1,g2,g3,…,gn},gi={w1,w2,w3,…,wp},这里gi为多词集合,wi(1≤i≤p)为词元。si中的词元在si中出现的频率和sj中的词元在sj中出现的频率都在一定程度上反映了两个实例文本集的相似性,于是可以利用这两个频率来计算相似度。论文引出如下两个概念来表示上述的两种频率:
定义3权重:某一多词集合的权重是指在包含它的实例文本集中与该多词集合相交的多词集合所占的比重。
定义4外部权重:在实例文本集中与该集合内或该集合外的某一多词集合有交集的多词集合所占的比重,即表示这个多词集合在该实例文本集中的权重。
权重反映了多词集合在包含它的实例文本集中的重要性,外部权重是指任一多词集合在某一实例文本集中的重要性,往往这个多词集合来源于其他的实例文本集,在计算实例相似度时,这个多词集合就来源于映射的另一个实例文本集中。
对于两个实例文本集si和sj,其实si映射到sj的相似程度和sj映射到si的相似程度往往是不一样的,即这种相似度具有非对称性。论文提出了“单向概率相似度”的概念描述某一实例文本集映射到另一实例文本集的相似程度,它是有方向的。例如si到sj的单向概率相似度可以记为p(si|sj),它是由si中每个多词集合在sj中的外部权重和这个多词集合在sk中的权重决定的。由贝叶斯基本公式可得:
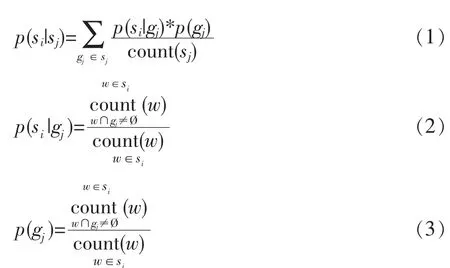
而si和sj的概率相似度是由si到sj的单向概率相似度和sj到si的单向概率相似度组成的,即
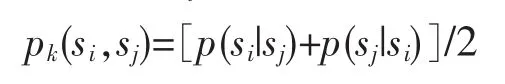
基于以上理论,可以用集合相似度和概率相似度来表示两个实例文本集的相似度:
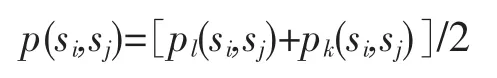
2 实验与分析
本文设计进行了实验,证明论文所提出的优化策略对一般的基础策略效果的改进。本文选用的实验数据来源于基于KAON2的开源资源Frame work for Ontology Alignment and Mapping(http://www. aifb.uni-karlsruhe.de/WBS/meh/foam/)中所提供的TestOntologies and Alignments。这里提供14个可用本体以及各本体映射的结果,本文的实验从中选用russia1.owl和russia2.owl作为数据源。整个实验过程用到的工具主要有Jena,VC++6.0和protégé3.1。
russia1和russia2中自带了部分实例,而剩余实例便在protégé中手动创建。在本实验中,每一个类均创建了30至40个实例,整个实例规模达到3 600左右。经过计算,可以得到每对节点的集合相似度、单向概率相似度以及概率相似度,最终得到实例相似度。如表1是部分结果,概率相似度是由两个单向概率相似度的平均值得到的,表中“概率相似度”一列中所填的数据同时列出了单向概率相似度。例如第一行0.69(0.71,0.67)表示s1到s2的单向概率相似度是0.71,s2到s1的单向概率相似度是0.67,而s1和s2的概率相似度为0.69。
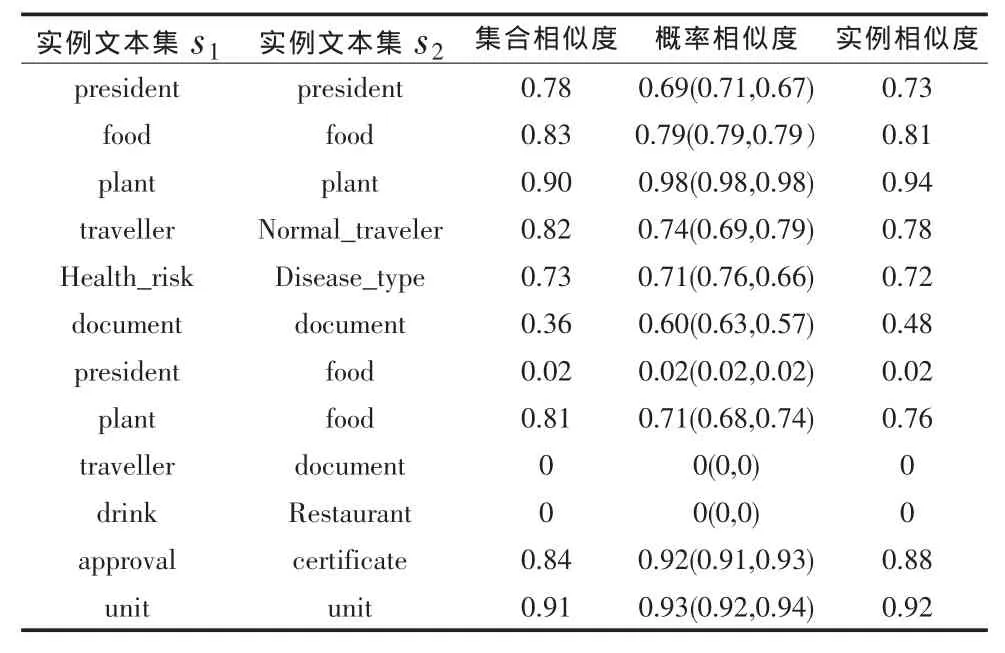
表1 实例相似度计算结果
由于本文的映射算法可以应用到多策略映射系统中,所以暂称为MP_Bayes。表2中,测试集1-3表示标准测试数据集中的本体编号。测试结果分别与文献[1]中提出的SNAX_Map方法以及Rimon系统测试结果进行比较。关于查全率和查准率,本文采用如下定义:
查全率:映射结果中正确的映射对数目与标准映射对数目的比值。
查准率:映射结果中正确的映射对数目与映射结果以及标准结果的并集中映射对数目的比值。
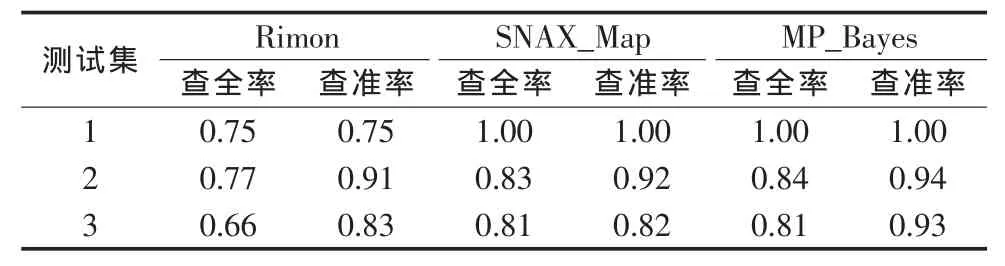
表2 MP_Bayes与其他系统综合数据比较
从实验结果来看,MP_Bayes系统和SNAX_Map系统唯一区别就是采用了不同的实例映射方法,MP_Bayes系统采用了本文提出的改进的实例映射方法。表2中数据显示实验MP_Bayes系统的查全率和查准率最高。也就是说,应用改进的实例映射算法的多策略结合方法在保证了查全率的同时,较为明显的提高了查准率,也就提高了最终映射结果的质量。同时,对各组不同的测试数据MP_Bayes的性能比较稳定。
3 结语
概念相似度计算是本体映射、服务发现、语义检索等技术的关键基础。本文在分析现有本体实例映射作用的基础上,提出了改进的本体实例映射方法,很好地利用了贝叶斯理论,弥补了实例映射策略所固有的缺陷,使得某些信息的缺乏或重复不会对整个映射系统产生大的影响。实验表明,采用新算法的系统性能比传统的多策略结合方法得到了改进。
[1]夏红科,郑雪峰,胡祥.一种新的本体映射发现方法SME [J].计算机科学,2010,37(6):233-236.
[2]Ehrig M,Sur Y.Ontology Mapping:An Integrated Approach[D].Germany:University of Karlsruhe,2004.
[3]李军均,戚进,胡洁,等.一种基于隶属函数的相似度计算方法及其应用[J].计算机应用研究,2010,27(3):891-894.
[4]唐杰,梁邦勇,李涓子,等.语义Web中的本体自动映射[J].计算机学报,2006,11(29):1956-1976.
[5]黎民.语义多策略结合匹配算法[J].计算机应用,2008,28 (7):1639-1641.
Research on Ontology M apping Based on Instance Sim ilarity
SHEN Yijun LÜGang
(HefeiUniversity,Hefei230601)
This paper proposes the sim ilarity calculation based on Bayesian theory,two concepts of the set sim ilarity and the probability sim ilarity,derives the calculationmodel and gets a complete solution to an instance ofmapping programs.Experiments show that the proposed program recall and precision is better than traditional methodshave improved.
ontologymapping;instance sim ilarity;Bayesian probability
TP311
A
1673-1980(2012)03-0170-03
2011-12-16
安徽省教育厅自然科学基金项目(KJ2011Z321);安徽省高校省级优秀青年人才基金项目(2011SQRL134);合肥学院点科研项目(01KY03ZD)
沈亦军(1966-),男,福建人,实验师,研究方向为计算机网络。
猜你喜欢
纺织科学研究(2021年6期)2021-12-02
数学小灵通(1-2年级)(2021年9期)2021-10-12
现代电子技术(2018年20期)2018-10-24
江西社会科学(2018年8期)2018-08-29
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
新闻前哨(2015年2期)2015-03-11
中国管理信息化(2009年10期)2009-06-19
