
基于线索树双层聚类的微博话题检测
2012-10-15 01:51:52陆剑江姚建民朱巧明
中文信息学报 2012年6期
马 彬,洪 宇,陆剑江,姚建民,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州215006)
1 引言
微博是一个基于用户关系的信息分享、传播以及获取的平台,用户可以通过 WEB、WAP以及各种客户端设备构建个人社区,以最高140字的信息量发布消息,实现即时分享。相对于网页,微博具有更强的互动性和及时性;相比于传统博客,微博文本更加短小,更新更加及时、方便,另外,用户层次多样化,使得信息更加丰富、多元化。
据第三方数据统计,新浪微博注册用户数已达1.4亿,腾讯微博的注册用户也已经超过8千万,Twitter注册用户已达2亿,如此庞大的用户群每天发布数以千万计的微博文本[1]。如何在信息多样化且高速更新的动态环境下准确检测特定时间内用户关注或满足其兴趣偏好的话题信息,对面向互联网的信息处理研究及应用都具有重要的意义。
话题检测起源于1996年的话题检测与跟踪(Topic Detection and Tracking,TDT)评测会议的子任务。以新闻专线、广播、电视等媒体信息流为处理对象,将信息流中的报道归入不同的话题。话题检测关注的是新信息的发现能力,尤其侧重识别特定语义内聚且所属事件相互关联的信息集合—话题。因此,话题检测本身是一种面向实时媒体的信息组织方式,而面向微博的话题检测则在最活跃的新型语言学资源上对这一课题提出了全新的挑战。
本文在前期针对新闻媒体的话题检测工作基础上,结合微博的特点提出一种基于线索树的双层聚类话题检测方法。后续章节组织结构如下,第2节介绍相关工作;第3节给出微博文本的基本属性及特点;第4节介绍基于线索树双层聚类的话题检测方法;第5节给出实验设计方案;第6节分析实验结果;第7节总结全文并阐述未来工作。
2 相关工作
传统的话题检测主要针对普通文本,目前话题检测常用的聚类方法有:中心向量法[2-3],层次聚类法[3],K-means[4],Single-Pass[5-6]聚类方法等。 以上研究方法在普通文本的话题检测任务中起到了很好的效果,如在TDT语料中进行的话题检测任务,但是,将上述方法直接应用到微博文本上很容易造成数据稀疏问题。
2010年出现了一些微博文本话题分析的研究。Bharath Sriram等[7]在将Twitter文本分类到预定义的话题类别下时,为解决文本较短造成的数据稀疏问题,通过抽取作者profile文件和文本记录中的领域相关的特征集合,对Twitter文本的特征进行扩充。Ramage等[8]采取Labeled LDA模型,将Twitter微博文本映射到substance、style、status和social characteristics四个潜在维,并基于上述分析结果实现微博排序和微博推荐功能。O'Connor等[9]采用文档聚类和文本摘要技术,采用四个步骤对与检索词相关的话题进行归类。针对每一个检索词,返回和该检索词相关的话题集合。但是,以上工作均假定微博文本之间彼此独立,并没有有效利用微博的“对话性”特点,因此都存在严重的数据稀疏问题。Liu等[10]试图借助HowNet实现特征扩展,但也带来了一些噪音信息,导致处理效果提高不明显。
3 微博文本基本属性及特征
3.1 基本属性
微博文本是限定在140字之内,用户自由编辑的短文本。其中,首帖和跟帖都称为微博文本。在转发和评论的微博文本中会显示被转发和被评论的对象。图1给出的是相关于话题“利比亚局势”的微博文本实例。其中:
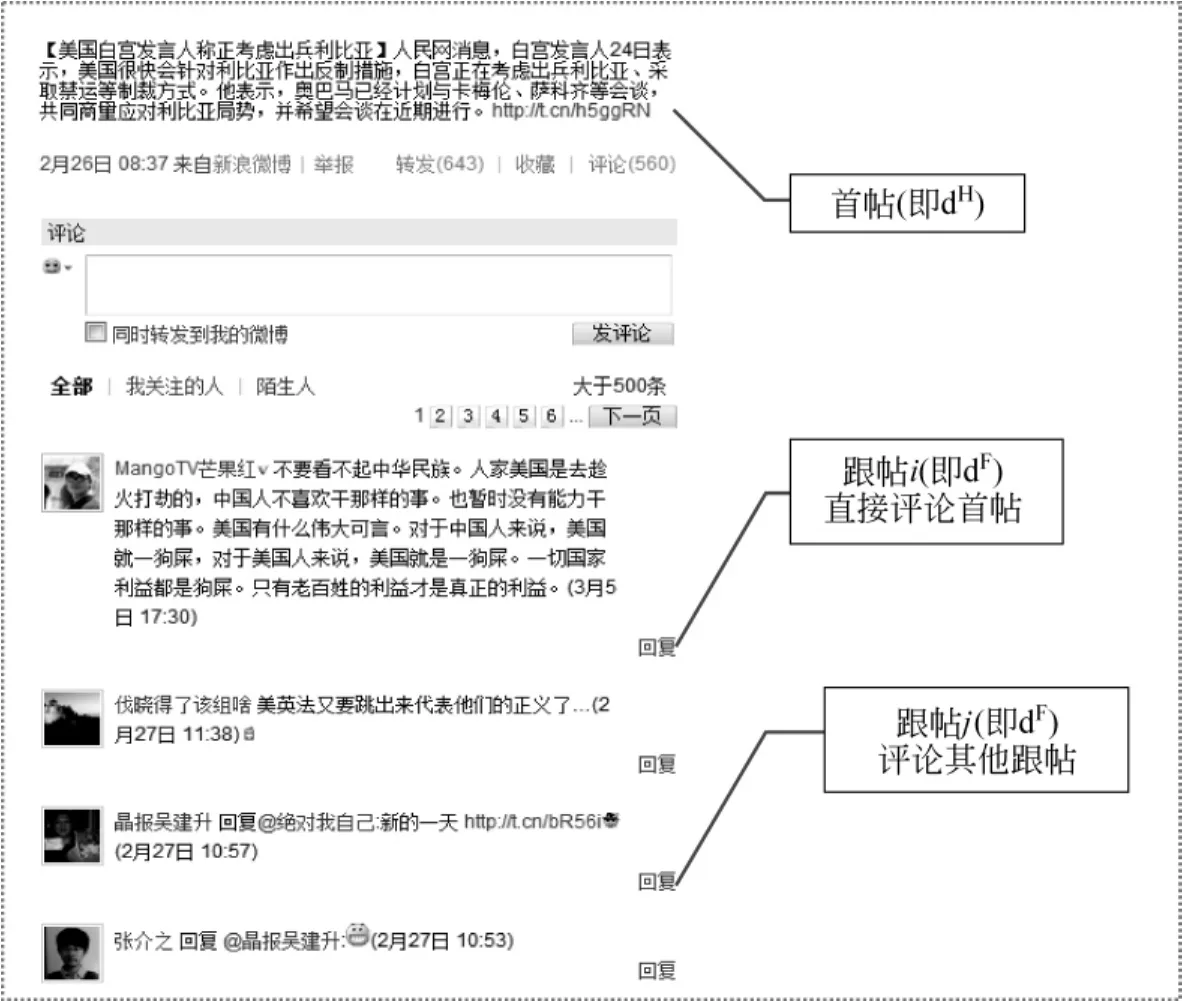
图1 微博文本示例
首帖:称通过自发发言而产生的微博文本为首帖,记为dH。如图1中首段文字“【美国白宫发言人……并希望会谈在近期进行。”
跟帖:对首帖进行转发或者评论的微博文本,记为dF。如图1中“MongoTV芒果红”等评论人给出的评论性回复。
微博线索树(Thread):本文将某首帖为根、其跟帖为子节点的具有语义及时序关联的微博文本集称为微博线索树,记为T= (V,E),如图1所示。
微博森林:本文将微博空间中所有微博线索树的全集称为微博森林,记为F=(VU,EU)。如图2所示,(a)、(b)和(c)分别代表不同线索树,三者之和为森林。

图2 微博文本森林结构示意图
由此,本文的研究核心问题可表示为:从全集微博森林F中自动划分其中包含的所有话题Z={zi},i=1…K(此处,Z 表示话题集合、zi表示某一特定微博话题、K表示森林F中的话题总数)。
3.2 微博文本特点
微博展现了一种独特的自然语言文本形式:微型文本。除了规模大及传播速度惊人等实际应用特点外,微博文本还包括以下语言特性。
1)文字容量小。微博系统限定一个微博文本介于0到140个汉字之间;
2)语言形式自由。文法往往非正式,语言口语化程度高。为了提高交流速度,微博文本中缩写和拼写错误极为常见,并掺杂一些新近流行的网络语言;
3)半结构化。除了文本内容,微博文本还包含一些元信息,例如作者和时间信息;
4)线索嵌套。微博文本通常是某对话线索中的一个发言或回复。微博系统自动保存了大量的微博文本线索,每个线索又包含了多个微博文本;
5)跨文本上下文信息丰富。每个微博文本都在评论别人,同时也是别人评论的对象。这些评论关系体现在不断回复过程中的线索上下文。
上述微博文本的语言特性给微博话题检测中的文本处理带来了以下问题。
1)微博文本短,尤其是“跟帖”往往仅有几个词(<=10)。然而大多数话题聚类算法的性能优劣极大程度上取决于话题描述(即特征空间)的合理性和充分性。显然,短小的微博文本造成的数据稀疏性难以满足话题描述的这一要求;
2)微博文本文法不正式,且新词不断出现,导致标准的语言分析工具的适应性较差。例如,标准分词工具无法有效识别网络词汇(例如“童鞋”暗指“同学”);
3)“跟帖”数量在微博文本中占多数,为提高发帖效率,跟帖经常通过指代或者省略手段标引上下文,这导致微博文本中存在大量话题特征的缺失现象,无法有效支持话题内容及语义的有效分析。
本文针对上述问题充分结合微博文本的“对话性”特点,提出基于线索树双层聚类的话题检测方法:先在微博文本线索范围内构造线索话题模型,准确滤掉“跑题”(即语义偏差)或“灌水”(即内容无关)的微博文本,从而将微博文本线索树安全转化为一个较长的、特征丰富的文本;在此基础上,针对微博文本的整体内容构造全局话题模型,辅助话题的精准聚类。
4 基于线索树双层话题检测
本文面向微博文本话题检测提出一种时序特征和作者信息相融合的话题模型(Temporal-Author-Topic,TAT)。下面首先概述基于这一模型的微博话题检测方法框架,然后,具体分析和阐述TAT模型。
4.1 方法概述
基于线索树双层聚类的话题检测方法总体架构如图3所示(见下页)。预处理阶段主要进行微博文本的分词和去停用词等操作;“线索局部话题”阶段主要进行线索内局部话题模型的构造,并滤除线索中的噪音文本;“全局话题”阶段将线索树内的相关文本结合起来,形成能够代表整个线索树的线索文本,从而有效地扩展微博文本的特征空间,解决数据稀疏问题。最终,利用全局话题模型进行微博话题检测,形成话题库。
理论上,上述两步话题建模(先局部后全局)本身是同质的过程,区别在于运行在不同的文档空间。局部话题建模过程在线索内运行,而全局话题建模则在全集线索森林上运行。对局部和全局话题进行分析时,除文本内容外,该方法还考虑作者、时间等特征。因而,形成融合了时序、作者信息和话题内容特征的TAT话题模型。这一模型具有显著的微博文本结构化特征,下面分别进行详细陈述。
4.2 TAT模型
微博作为网络短文本的一种,具有较强的意图性、对话性和个人信息特性。因此,微博文本的话题模型也应充分反映上述特点。根据这一需要,TAT建模引入以下的特征。
1)作者特征。在微博文本中,作者是一个重要的特征。通过观察数据发现同一个作者通常只关注有限个相对固定的话题。在本文中,将作者信息添加到普通的话题模型中形成融合了作者背景的话题模型(Author-based Topic model,AT)。
2)时间信息。根据数据观察发现,某一个时段内,微博的交互评论往往针对有限个相对固定的话题。为此,TAT融入时序特征,首先设置时间窗口为i小时(实验中的经验性地设置为1,即i=1),如果两篇微博的发布时间同属一个时间窗口内,即认为两篇文本相关于同一个话题的概率较高。由此,在AT模型的基础上继续引入时间信息形成TAT模型。
3)线索树。在微博话题检测中,线索是非常重要的话题聚类特征。在同一线索树(即针对同一首帖发生的系列交互,如图1中首帖和跟帖)内的微博文本往往集中讨论同一话题,其不同文字片段的语义一致性和内容相关性较强,有助于话题检测。
TAT在传统概率话题模型基础上,以线索树为核心,在线索树内外的局部话题模型和全局话题模型构造过程中融入上述时间信息和作者信息的特征分布,其数学表达式如下:
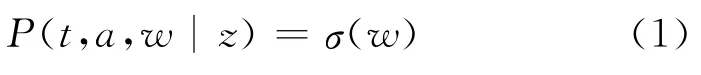
其中,t代表时序信息,a代表作者信息,w代表词特征,z代表话题信息。进行话题检测中,在构造特征空间时,将时序信息和作者信息作为两个维度添加到特征空间中。
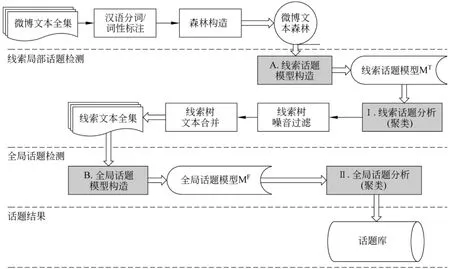
图3 系统流程图
4.3 线索局部话题检测
线索内话题检测(即主框架中的局部检测)作为本文微博话题检测的第一步,通过聚类检测出特定线索树内所讨论的话题信息,并将与话题不相关的微博文本和垃圾文本过滤掉,例如,“哈哈”、笑脸符号等垃圾或者灌水的文本。
图4给出了图1所示微博实例的树形结构。该线索树含有3个子话题。但该结构图显示右侧子树和首帖的话题明显不相关。因此,在这一线索树中,上述子树的微博文本被认定为垃圾帖。上述局部聚类的任务即为对这类垃圾帖或不相关帖进行过滤。
在此基础上,局部检测进一步融入交互关系(同一首帖下用户相互回复的文本信息):如果A帖和B帖之间具有回复关系,即A-回复-B,则假定两个帖子之间讨论的是同一个话题。这种回复关系在局部话题检测中起到很重要的作用。针对具有A-回复-B关系的微博文本,局部聚类过程在度量两个文本相关度时(即衡量两者讨论同一话题的概率时)进行加权操作,如式(2)所示:

图4 微博线索的树型结构

其中,Sim(P1,P2)采用向量空间模型 VSM 描述文本,向量余弦值为其相关性;|N|代表线索中的微博文本总数。
在微博文本内容基础上融入交互信息形成线索树内的话题检测模型,进而对微博线索树进行话题分析。线索树内话题分析通过聚类实现,过滤掉话题不相关的垃圾文本(实验中设定聚类个数K,保留类别内部文本数较多的类别,即类别内部文本数较少的文本信息认为是话题不相关的内容)。最后,我们得到一个干净的、话题相关的线索文本树TR。
4.4 全局话题检测
全局话题聚类是在局部话题检测的基础上,在微博森林上进行话题检测的过程。为了解决数据稀疏问题,本文充分利用线索树结构。将第一步处理后的线索树TR中的微博文本进行合并,扩充为信息丰富的线索文本(thread text)。然后,对线索文本集进行全局话题检测。如果线索文本属于某个话题,那么定义该线索文本下的所有微博文本都属于该话题。
假如线索树TR中的微博文本结合后形成线索文本Xi,即TR所有微博文本的组合。微博森林则最终会形成线索文本集合{Xi},i=1,2,…,n。从而,话题检测的任务就转化为在集合{Xi},i=1,2,…,n中发现话题信息的过程。
4.5 特征选择
本文在采用词频和反文档频率(TFIDF)作为特征选择和特征权重计算的基础上,同时测试了潜在狄利克雷分配模型(Latent Dirichlet Allocation,LDA)的特征选择性能。事实上,LDA模型已被验证有益于长文的特征选择(优于TFIDF)[11],但在微博这类短文本上的性能尚未得到验证。为了尝试更好的特征选择方法,本文实验部分对TFIDF和LDA分别进行了测试,并验证LDA特征选择方法对微博文本的话题检测更为有益。4.5.1 基于LDA模型的特征选择
LDA是一种非监督机器学习算法,采用词包(bag of words)方法,将每篇文档视为一个词频向量,用来识别大规模文档集或语料库中潜在的主题信息。
语料库中每一篇文档与T个主题的一个多项分布相对应,该多项分布记为θ。每个主题又与词汇表中的V个单词的一个多项式分布相对应,将这个多项式分布记为φ。上述词汇表是由语料库中所有互异单词组成,实际建模中要进行去除停用词、词干还原等处理操作。θ和φ分别带有一个超参数α和β的Dirichlet先验分布。对每一篇文档d中的每一个单词,我们从该文档所对应的多项分布θ中抽取一个主题Z,然后我们再从主题Z所对应的多项分布φ中抽取一个单词W。将这个过程重复Nd次,就产生了文档d。
5 实验
5.1 语料
对中文微博的研究尚处于起步阶段,尚无公认的语料集和标注结果。因此,本文使用新浪开发平台①open.weibo.com提供的API获取数据,根据TDT4标注大纲,借助六位志愿者进行人工标注。
本文选择1 100个线索树作为语料集,其中共包括16 500个微博文本(平均每个线索树中含有15个微博文本)。针对该语料集的人工标注结果总共提交了100个不同话题。
5.2 评测方法
实验继承了Steinbach等[12]提出的评测方法。其中,使用Ai代表由系统聚类获得的话题类ci的文档集合,Aj代表人工标注的话题类cj的文档集合。ci的F值计算方法如下:

其中pi,j,ri,j和fi,j分别代表类ci和类cj进行比较后的p值(精确率)、r值(召回率)和f值。对求出的p,r和f值通过求平均之后得出系统的P,R和F值。
5.3 系统设置
为了验证时间信息、作者信息和线索信息在话题检测中的作用,本文设置三项Baseline系统,所有系统中的聚类算法统一采用K-means和层次聚类(HAC),描述形式如下:
B-sys1:只含有微博的文本内容(词特征+VSM)。
B-sys2:在B-sys1基础上添加作者信息特征。
B-sys3:在B-sys2基础上添加时间信息特征。
实验中,本文所尝试的基于线索树的双层聚类算法(Our-sys),在B-sys3 的基础上充分使用了线索信息,先进行线索内聚类(同一首帖下交互信息的聚类),再进行全局聚类。此外,B-sys1,B-sys2,B-sys3和Our-sys系统都分别采用TFITF和LDA方法进行特征选择;在聚类过程中,分别采用了K-means聚类算法和HAC层次聚类算法。
6 实验结果及分析
实验首先验证不同的聚类个数对系统性能的影响。实验给出从50到150不同的聚类个数。从图5中可以发现,随着话题个数的增加,系统的性能持续优化;但当K大于100时性能出现下滑。不同特征选择方法和不同的聚类算法结果都呈现相同趋势。并且在聚类个数趋于真实类别个数时(100)本文所涉方法能够取得最优的效果。

图5 K取不同的值时的F值
表1显示了Baseline系统和双层聚类系统(Our-sys)的在K取100时的实验结果。实验结果显示,系统B-sys2比B-sys1平均提高了4.0%,系统B-sys3比系统B-sys2平均提高了0.1%,而双层聚类系统Our-sys比B-sys3平均提高了2.7%。说明作者信息、时间信息和线索信息在微博话题检测中起到了正面的作用。其中,B-sys2的结果比B-sys1的平均提高了4个百分点,说明作者信息在微博短文本的话题检测任务中起到了非常重要的作用,验证了本文前面的假设:同一用户在一段时间内关注的话题相对固定。
B-sys3和B-sys2的对比结果可以看出,时序信息在微博文本的话题检测中并没有达到预期的明显效果,主要原因是特定时间段内的微博文本具有一定的话题相关性,但是话题分布较为广泛。通过K-means+LDA这组最好的性能中可以看出,时序信息仍然对话题检测起到了积极的促进作用。
通过Our-sys和B-sys3的对比结果中可以看出,线索树信息在微博文本话题检测中起到了显著的作用。Our-sys很好地利用了线索树信息,即首先在线索树内进行局部话题聚类,然后在线索树集合中进行全局话题聚类,有效地利用了针对同一首帖进行跟帖的微博文本集合中微博文本高度语义一致性和内容相关性的结构特点。

表1 不同的方法在K=100时的F值
Our-sys能够对Baseline系统的改进源于如下两方面:其一,Baseline系统将微博文本看作独立信息单元,没有充分利用上下文信息。比如“支持,打!”,对于这样一个和上下文有显著回复关系的微博文本,Baseline很难准确判断该文本属于哪个话题,而本文的方法将此微博和处在同一线索树中的首帖“美国出兵利比亚”联系起来,有效地利用上下文信息解决类似的信息缺省的微博文本的话题聚类问题;其二,Baseline将每个微博看作独立的文本。由于微博文本短小,所以每篇文本中的词语信息很少,很容易造成数据稀疏问题。在构造特征向量时,数据稀疏问题很严重。而Our-sys将线索树(同一首帖下围绕核心话题的交互信息)看作统一整体,在线索文本上进行话题检测,有效地解决了数据稀疏的问题。
其次,通过对特征选择方法的对比看出,LDA对微博文本的特征选择有助于话题检测系统性能的提高,并优于TFIDF,继承了其在长文本中的优势,如表1所示。此外,通过对聚类算法的比较可以发现,Our-sys系统使用K-means聚类算法取得的性能比HAC聚类算法的性能好,说明,虽然HAC聚类算法和本文的方法性质很像,但是,HAC聚类算法并没有有效利用微博的上下文信息,因此,在最终的聚类效果上并没有Our-sys系统的效果好。
7 结论和未来工作
本文根据微博文本的特点提出了基于线索树双层聚类的话题检测算法。利用融合了时序特征、作者信息以及话题内容的TAT模型,先后在线索树内和线索树外进行局部话题检测和全局话题检测,最终形成话题库。实验结果表明,本文的方法很好地解决了数据稀疏的问题。
微博文本中网络词语出现频繁,因此,在使用中国科学院分词工具进行分词时效果不理想,进而影响特征选择的性能;同时,微博文本中的语言表达较为随意、含蓄,例如,“狐狸尾巴露出来了”这样一条根据首帖展开的回复,是针对话题“美国出兵利比亚”展开的讨论,但是由于语言表达含蓄,本文的方法很难将这类文本归类到话题“美国出兵利比亚”中。针对上述问题,在以后的工作中,将针对微博文本特点改进分词工具;完善微博语料库,在更大规模的语料中进行测试。另外,由于微博文本具有很强的意图性,可以将话题检测结果作为意见挖掘对象的候选集合进行微博文本意见挖掘,以解决文本短引起的召回率低的问题。
[1]China and Microbloging:How people tweet in China[DB/OL].www.digimind.com,2011.
[2]J Allan,J Carbonell.Topic Detection and Tracking Pilot Study:Final Report[C]//Proceeding of the DARPA Broadcast News Transcriptions and Understanding Workshop,February,1998:11-17.
[3]Y Yang,T Pierce,J Carbonell.A Study on Retrospective and On-Line Event Detection[C]//Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,1998:28-36.
[4]J Xu,W Croft.Cluster-based language models for distributed retrieval[C]//Proceedings of the SIGIR 1999:254-261.
[5]Z Jia,Q He,H Zhang,et al.A New Event Detection and Tracking Algorithm Based on Dynamic Evolution Model[J].Journal of Computer Research and Development,2004,41(7):1273-1280.
[6]贾自艳,何清,张俊海,等.一种基于动态进化模型的事件探测和追踪算法[J].计算机研究与发展.2004,41(7):1273-1280.
[7]B Sharifi,M-A Hutton,J Kalita.Summarizing Microblogs with Topic Models [C]//Proceeding of NAACL-HLT'2010:685-688.
[8]D Ramage,S Dumais,D Liebling.Characterizing Microblogs with Topic Models [C]//Proceeding of ICWSM'2010.
[9]B O'Connor,M Krieger,D Ahn.TweetMotif:Exploratory Search and Topic Summarizing for Twitter[C]//Proceedings of ICWSW 2010.
[10]Z Liu,W Yu,W Chen,et al.Short Text Feature Selection and Classification for Micro Blog Mining[C]//Proceedings of CiSE'2010:1-4.
[11]M Blei,Y Ng,I Jordan.Latent Dirchlet Allocation[J].Journal of Machine Learning Research,2003:993-1022.
[12]M Steinbach,G Kapypis,V Kumar.A Comparison of Document Clustering Techniques[C]//Proceedings of KDD Workshop on Text Mining,2000:109-111.
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19 18:09:52
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
电子测试(2017年15期)2017-12-18 07:19:27
电子制作(2017年23期)2017-02-02 07:17:06
校园英语·下旬(2016年2期)2016-03-18 10:23:20
西北工业大学学报(2015年4期)2016-01-19 03:31:47
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
振动工程学报(2014年4期)2014-03-01 01:15:41
