
基于多层次的语义网信息检索浅释
2012-09-14 07:41:04桑琰云
图书馆学刊 2012年9期
桑琰云
(烟台大学图书馆,山东 烟台 264005)
不论是基于分类目录的搜索引擎检索技术,还是基于含有指定目标的全文搜索引擎技术,都存在查准率、查全率偏低的问题,也就是检索利用的有效率偏低。再加上用户检索用词的自由化,不同系统数据库标引语言的兼容,一词多义或者多词同义,还有分词的歧义与错误,常常会导致自然语言与规范语言的差异。上个世纪80年代在SIGIR会议论文中,[1]就出现了对语义信息检索的讨论。随着语义网信息和语义信息处理发展水平的不断提升,语义网信息检索的关注度才有所提升,但还是相对薄弱。2003年开始,国家的973计划开始将语义的相关基础研究、技术研究、模型研究、方法研究作为重点支持对象。笔者通过维普资讯数据库平台发现,从2005年开始,相关语义的文章才开始出现,以“语义信息”为题名或者关键词的文章有20余篇,但是如果细化至“语义网信息”、“语义网检索”、“语义网信息检索”,涉及的文章一般只有四五篇,因此笔者旨在语义信息研究的基础上,以多层次为切入点,探索多层次语义网信息检索的相关理论。
1 语义网资源
语义的核心是共享,[2]是自由,它的存在将实现从字符检索到概念检索的过渡。语义网(Semantic Web)是一个通用的语义框架,不仅将文档对象、数据共享和集成,更是将世界对象资源及资源之间多而杂的关联关系通过机器可阅读和理解的信息利用语义、语法和逻辑规则集合在一起组成的网络。在语义网中定义和链接的数据都能被各种不同的应用以更为有效的方式查询、重用和集成。无论是简单的描述语言还是复杂的描述性语言都是由某种语言作为载体,对知识进行客观描述,让机器能够具有智能评估的作用,在一定程度上提高我们分析网络信息语义的能力。有了语义网资源,计算机不需要人工的干预就可以对不同来源的这些语义网资源进行配置、聚合和解释,“使用有限的科学术语进行提问和基本数据极端复杂性之间的差距将有可能缩小”。[3]
1.1 本体
本体——表达的核心,“它给出了构成相关领域词汇的基本术语和关系,以及结合术语和关系来定义词汇的外延规则”。[4]其目标是在语义正确的基础上具有对语言的描述理解能力和完成推理的能力。计算机界的本体研究始于20世纪90年代初期的知识基础社(knowledge base community)研究之后,各个学科都开始致力于本体的研究。借鉴不同领域的本体的不同内涵,笔者认为语义网的本体是表示语义网中实体、类、属性、角色、功能等特定词汇及词汇之间关系的具有“四化”特点(概念化、明确化、规范化、理解化)的集合。是语义网检索的核心部分,是语义共享的基础。刘康[5]根据不同的分类体系对本体有不用的分类,无论哪种分类的本体,其特定词汇的概念和面向对象中词汇的概念有着本质的区别。万维网上的DAML本体库、Schema Web、Protege本体库等都是目前语义网资源的主要来源。[6]在这里需要提及的是元数据。元数据是关于数据的数据,它为数字化信息集合提供规范、普遍的描述方法和检索工具。元数据本身可以看成是本体的一种形式,或者是“元”元数据,或者是简单的本体。前者注重的是资源分类体系和资源本身的信息描述,后者注重的则是表达资源语义逻辑的知识体系,因此,对一个系统中实体进行分析并提取属性的过程即为元数据的创建过程,在此基础上再加之异构分析、关联分析等就可以创建本体了。元数据解决了资源的语义描述问题,而本体解决了资源集合的相互关系问题。[7]语法和语义、微观和宏观,两者的渗透和结合就能够完成在元数据框架下的语义检索。
1.2 本体文档资源
笔者认为该类资源是从资源描述的角度看,是构建在本体中描述文档类和属性的资源。该类资源用RDF的二元数据模型作为基础模型,用RDFSchema作为描述词汇表,模型中用于描述本体文档资源的都可以被看成是“节点”。但由于RDF的不全面性,RDFS作为其扩展更具完善性。
1.3 实例数据资源
表征各类对象的实例数据。语义网支持互操作和集成不同来源的数据,[3]尤其是关联数据。此要求比较普遍。大多数的检索者还是想从本体的知识库中搜集到特定类目的实例信息。与传统资源不同的是,该类型的语义网资源是基于结构化查询与处理的。
1.4 语义关联资源
表征文档与数据之间的语义关系数据。目前兴起的语义关联检索的研究已有涉入。知识组织的技术方法除了可以组织隐含在知识资源中的知识结构之外,还要使其中的语义元素能够被计算机所交互。目前来看,我们现在的传统检索方式出于弱语义的知识表征阶段,它相对于自然语言而言承载着一定的语义,但还是有所差距。语义关联资源不仅局限于有直接关联的主题之间,还包含对非直接关联的主题之间的语义间接关联。
实例数据资源和语义关联资源单纯用RDF(S)已经不能够完全表达语义,这就需要另外的本体语言OWL和DAML+OI来完成。[8]
2 多层次语义网结构
根据朱成兵的语义网体系结构的划分,再结合笔者上述对语义网资源的特质描述,可以得出语义网的机构有一定的层次。零加工和初次加工或者多次加工的原始信息、元数据或模式信息,信息的层次越高,信息越抽象,越需要机器自动化处理,因此,语义网至关重要的是要建立出语义网的信息层次结构。
2.1 知识结构层——浅层概括层
笔者把这层等同于传统信息检索的知识数据库层,当然这层的基础还是离不开Unicode及其表征网络社会关系的URI,[9]用于负责处理信息资源的编码和信息资源的标识。有了这个编码和标识基础就能为知识结构层打造基础。之后,通过使用标准XML把不用维度、不同指标的信息数据纳入到自身的“命名空间”[8]内。该层从语法上表述信息的结构和内容,比如一词多式、一词多义、习惯用语等,也可以理解为普通的语言层次,不能表达机器可以理解的形式化的语义,缺乏灵活性。
2.2 语义仓库层——深层概括层
该层对应着语义分类内容的知识数据库。也是这个语义网的整体架构,包括主题设计、子主题设计、事实表、维度表等的设计。[9]从知识数据库的定义内涵我们可以引申出该层所包含的3个方面,即语义仓库结构设计、语义仓库管理、语义仓库应用。该层次对应的是一种解决方案,能够解决分散异构数据的综合、集成。该层的建立需要在传统知识库的基础上以数据挖掘、模糊数学[8]和OLAP技术为新的方法,利用一定的语言规范(如RDF)进行主题词的编码、同义词的编码、词语变化的编码、语言线索的编码等。这样不仅可以多方面地集成数据源,而且可以消除“数据监狱”的问题达到数据的统一性,真正使数据具有“多维集”的特征,并被机器所理解。该层可以是视图,可以是物化视图,当然也可以是文档。实现浅层概括层或者原始数据到深层数据层的信息转换。
2.2.1 主题品质层
该层及其之后的程度层都是在深层概括层之下的细化层次,严格意义讲是分层结构。在概括层的基础上进行ETL设计,表达每一个语义的特征层次结构,每层由个体、特性、动作等语义结构有序地组织而成。例如对于问题:“2011年工资水平”,“高”与“低“即为该品质层所要解决的语义问题。而对于高的人数所占的比例则可以认为是程度层所解决的语义问题。
2.2.2 主题程度层
该层是与上层处于同一层次的层,即为深层概括层之下的细化层次。表征的是语义的程度,比如工资高的人数所占的比例。比如一个本体对象的颜色、纹理、形状、运动矢量等等都是该层所反映的。
2.3 逻辑证明信任层
该层次包含了逻辑层、证明层和信任层。[9]逻辑层用于描述推理规则,是对用户需求进行分析、定位、验证的基础。证明层是用于提供的验证机制,可以证明所提供给用户的信息源、数据源和结论都是正确的、可靠的。信任层通过“证明”交换和数字签名(Digital Signature)技术,可以建立信任关系,保证语义网的可靠性以及用户和代理之间的信任性。
2.4 接口互动服务层
根据咨询用户的查询请求进行匹配、提炼,通过与语义仓库中的相关知识域相链接,最终得到咨询用户相匹配的咨询结果。笔者认为除此之外,该层还应该包括以往咨询用户之间的互动,或者包含用户相关的意群互动,这样当用户想知道更多咨询答案的来龙去脉就很简单了。
这些层次结构通过从低到高的逐层拓展形成了一个功能、内容逐渐增强的检索体系(详见图1)。
3 基于多层次的语义网信息检索模式
语义检索是指借助于本体和查询条件进行语义推理得到查询结果并输出到客户端的过程。该过程通过本体构建、复用、确立等级体系、语义映射关系、[10]数据摄取、信息互操作、可视化等一系列步骤才能实现语义网信息检索。
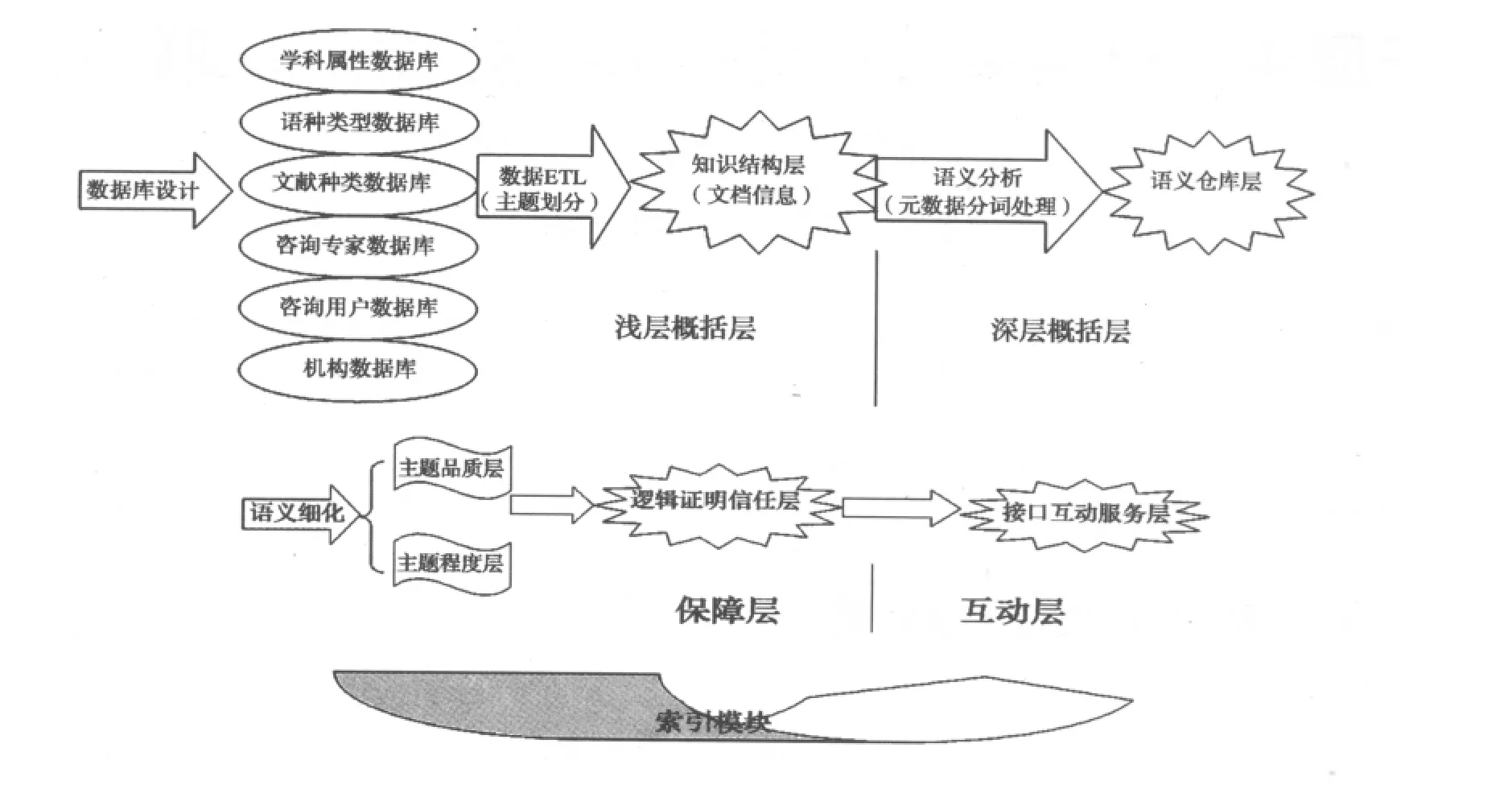
图1 多层次语义网的层次结构
根据数据库中一定的标准进行主题划分,可以根据数据库所属的咨询检索范畴或者学科属性或者咨询需求等完成主题划分,之后根据主题来进行事实表的设计和维度表属性的设计,当然这步必须与主题的划分一一对应又紧密相连。之后根据不同种类进行主题分割或交叉。然后通过ETL技术对已分类的数据进行获取、过滤、清洗、转换、装载、校验,[9]传统的信息检索止于此,也就是上文提到的知识结构层。而语义信息网则需要在此层数据的基础上进一步加深表示。这就需要元数据的设计,从而实现以上数据的本体表示。这也是实现检索的关键环节,即进入语义仓库层。这一步包含了对知识结构层内知识概念的同义词、上位词、下位词、属性等的关系的语义扩展,包括确立概念的等级体系、概念之间的语义映射关系及语义关系的推理原则等。[10]语义细化得出主题特征层和主题程度层,根据具体领域的应用并参照应用的扩展性来建立新命名空间的新本体,完成了索引模块。对已建立好的索引模块中的本体信息资源所在的本体进行语义推理,针对用户的查询请求对本体的各种文件进行查询匹配,最后将匹配的结果排序输出。[11]该过程与图1中层次结构图是相呼应的。
单从用户的端口看,用户输入咨询信息后,首先进入到关键词提取程序,进入关键词的术语开始进行术语形式匹配,从而得到相应的本体信息,例如类、实例、属性等,[12]这样就将知识数据库中的概念与关键词查询中的术语联系了起来。在用户输入查询请求后,转换为语义网表示的信息,从而得到本体信息进行语义查询,最终进入检索模块。
最后笔者认为在索引模块和检索模块还有一个语义的扩展,就构成了上文提到的接口互动层。
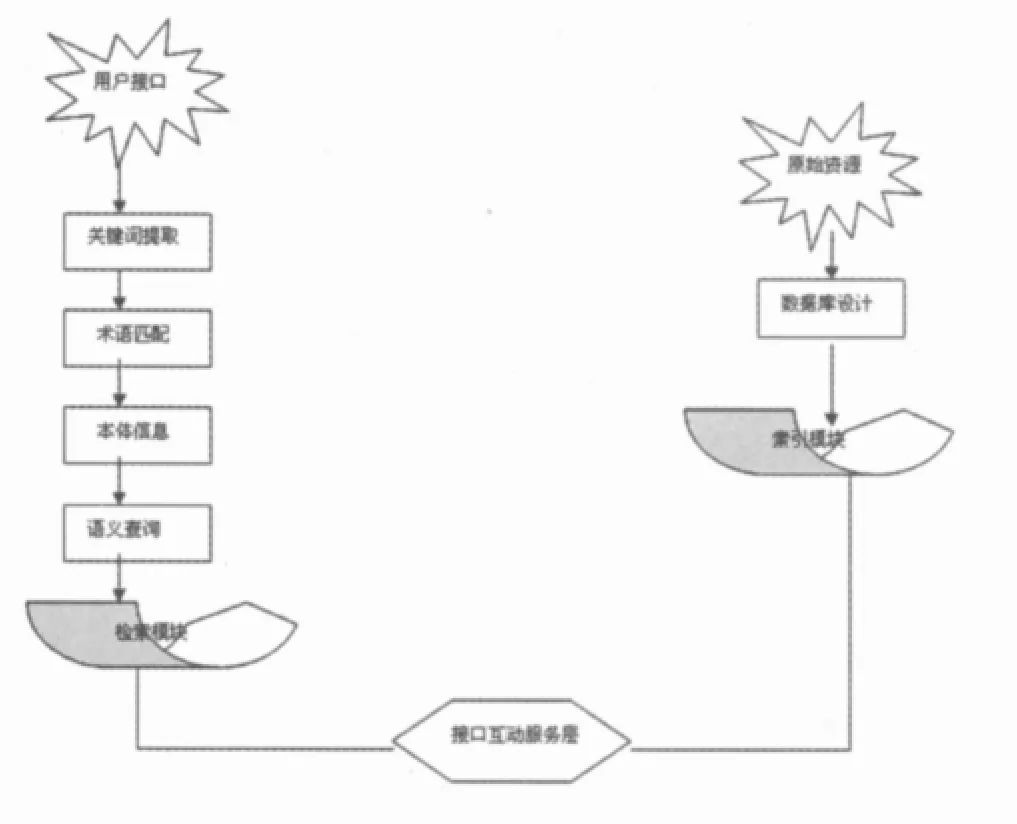
图2 多层次语义网检索模式
4 结语
语义网的信息检索离不开资源的收集、索引的建立、语义的集成和用户的检索,其中索引的建立和语义的集成又是重中之重。当然,这一系列的检索流程中有些还有待进一步研究。比如本体的集成、本体的评价、语义化、查询消歧、[1]单一语义映像、多层语义互联、语义空间统一[13]等等都是难点。
基于多层次的语义信息检索与传统的网络文献检索相比才可谓真正的信息检索,其检索平台作为一个基于资源和以用户为中心聚合资源的服务系统,都有其自身主题的抽象或者概括,即语义框架。多层次的语义网信息检索在基于前提条件和效果匹配的前提下考虑了输入输出参数的匹配,很好地满足了用户的非功能性要求。它更能表达和处理信息的语义内容,提供的不仅仅是相关文档的链接,传统遍历、信息组合的过程已经通过语义信息检索的方式表现出来。
[1] 黄敏.语义检索研究综述[J].图书情报工作,2008(6):63-66.
[2] 汤怡洁,周子健.语义Web环境下语义推理的研究与实现[J].图书馆杂志,2011(3):69-75.
[3] The eScience Revolution:Rensselaer Researchers to Create Semantic Web Platforms for Massive Scientific Collaboration.[2009-10-01].http://www.eurekalert.org/pub_releases/2009-10/rpi-ter100109.php.
[4]Neches R,Fikes R E,Gruber T R,et al.Enabling technology for knowledge sharing[J].AI Magazine,1991(3):36-56.
[5] 刘康,黄奇.语义网中的重量级本体的设计[J].图书情报工作,2006(6):42-45.
[6] 王雨英.基于本体的信息检索研究[D].中国海洋大学,2006.
[7] 花开明,陈家训,杨洪山.基于本体与元数据的语义检索[J].计算机工程,2007(24).
[8] 杜文华.语义网描述语言比较研究[J].情报杂志,2004(9):40-42.
[9] 章志龙.基于语义网的博客搜索系统研究[D].武汉理工大学,2009.
[10] 王知津,王丽娜,胡玲玲.智能检索环境下的索引编制[J].图书馆杂志,2011(1):16-19.
[11] 李桂华,汪学明.语义信息检索框架设计及其算法研究[J].计算机技术与发展,2010(8):41-44.
[12] 袁杰,等.基于本体的领域Web搜索模型与架构[J].计算机时代,2008(5):22-25.
[13] 席彩丽,李莹.面向数字图书馆的分面语义架构研究[J].现代情报,2010(12):15-17.
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
中国音乐学(2020年4期)2020-12-25 02:58:06
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
新闻传播(2016年18期)2016-07-19 10:12:06
专利代理(2016年1期)2016-05-17 06:14:36
现代计算机(2016年11期)2016-02-28 18:35:15
文学教育(2016年27期)2016-02-28 02:35:15
河南科技(2014年11期)2014-02-27 14:10:19
卷宗(2013年6期)2013-10-21 21:07:52
图书馆界(2013年5期)2013-03-11 18:50:29
