
基于空间向量遗传聚类的海洋环境监测数据分析*
2012-10-22 01:06:20周汝雁陈中华代岩岩赵世亭何世钧
传感器与微系统 2012年6期
周汝雁,陈中华,代岩岩,赵世亭,何世钧
(上海海洋大学信息学院,上海 201306)
0 引言
近几十年,人为排污活动加剧,进入河口地区的营养物质极大地促进了这些海域的初级生产,造成某些海区富营养化,导致海水的酸度增加,这些都将对海洋渔业生产和海洋生态环境产生巨大的影响[1]。虽然国家相关部门出台了污水排放的相关标准和法规,但有些单位仍向海水排放未经处理的污水,有些污水处理厂也向海水中排放水质超标的污水,因此,海水水质检测和水质变化情况监测对保护海洋环境有着深远的意义[2,3]。
针对海水水质监测的多参数数据分析的处理,监测中心接收到的数据都为海量数据,对于进一步的数据处理和控制措施的实施监测中心要花费较长的处理时间,因此,在进行异常情况确认和处理前首先要进行数据挖掘,从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、事先不知但又潜在有用的信息,聚类分析是数据挖掘的重要方法之一,而海洋环境参数的变化是渐进的,即便有国家海水水质标准,但水质状况的分析既要对多项指标进行综合评价,又具有模糊过渡的特点,因此,引入隶属度概念,采用模糊C均值(FCM)聚类方法进行分析更为合理,克服了硬性分类的不足[4],但基于目标函数的FCM是一种局部寻优算法,存在对初始化敏感和难以获得全局最优解的缺陷,其聚类数目也是依照经验进行选取的,缺乏充分的科学性,而且海量数据的聚类会浪费大量的时间和资源;遗传算法(GA)是一种借鉴生物界自然选择和进化机制发展起来的具有自适应性和自组织能力的随机搜索算法,具有全局搜索和并行计算能力,被广泛应用于求解复杂的优化问题[5,6],遗传算法通过模仿生物界“适者生存”原理,无需待解问题领域的特殊知识,无需对所有数据逐一进行处理,而是随机生成优化问题的一组可能解,经遗传变异操作后便可得到优化问题的全局近似最优解[7]。因此,本文采用空间向量遗传聚类分析方法,进行海量数据处理,既可大大减少数据处理量,又能得到科学合理的处理结果,也可提高监测中心对异常情况的响应速度。
1 遗传聚类算法
1.1 FCM 聚类算法
FCM算法具有良好的局部寻优性和误差收敛性,是一种贪心算法,并不一定能够得到全局最优解,经常会陷入到局部最优而非全局最优。算法步骤为
将有限向量 x={xk|xk∈RP,k=1,2,3,…,n}分为c类(1<c<n),分类矩阵U为
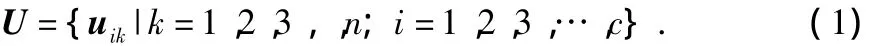
其中,uik表示向量xi属于类ck的隶属度,0≤uik≤1。
目标函数可定义为
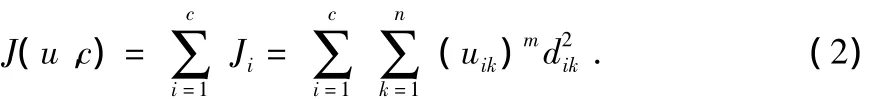
其中,dik为向量 xk到ci的空间距离,ci(1≤i≤c),ci∈RP。
算法执行前给出固定迭代次数,以免终止条件不能满足陷入无限循环。FCM算法应用于下述遗传聚类算法步骤(2)。
1.2 遗传聚类算法步骤
1)种群初始化:n个样本被分为c类,每个聚类中心作为一个基因,c个基因组成的基因链形成染色体,初始聚类中心随机选取,因此,初始染色体由随机选择的c个基因组成。设置种群大小n、最大进化代数g、交叉概率Pc、变异概率Pm的初始值。从数据集S={S1,S2,…,Sm}中随机选取n个向量形成初始种群,组成模糊分类矩阵U。
2)对种群进行以下操作:a.随机选取聚类中心;b.进行聚类划分;c.求解当前划分下的聚类中心,为提高搜索速度,初始聚类中心可根据实际数据分布情况进行给定,在每次得到聚类划分得到聚类中心后,用当前的聚类中心替换原来的聚类中心;d.计算适应度。
3)选择运算:按染色体适应度大小用轮盘赌方法选择下一代个体。
4)交叉运算:任选2个个体进行单点交叉操作。
5)变异运算:变异的概率由变异概率参数Pm决定,变异的位置随机产生,采用对变异位进行“非”操作。
6)得到最优染色体:若达到停止条件,迭代结束,解码出聚类中心;否则,转向步骤(2),重复执行迭代过程[8]。
2 监测点海水水质状况遗传聚类分析
以上海地区沿海水质状况监测情况为例,在距离海岸100 m处每间隔5 km设置1个采样点,30处监测采样点分布见图1所示,从北向南分别标记为采样点1~30。根据投放的浮标,结合实测数据以及遥感数据,提取温度,盐度,pH,DO 4个参数为特征参数进行分析,其中DO值为表观耗氧量AOU。

图1 检测区域采样点Fig 1 Sampling sites in the monitoring area
2.1 对某一时段内不同监测点数据的聚类分析
对某一时段内30个监测点,各监测点间隔30 min连续测量5 h得到的300组数据进行分析。聚类初始条件设置为:种群大小n=100、最大进化代数g=50、交叉概率Pc=0.9、变异概率Pm=0.01。
聚类结果显示,采样点数据可分为4类,见图2与表1。
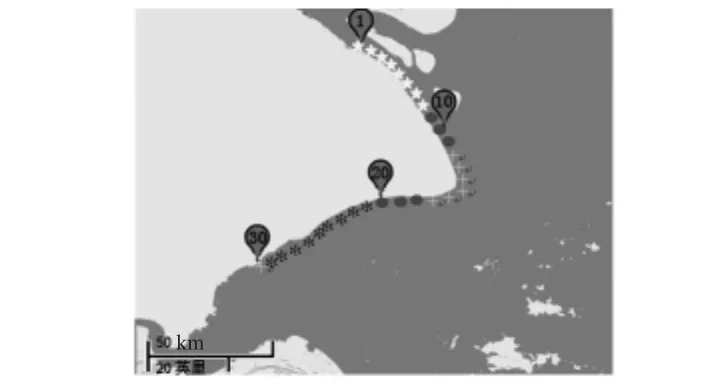
图2 采样点聚类结果Fig 2 Clustering result of sampling sites

表1 各采样点所属类别Tab 1 Categories of each sampling sites
聚类结果在环境监测参数特征空间的投影如图3所示。
其中I类,由图3(a)和(b)显示,此类监测点pH在7~9之间,大部分集中在8左右。DO值在4~8mg/L之间,大部分集中在6~8 mg/L之间。盐度在(25~35)×10-3之间,大部分集中在(30~35)×10-3之间,温度基本在 21.5~22.5℃之间,此类点海水检测数据显示,除DO值稍低之外,海水其他参数较为正常。II类,由图3(a)和(d)显示,此类监测点pH与I类基本相同,在7~9之间。但盐度在(13~25)×10-3之间,明显低于 I类,DO 值在2.5~4.5 mg/L之间,温度基本在22~23℃之间。此类点应为有污水排放或有河水与海水交汇,水质状况比较正常。Ⅲ类,由图3(c)和(d)显示,此类监测点DO值和温度值与II类基本相同,DO 值基本在2.5~4.5 mg/L 之间,温度基本在22~23℃之间,少数监测点温度高于23℃。但pH偏低,在6~7之间。盐度在(5~20)×10-3之间,也低于II类。此类点附近应有陆源排污口,水质状况较差,需要进行进一步监测或进行处理。Ⅳ类,由图3(a)和(c)显示,此类监测点DO值最低,基本在1~3 mg/L之间。pH范围较大,在8.5~12之间。盐度值最低,在(0~15)×10-3之间。温度最高,在23.5~25℃之间。此类监测点水质状况较差,附近应有陆源排污口,温度最高主要是由于排出的污水所致,而且排出的污水处理情况很差,需要进行进一步监测或进行处理。
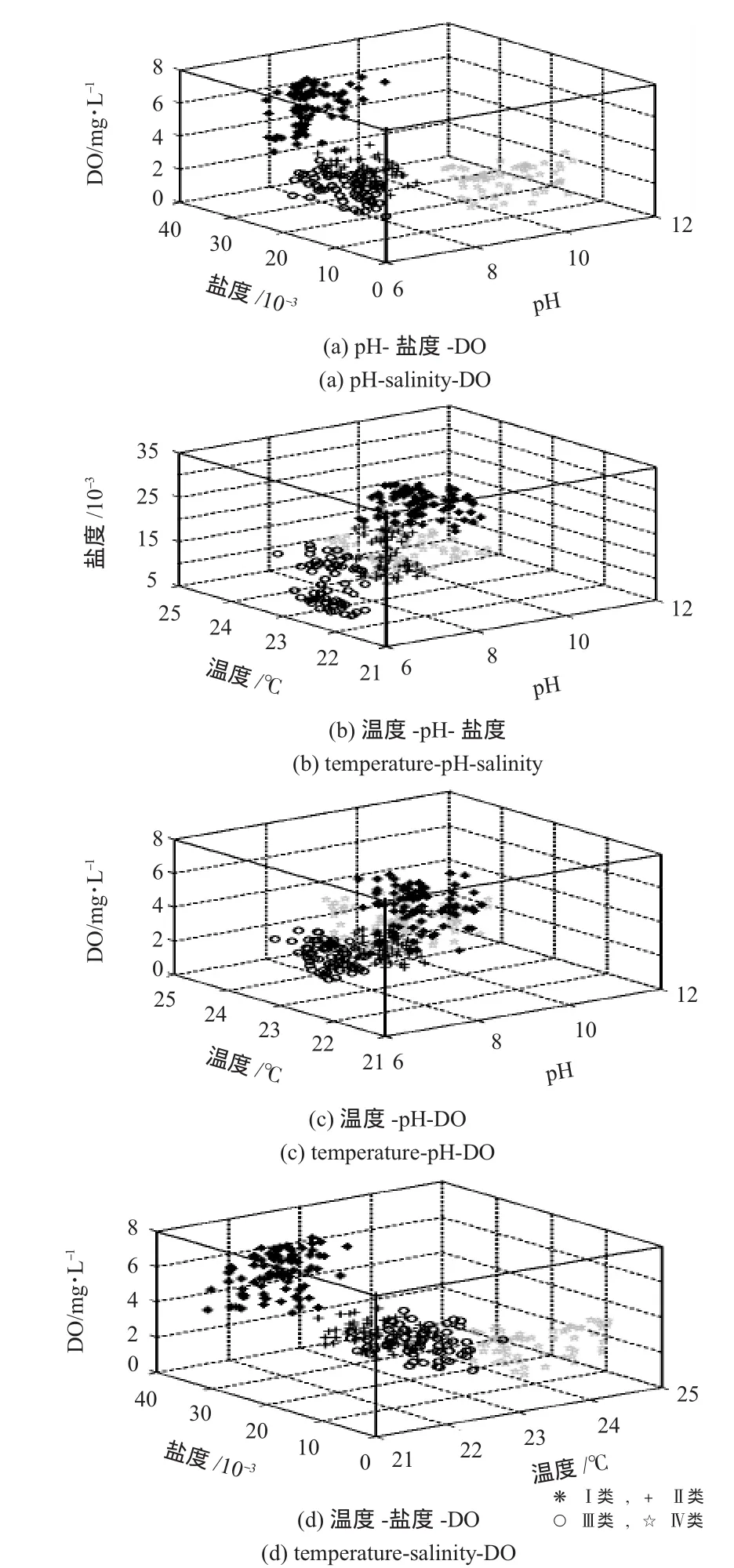
图3 聚类结果在环境监测参数特征空间的投影Fig 3 Projection of clustering result into the feature space of environment monitoring parameters
从聚类结果在环境监测参数特征空间的投影可以看出:I类数据源采样点所处位置为水质最好的区域,II类次之,Ⅲ类和Ⅳ类数据源采样点所处位置的水质较差,通过采样点数据在多参数特征空间的分布情况,可实现对海水水质状况的分类识别、分析,并进行进一步的监测处理。
2.2 对不同时段监测点数据的分析
对30个监测点相隔2 d后另一时段监测到的300组多参数数据进行分析。仍按2.1的聚类结果的分类情况将300组数据在环境监测参数特征空间进行投影,如图4所示。
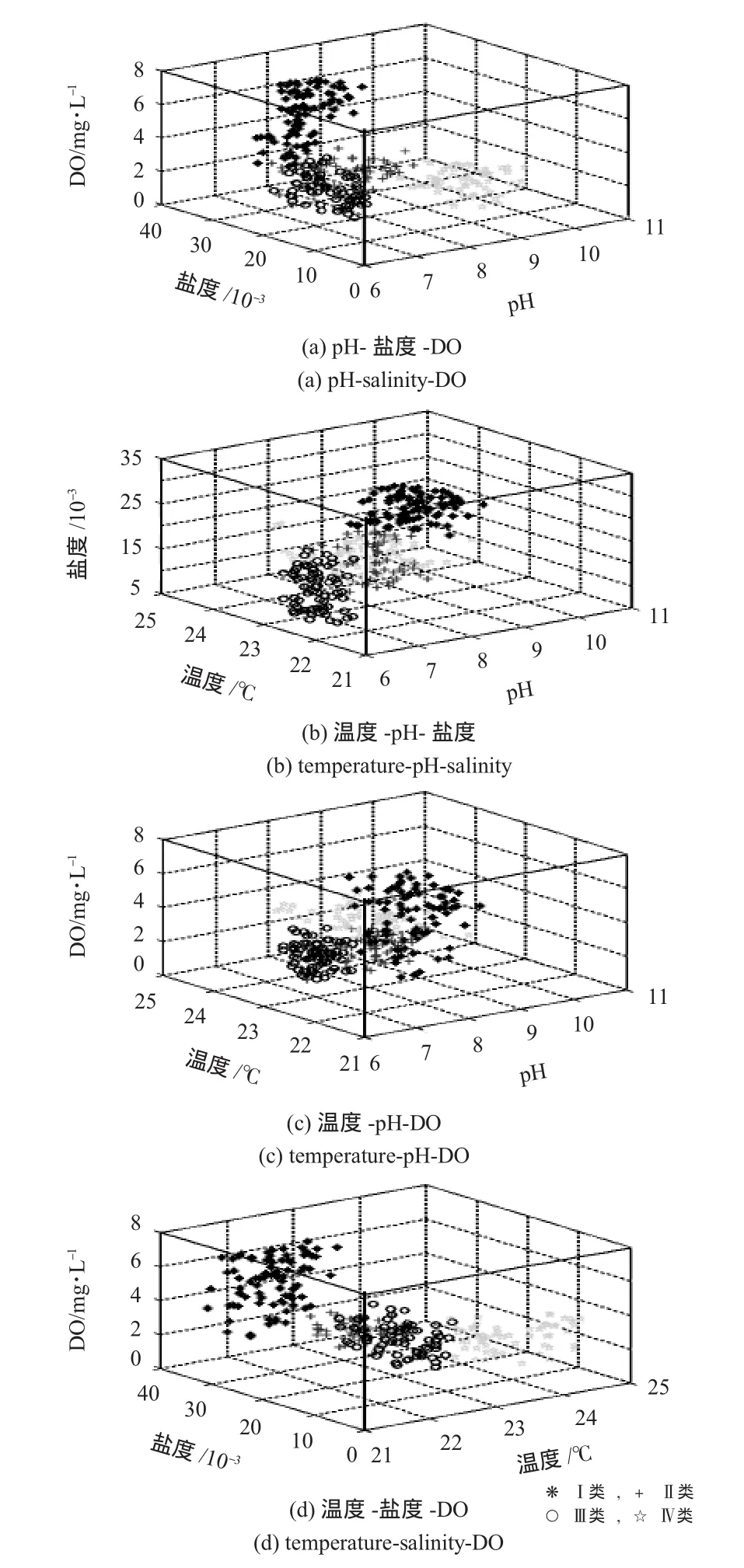
图4 聚类结果在环境监测参数特征空间的投影Fig 4 Projection of clustering results into the feature space of environment monitoring parameters
将图4与图3进行比较可以看出:I类数据源采样点中部分数据向II类数据方向移动,说明此类中某些采样点处的水质情况在变差,II类数据源采样点中部分数据向Ⅲ类数据方向移动,说明此类中某些采样点处的水质情况在变差,Ⅲ类数据源采样点数据位置无大的变化,与图3所处位置基本相同,说明此类中采样点处的水质情况无明显变化,Ⅳ类数据源采样点向pH值低的II类数据方向移动,DO值也有所升高,说明此类中某些采样点处的水质情况在变好,但此类采样点所处区域水质状况仍不容乐观。
若进行分析时各类采样点数据混杂分布,无法区分时,可重新按2.1给出的方法聚类后再进行分析。
3 结论
本文以海水水质常见参数为例,给出了一种遗传算法和模糊聚类分析相结合进行海水质状况数据处理的方法,该方法可以在某一时间段对不同监测点数据进行分析,得到监测区域内的水质状况分类情况,发现并确定水质状况异常海域。采用此方法还可以对不同时段监测点数据进行分析,得到该监测区域海水水质变化趋势。另外,采用此方法也可以将其他多项海水水质参数数据,如N含量、P含量,COD值,硫化物、浊度等参数在特征空间进行聚类分析,是海洋环境多参数数据分析及信息挖掘的一种有效方法。
[1] 张 勇,崔永平,秦榜辉,等.上海市排污口有机污染物调查研究[J].海洋开发与管理,2008(7):81-83.
[2] 王 琪.海洋环境问题及其政府管理[J].中国海洋大学学报:社会科学版,2002(4):91 -96.
[3] 马春生,潘 红,周洪英,等.发展海洋环境监测的意义和作用[J].科技创新导报,2010(2):123-124.
[4] 郭良波.模糊数学在海洋环境评价中的应用[J].南阳理工学院学报,2010,3(2):83 -86.
[5] Goldberg D E.Genetic algorithms in search,optimization and machine learning[M].New York:Addison-Wesley,1989:106 -110.
[6] Holland J H.Adaptation in natural and artificial systems[M].Ann Arbor:University of Michigan Press,1975:126 -130.
[7] Bandyopadhyay S,Maulik U.Genetic clustering for automatic evolution of clusters and application to image classification[J].Pattern Recognition,2002,35(6):1197 -1208.
[8] Zhou Ruyan,Chen Ming,Feng Guofu,et al.Genetic clustering route algorithm in WSNs[C]∥The 6th International Conference on Natural Computation,2010:4023 -4026.
猜你喜欢
煤气与热力(2022年4期)2022-05-23 12:44:56
水利水电科技进展(2021年6期)2022-01-07 02:58:02
水电站设计(2020年4期)2020-07-16 08:23:48
趣味(数学)(2019年12期)2019-04-13 00:28:58
儿童故事画报·发现号趣味百科(2017年10期)2018-03-13 19:01:16
计算机与生活(2018年3期)2018-03-12 08:38:11
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
作文周刊·小学一年级版(2016年39期)2017-03-03 12:42:14
湖南畜牧兽医(2016年3期)2016-06-05 08:37:55
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
