
Key-value数据库在时序数据及互动信息处理中的分析应用
2012-09-17 10:31:08胡超晔张忠能
微型电脑应用 2012年11期
胡超晔,张忠能
0 引言
目前的互联网应用已经进入了Web2.0时代,互联网应用对于数据库的支持,提出了更高的要求,总的来说,挑战来自两个方面,一者是数据规模越来越大,海量存储的数据量的到来,使得原来传统关系型数据库在数据量与性能之间,原本就不平稳的平衡岌岌可危;其次,由于Web2.0本身的时代特点,读少写多的特点,已经取代了读多写少的Web1.0时代的重要特征。针对这两个IT时代的应用新特点,传统的关系型数据库表现力不从心,如何解决这个难题,成了数据库应用面临的最大挑战,必须受到高度重视。针对上述现实,Key-value数据库脱颖而出,在设计中可以与关系型数据库很好的结合,从而使得在现有服务不受影响的情况下,解决数据量大、数据访问读少写多的性能问题。
在此背景下,一种新型的Key-value数据库诞生了,这种数据库,在解决上述两个问题上游刃有余,Key-value数据库内部使用key-value结构,即多维的哈希表、有查询速度快、支持数据量大下高速写入、高并发读写等特点。
本文利用一种名叫Cassandra的Key-value非关系型数据库,结合原有的传统的关系型数据库,设计一个网站架构模型,在这个模型中,将传统关系型数据库不能胜任的功能特性,交由Key-value型数据库来处理,从而可以从容应对Web2.0带给网站的两大挑战。
1 Web2.0时代的数据变化
Web2.0时代的来临,使得计算机应用,尤其是网络应用,发生了巨大的变化。在这个更加自由的网络时代,越来越多的用户被允许同时也愿意,在互联网的世界里添加自己的心情、状态、对新闻添加评论、与人分享自己的感想和经历。这种变化,对于数据库服务器来说,主要发生在两个方面:
1.1 数据量
海量数据的产出基于两个原因:
1.1.1 用户数据
web2.0之后,出现了大量用户互动型的网站,用户可以添加博客,发送微博消息,与其他用户发生即时通信,对某篇文章进行评论,对某个观点进行投票。这些海量信息的数量相比,web2.0之前的网站,以几何级数的形式增长。同时,越来越多的人通过个人电脑接入网络,在访问网络资源的人口基数变化,也是产生更多用户数据的原因。这部分大量增加的数据,我们也称为用户互动信息。
1.1.2 系统数据
随着计算机技术的普及,各行各业电子信息化的应用越来越普遍,越来越多的系统数据就此产生,例如:工厂为自己的仪器设备增加监控仪器,仪器会每隔一段时间记录设备的工作状态,这就产生了记录用的时序数据,或者是网络应用为了提供某些非实时服务(例如统计,分析)而记录的日志,网络游戏中记录的游戏过程等。这些数据数量庞大,当需要记录到数据库中的时候就会产生瓶颈。
1.2 数据的访问方式
Web2.0之前的数据访问形式往往是这样:编辑或网站工作人员,将组织好的文章或其他网络资源放在网页上,然后用户访问这些资源,这样的形式,对于后台服务器来说,主要是读的操作(用户),少量写的操作(网站编辑或者工作人员),即写少读多。而web2.0之后,应用形式和数据量的改变,使得数据的访问形式发生了大量的变化,用户自己将文章、照片、视频等上传网络与其他用户分享,而其他用户往往只是阅读其中的一小部分,这样对于后台服务器来说,承载的主要压力,将来自于写(用户上传网络资源),而小部分的读(用户访问其他用户的上传内容),即写多读少是目前网站的主要访问模式。其中主要的写操作的内容,就是前面提到的用户互动信息和时序数据。
2 关系型数据库的局限
2.1 传统关系型数据库网站的架构
传统的仅适用关系型数据库的网站的主体架构,包含如下部分:应用服务器集群、中间件服务器集群和关系型数据库集群。
应用服务器集群,负责处理用户请求,向后台申请数据,前台逻辑处理等。
中间件服务器集群,负责控制连接池,是数据库为应用服务器服务的桥梁。
关系型数据库集群式数据的集中存储,接受来自前台的数据请求,提供数据。
其简略的架构图,如图1所示:
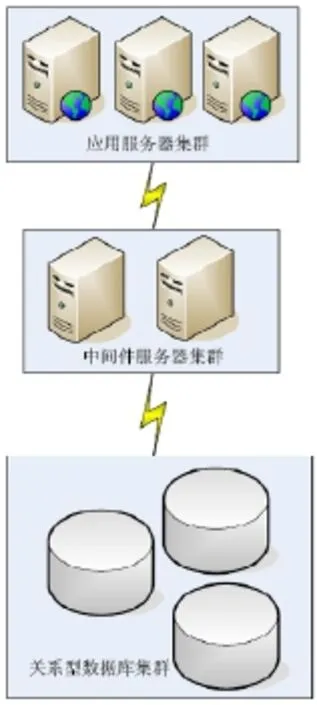
图1 关系型数据库网站的架构
2.2 传统关系型数据库的局限及其原因
在上图的模型中,一般而言,当用户数量成倍增加的时候,应用服务器集群和中间件服务器,仅需要线性增加就可以满足需要,但是对于数据一致性要求极高的关系型数据库来说,问题就没有那么简单了。
对于,目前的关系型数据库(即使是其中最优秀的关系型数据库,例如Oracle)显得越来越力不从心,主要方面体现在:
1. 单位时间产生的海量数据,关系型数据库来不及处理,
2. 网站规模越来越大,单节点关系型数据库,无法提供数量如此巨大的服务,多节点关系型数据库的扩展性,面临挑战的问题会存在,如表1所示:
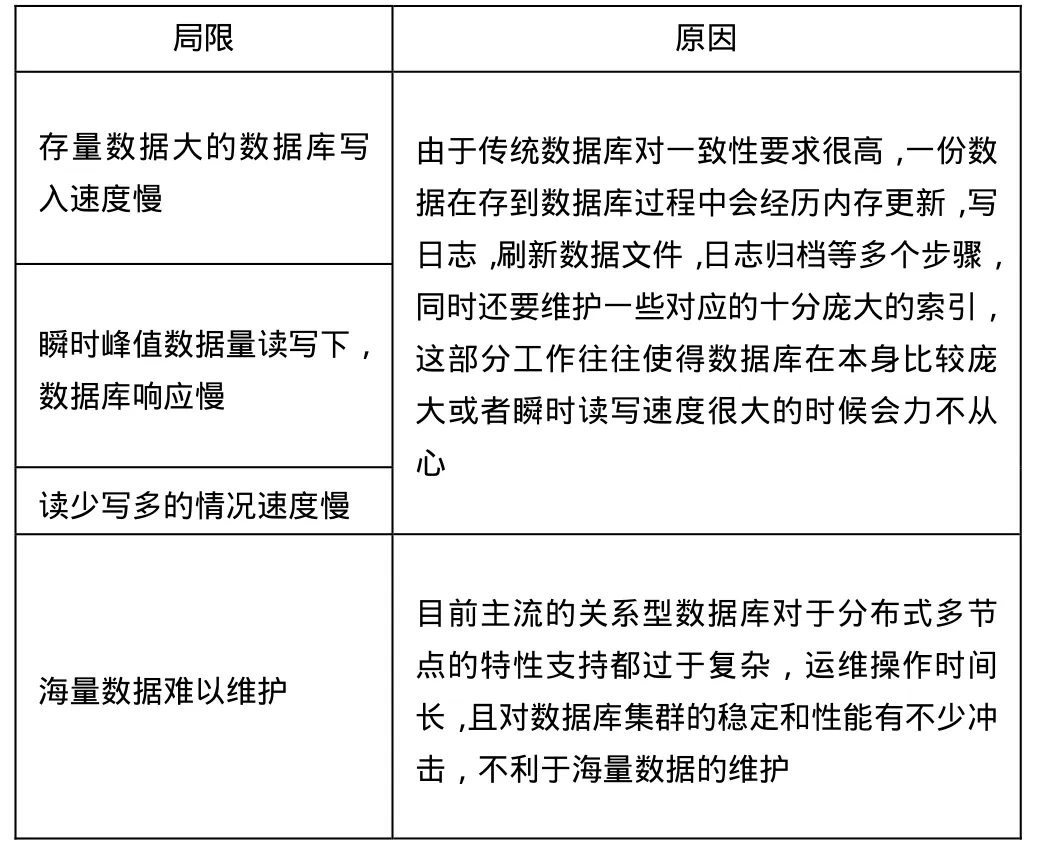
表1 关系型数据库的局限和原因
2.3 弥补关系型数据库的思路
在Web2.0下,关系型数据库力不从心的部分,主要是在用户互动信息数据以及时序数据,原因在于,关系型数据库的机制是高度一致性,根据 CAP理论,Consistency(一致性),Availability(可得性)和Performance(性能)之多获得其二,关系型数据库一直强调的是C和A(A在有用户访问的情况下是必不可少的),所以必然会丧失 P,这也就是关系型数据库的性能不尽如人意的原因。而现在实际情况是,用户互动信息数据以及时序数据的时候,往往是少量的(数据读少写多,相对于写,少有人来读)或者是非实时的,我们所需要的是性能,所以根据这个理论,我们可以考虑牺牲C来获得P。Key-value数据库正好可以满足这样的需求,通过非实时一致性(最终一致性)来大幅度提升数据库的性能,从而实现高并发读写。
3. Key-value数据库的应用
3.1 Key-value数据库的特点
Key-value数据库属于非关系型数据库,也称Nosql,全称是Not Only SQL,是一种不同于关系型数据库的数据库管理系统设计方式,其查询访问方式不是通过传统的SQL,而是通过其各自提供的 API。Key-value数据库强调并主要满足庞大的水平扩展性。NoSQL的最主要特点,就是可以处理超大量的数据。本文以Key-value数据库Cassandra为例,做一介绍。
3.2 Cassandra特点的介绍
Key-value数据库的结构与传统关系型数据库不同,以Key-value类型的表结构为主(例如Cassandra等,本文也主要以Cassandra为主要举例对象)
Cassandra是Apache的一个自由,开源的分布式数据库,其主要结构特征如下:
3.2.1 Key-value结构
Key-value的结构,区别于关系型数据库中主外键的模式,key-value的结构,使得关系型数据库表结构的定义更加自由,其中value中可以包含不定的column,而且可以不用预先定义,这样数据库在导入数据的时候,就不会有过多的校验部分,这样可以很明显地提高效率。Key-Value的组织形式,如图2所示:
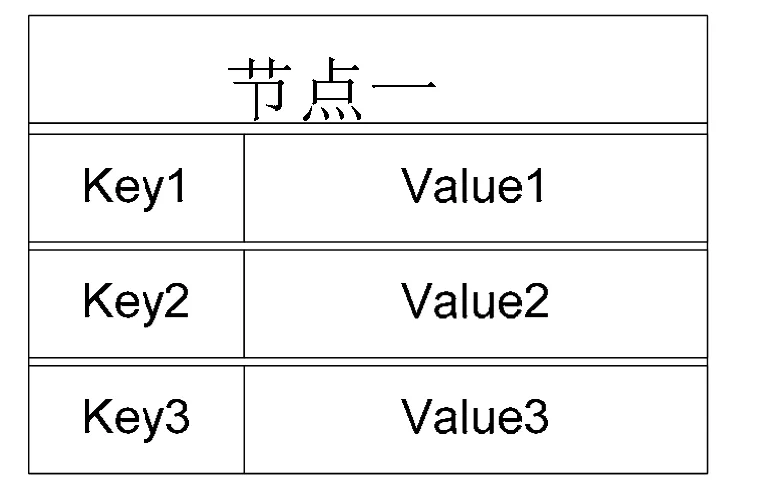
图2 关系型数据库网站的架构
Cassandra的表结构采用Key-value,即多维的哈希表,在存储数据前不需要预先定义列的含义,而是根据key值将数据以column的形式存储。Column的个数,格式可以每行不同
3.2.2 分布式
Cassandra的部署是采用分布式结构,即多个节点共同组成了数据库,多个节点可同时访问,同时读写操作,这样的结构使得数据库有很好的水平扩展性,同时,如果设置冗余,可以有效的提高系统的高可用性,从而使得数据库更加可靠。
3.2.3 无中心节点的对称结构
无中心的设置,使得数据库能够保证其负载均衡,同时这样的结构,也使得添加,减少节点比较容易实现。
Cassandra分布式结构及无中心对称结构,如图3所示:

图3 Cassandra分布式对称结构图
3.3 由Key-value数据库Cassandra参与的网站架构
针对Web2.0的网络应用特点,Key-value数据库是对关系型数据库的一个很好的弥补,由Key-value数据库来处理海量的数据,而关系型数据库处理过去经典的业务逻辑,两者配合,发挥各自优点,可以做到相辅相成,相得益彰。
Key-value数据库Cassandra为基础的网站架构图,如图4所示:
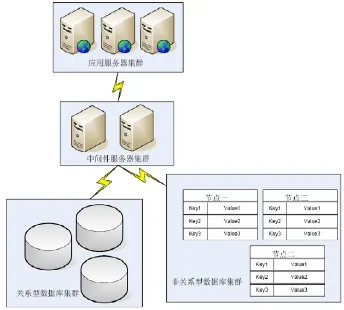
图4 由Key-value数据库Cassandra参与的网站架构
其中,Key-value数据库集群部分与关系型数据库部分同时与中间件连接,由应用服务器或中间件来判断选择,使用何种数据库集群来读取数据,判断原则一般为:重要的,少量的数据存储于关系型数据库中;不重要的,日志性的(例如,系统日志、用户评论、微博信息、游戏日志)数据,一般,也就是本文重点针对的用户互动信息或时序数据由Key-value数据库负责。
3.4 性能对比
对于关系型数据库和Cassandra数据库做了个简单的对比。
测试方法:在两台CPU为IntelQ8400,内存2G的服务器上,分别按照Oracle和Cassandra(均为2节点数据库),并在不同存量数据的情况下,做插入数据的实验,测试其速度,结果,如表2所示:

表2 关系型数据库与Cassandra数据库在不同存量数据的情况下的数据插入速度
4. Key-value数据库的优势
Cassandra与传统的关系型数据库,有十分显著的区别,这种特点,正好对于满足时序数据处理以及用户互动数据处理十分合适,因为:
4.1.1 高并发读写性能
Web2.0网站要根据用户个性化信息,使得数据库并发负载非常高。关系数据库可以勉强做到上万次SQL查询,但是对上万次SQL写数据请求,就比较困难了,而Key-value数据的强大的可扩展性以及分布式的结构,可以很好地应对这一特点。Key-value数据库不需要在写数据文件的过程中优先写日志,从而不会引起数据库因为日志文件没有写好而挂起,同时,由于数据文件本身,就是由key-value形式的哈希表构成,所以不需要额外的索引开销,同时对于数据提供了极好的支持,最终达到高并发读写的特点。
4.1.2 海量存储
对于大型网站,每天用户产生海量的用户动态,对于关系数据库来说,在一张亿条记录的表里面进行SQL查询,效率是极其低下乃至不可忍受的。而这对于Key-value数据库来说,key-value形式的存储结构,使得对于数据量有很好的提升
4.1.3 高稳定性及高可用性
在基于 web的架构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,你的数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点,来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展,是非常痛苦的事情,往往需要停机维护和数据迁移,为什么数据库不能通过不断的添加服务器节点来实现扩展呢?分布式无中心的Key-value数据库,使得数据库可以保持相当的冗余性,合理的配置可以避免单点故障的发生。
4.1.4 数据库事务一致性需求
很多web实时系统,并不要求严格的数据库事务,对读一致性的要求很低,有些场合对写一致性要求也不高。因此数据库事务管理,成了数据库高负载下一个沉重的负担。对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出这条数据的,但是对于很多 web应用来说,并不要求这么高的实时性。
对于一些互动类的业务、用户评价等,用户并没有实时查询到其他用户评价的需要,只要可以有最终一致性,就可以满足用户的需求。
4.1.5 方便的可扩展性
其次,分布式无中心的结构,也使得数据库具有很强大的水平扩展性。
由于没有中心节点,所有的节点都是对等的,所以在增加和减少节点的情况下,就会变得比较容易,速度也会比较快,大大降低了维护的成本和开销。
4.1.6 对复杂的SQL查询,特别是多表关联查询的需求
Key-value数据库不擅长进行关系型查询,但是这点在处理时序数据以及互动数据的处理来说是可以规避的,在大型SNS网站中,大量的用户数据产生,但数据的查询,可以通过用户以及时间点进行key值建立,所以,应用可以方便地通过这些信息定位到key值,从而获取了value里的数据。
5 结论
随着IT应用的发展,越来越大的数据量的需求产生,于是我们需要更加有力的数据库的支撑,Key-value数据库为一种最新的数据库,打破了传统关系型数据库垄断的局面,可以以新的思路、新的方式解决新的问题。
Key-value数据库能够:
1) 加载更大的数据量
2) 强大的水平扩展性
3) 强大的读写并发
这些Key-value数据库优越表现在如果可以和传统的关系型数据库相结合,必定能使得其在web2.0时代,得以充分的发挥其优势。
[1]王珊, 萨师煊,数据库系统概论 2010.6
[2]西尔伯沙茨 数据库系统概念 2006.10
[3]Eben Hewitt, Cassandra:the Definitive Guide 2010.3
[4]Prabhakar Chaganti, Amazon Simple [DB]Developer Guide Jun 2010 2010.4
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
中国农业信息(2021年3期)2021-11-22 06:44:48
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
电子制作(2016年15期)2017-01-15 13:39:08
雷达与对抗(2015年3期)2015-12-09 02:38:50
