
面向科研学术对象服务的个性化图书推荐系统研究
2012-09-14 12:52:02阴江烽中共广东省委党校图书馆广东广州510053
探求 2012年4期
□阴江烽(中共广东省委党校图书馆,广东广州 510053)
面向科研学术对象服务的个性化图书推荐系统研究
□阴江烽(中共广东省委党校图书馆,广东广州 510053)
针对科研学术读者这一读者群体,应构建一种基于协同过滤算法的图书推荐系统模型。本文通过分析其兴趣分类、角色特征、行为模式等特征,对算法进行改进,降低数据稀疏性对系统的影响,使系统推荐结果更符合科研学术读者这一群体的阅读选择习惯,提高推荐系统效率。
图书推荐;个性化;协同过滤
个性化图书推荐系统已经成为现代图书馆提供以读者为核心的个性化服务的重要手段,目前协同过滤(CF)是最成功的个性化推荐技术,它借助已知的用户评价来实现对目标用户的推荐。典型的协同过滤推荐算法是基于用户的协同过滤推荐算法,其基本原理是利用历史评分数据形成用户邻居,根据评分相似的最近邻居的评分数据向目标用户产生推荐。[1]而形成用户的最邻近用户集是协同过滤推荐算法中最为关键的一步,但传统协同过滤推荐算法存在稀疏性问题,用户对资源项的评价非常稀疏,以稀疏的评价产生用户间的相似性可能并不准确,从而影响了算法的准确性。[2]针对这些问题有很多改进算法,这些算法大部分集中在对最邻近用户集的选择改进上,即针对读者特征的差异进行改进。而科研学术对象有其自身的特点,本文引入读者的兴趣分类和角色身份分类等因素,提出一种针对面向科研学术对象服务的个性化图书推荐系统。
一、传统协同过滤推荐算法及其不足
(一)传统协同过滤推荐算法
传统协同过滤推荐算法基于以下假设:如果用户对一定项的打分较相似,则他们对其他项的打分也较相似。它是以用户对项打分的I-U评分矩阵作为学习用户偏好并产生推荐的基础。该算法可以分为三个阶段:[3]
1、构建用户I-U评分矩阵。用户的评价和偏好表示为一个m*n的I-U评分矩阵R。其中m是用户数,n是项目数,R=[rij],元素rij代表用户i对项目j的评分。
2、获取用户的最近邻。“最近邻居集”就是根据相似度从大到小排列的“邻居”集合。其中两个用户之间相似性的计算需要获取两个用户所有已评分的项目和数据,然后用一种度量方法进行计算。常见的度量方法有余弦相似性、修正余弦相似性、相关相似性等。相关相似性一般由Pearson相关系数度量,[4]计算公式如下:
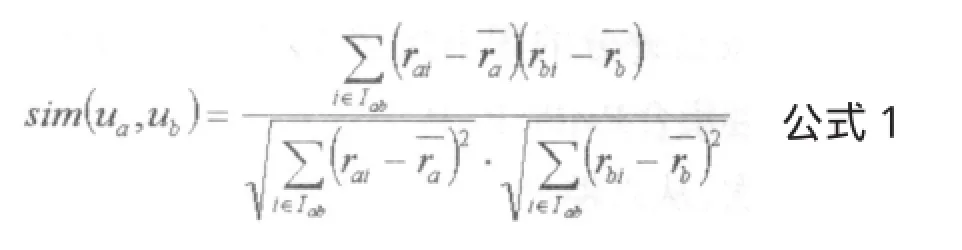
其中,sim(ua,ub)是用户ua和ub的相似度,集合Iab是用户ua和ub共同评分的项目集,rai、rbi分别表示用户ua、ub对项目i的评分分别表示用户ua和ub对所有项目的平均评分。
3、产生推荐集。产生“最近邻居集”后,基于最近邻居集计算目标用户i对未评分项目x的预测评分值,并产生top-N推荐集。预测评分计算方法如下:
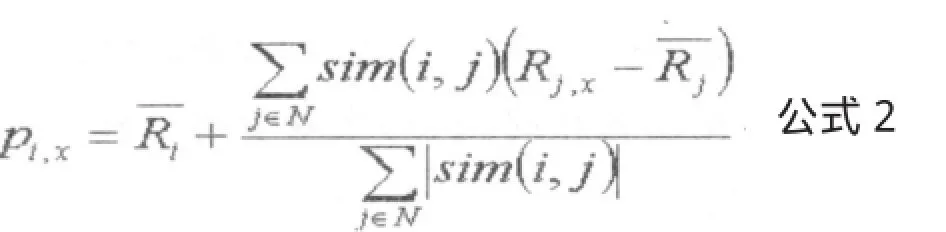
其中,pi,x表示目标用户i对项目x的预测评价值?为用户i的平均评分值,N为目标用户i的最近邻居集,j为最近邻居集N中的一个用户,Ri,x为用户j对项目x的评价表示用户j的平均评分值。
(二)传统协同过滤推荐算法的不足
首先,传统协同过滤推荐算法忽略了项目与项目之间的联系,以及读者兴趣的差异。由传统协同过滤推荐算法的过程易见,在第二步计算用户相似性的过程中,计算对象采用了两个用户之间所有的共同评分项目进行计算,这些项目中有很多项目与目标项目并不相关,即其所寻找的是与目标用户的兴趣组成、鉴赏水平、评分习惯完全一致或高度一致的用户群。而我们知道没有哪两个用户是完全相同的,每个独立用户的兴趣都是多样化的,并且兴趣也是多变的,每种兴趣产生时间及其持续时间也有不同。在这种情况下,传统协同过滤推荐算法只能找出用户持续度最强的兴趣而忽略了用户次要兴趣和新产生的兴趣热点,并且可能产生推荐出用户曾经长时间感兴趣但现在兴趣降低或消失的项目。
其次,传统的协同过滤算法存在数据稀疏性问题。由于资源的海量化以及兴趣的多样化,评分数据往往是比较稀疏的,这样会造成算法精确度的降低。例如目标用户A和用户B分别各对10个项目进行了评分,这其中只有2项相同,但在数据稀疏的情况下,B依然被选做了A的最近邻。那么我们根据B对项目k的评分计算出的目标用户A对项目k的评分显然是不准确的。
本文研究的方向为面向科研学者这一特定服务对象的图书推荐系统,基于以上的分析,本文认为针对此特定读者群体的特征以及项目的分类,对I-U评分矩阵及最近邻的选择做出优化就是一种简单易行、效果也比较显著的方法。
二、科研学术读者对象的兴趣特征
(一)兴趣的长效性
科学研究不是一蹴而就的,而是一个持续的、不断积累的过程,大部分成果都是产生在持续不断的研究之上的,很多科研工作者和学者甚至用一生去追求一个真理的答案,这就决定了他们的主要兴趣是具有长效性的。反映在图书推荐系统数据中就表现为,某一类图书的借阅记录和评分记录贯穿了这个读者行为记录的始终,不会出现较长期不借阅或评分此类图书的情况。
(二)兴趣的时效性
根据研究领域和方向的不同,甚至是研究阶段的不同,研究的内容会随着不同的热点发生转移,一些时事性强的领域更是这样,比如国际政治、应用经济等等。也就是说在某些情况下,读者的阅读兴趣会发生改变,一些曾经比较关注的问题,现在的兴趣转淡或者消失了。反映在图书推荐系统数据中就表现为,集中出现过某一类图书的借阅以及评分记录,但是最近一段时间内此类图书的出现率为零。
(三)兴趣的偶发性
读者除了有长时间关注的问题和短时间关注的热点外,也会偶尔对独立的一两本书产生兴趣,但是这种兴趣是偶发性的,也许只是这一两本书的特定部分内容吸引了读者,而不是读者对书处的类发生了兴趣。反映在图书推荐系统数据中就表现为,某些类中的个别书籍时间间隔较长且不规律的出现在历史记录中,并且出现的频度较低。
(四)对象选择中遵循的专家性、权威性
尽管学历和职称的高低并不能代表真实水平的高低,但在大多数情况下,更高的学历和职称还是代表了一位学者在某些领域研究的时间更长,研究内容更深入,涉及到的问题更全面。当我们的读者进行研究时,通常也更倾向于借鉴专家、知名学者和权威的资料,这就是隐藏在读者选择阅读对象倾向中的专家性、权威性。根据此特点,我们可以认为,一个拥有更高学历和职称的读者,在本专业领域范围内挑选的阅读对象和对对象的评价数据,对其他读者在此领域的研究有更重要的借鉴意义。
三、算法的改进
根据上文对科研学者型读者特征的分析,本文提出了改进的协同过滤算法,以使面向科研学术对象服务的个性化图书推荐系统有更高的准确率和效率。算法主要分以下几步:
(一)步骤1:对目标用户兴趣分类
对目标用户的兴趣进行分类,选择出相对长效兴趣和热点兴趣,并屏蔽掉失效兴趣和偶发兴趣,计算每种兴趣在整体中的权重。
首先,我们对用户U的兴趣分类,即对读者已读或已评分的图书按照学科、项目分类,得到兴趣集合P=(P1,P2,P3,…Pn)。
其次,从兴趣集合中选择出相对长效兴趣和热点兴趣,并屏蔽掉失效兴趣和偶发兴趣。设对于兴趣Px∈P(1≤x≤n,x为整数),有集合Iu,pxIu,其中Iu,px=(i1,i2,i3,…,in)为读者U在兴趣Px下借阅和评分对象的集合,Iu为读者U所有借阅和评分对象的集合。Iu,px对应的时间序列为Tu,px=(t1,t2,t3,…,tn),tn为对象in发生的时间。设tmin为最早借阅或评分时间,tmax为最近借阅或评分时间,则该类兴趣中项目的平均借阅间隔,其中n为项目总数。设tnow为收集数据的截止时间,那么对于每一种兴趣Px,则有:
如果n≤2,即该兴趣分类中的书只借阅过两次以下,那么我们可以把它看做偶发性兴趣,屏蔽。
如果tnow-tmax>6(month),即从借阅一种兴趣分类的图书开始到数据截止日期,间隔在6个月以上,我们就认为其是长效兴趣。
以上皆否,则我们认为其是新兴趣或热点兴趣。
最后,我们计算所有长效兴趣、热点兴趣在读者兴趣分布中的权重Y。对于长效兴趣和热点兴趣,由于每个人的特征不同,我们无法判断哪种类型的兴趣所占比重更大,所以首先为长效兴趣和热点兴趣各分配50%比重,再在各自的范围内根据项目占总项目的比重来计算单独一个兴趣分类占总类的比重,具体如下:
设YPx为兴趣Px在目标读者U所有有效兴趣中的比重,NPx为Px的项目集合Iu,px的总项目数,Nlang表示所有长效兴趣分类中项目的总数,Nhot表示所有热点兴趣分类中项目的总数,则有:

(二)步骤2:根据不同的兴趣分类,生成其他读者的I-U评分矩阵
建立m×n维的I-U评分矩阵RPx,m为候选邻居数,n为项目即图书数,rij表示用户i对项目j的评分,但这里n并不是所有的项目,而是兴趣Px对应的项目集合IPx中的项目,即j∈IPx,其中Ipx表示所有项目中对应于兴趣Px的项目的集合。设R为数据集中所有读者和项目评分组成的矩阵,则有PPxR。大多数图书馆的读者评分数据都是非常稀疏的,因为评分是读者的爱好和习惯,有自由的选择权,相反图书的借阅记录非常全面,不管愿不愿意,只要借阅了图书,就一定会留下借阅记录,同时我们发现借阅时间能够反映出读者对信息需求的紧迫程度,[5]因此对于读者评分rij的采集,我们借鉴文献[5]的方法。
设读者i在指定时间段内借阅图书序列为(item1,item2,…,itemj,…,itemn),其对应的借阅时间序列为(t1,t2,…,tj,…,tn),设Tmin为统计时间段开始时问,Tmax为截止时间,则读者i对图书资源itemj的评分值计算公式如下:

对于没有借阅记录的项目rij的值为0。
(三)步骤3:计算用户之间的相似性,获取用户的最近邻
由上文的分析可知,科研学术读者选择对象过程中遵循隐含的专家性、权威性,因此我们在计算用户与目标用户的相似性时,应该主动提升在本兴趣领域内具有较高职称和较高学历的用户的相似性,本文考虑引入约束系数D来实现这个目标。
考虑一般情况下科研学术读者的角色特征,可以得到:职称特征集L=(1,2,3,4,5),其中值1代表非Px兴趣相关专业读者,值2代表Px兴趣相关专业初级职称及以下,值3、4、5依次代表Px兴趣相关专业中级、副高级和高级以上职称;学历特征集S=(1,2,3,4,5),其中值1代表非Px兴趣相关专业读者,值2、3、4、5依次代表Px兴趣相关专业专科及以下、本科、硕士、博士及以上学历。
设目标读者U的职称特征集为Lu,任意读者i的职称特征集为Li。我们知道对于读者来说,角色、身份的差异带来的对像选择方式的影响,并不是线性的,并且当这种差异达到一定程度的时候差异就不是很明显,即对于初学者来说副教授和教授的资料几乎有同等的借鉴价值,因此我们用正弦函数来考量i与U之间的差异,同时根据正弦函数的特性我们要取

显然,有Z∈[2/3,2],对所有的Lu,Li越大Z越小,反之亦然。而且当Li=Lu时,Z=1,即当读者i与目标读者u一致时,约束系数为1。
表示两个用户i与U之间学历的差异。
因为Z与C是同时作用于数据的,所以最终约束系数D=Z×C。
我们的目的是使具有较高角色特征的用户和目标用户的相似度增加,即其共同评分项目值向目标用户靠拢,因此我们通过约束系数D对用户的现有评分进行优化。设用户i对项目j的评分为rij,目标用户U对项目j的评分为ruj,则优化后的项目评分为:

由上式可见,当i的特征高于U时,两者之间差距缩小,相似度提升,当i的特征低于U时,两者之间差距加大,相似度降低。
最后,我们根据公式1和公式3得到改进的相似性计算公式:

根据公式4我们计算出用户与目标用户的相似度,按从大到小排序,取top-N,得到目标用户在兴趣Px下的最近邻集合。
(四)步骤4:产生推荐书目
根据步骤3产生的最近邻集合,应用前文的公式2,我们产生目标用户u对项目x的预测评分pu,x,并从大到小排列,取出top-N项,其中最近邻项目的评分采用优化前的原始数据。
(五)步骤5:得到最终推荐书目集合
重复步骤2到步骤4,找出所有有效兴趣Px下的top-N推荐,根据步骤1计算的权重,得出最终推荐书目集合I。

其中P为有效兴趣集合,YPx为兴趣Px在 P中的权重,N为I的总数表示在兴趣Px下的top-N推荐集合中取前YPxN项的集合,YPxN的值四舍五入取整。
四、总结
本文构建了一种基于协同过滤算法的面向科研学术对象服务的个性化图书推荐系统模型,并在对传统协同过滤算法过程分析的基础上,针对科研学术读者这一读者群体的特殊特征以及图书这种对象的特征,根据读者的兴趣分类、角色特征、行为模式,对算法进行了改进,使其降低了数据稀疏性对系统的影响,并更符合科研学术读者这一群体的阅读选择习惯,提高了推荐系统的效率。
[1]蔡浩、贾宇波、黄成伟.结合用户信任模型的协同过滤推荐方法研究[J].计算机工程与应用,2010,(35).
[2]李幼平、尹柱平.基于用户行为与角色的协同过滤推荐算法[J].计算机系统应用,2011,(11).
[3]王茜、王均波.一种改进的协同过滤推荐算法[J].计算机科学,2010,(6).
[4]张丙奇.基于领域知识的个性化推荐算法研究[J].计算机工程,2005,(21).
[5]董坤.基于协同过滤算法的高校图书馆图书推荐系统研究[J].现代图书情报技术,2011,(11).
□责任编辑:黄旭东
G251
A
1003—8744(2012)04—0116—05
2012—5—20
阴江烽(1980—),男,中共广东省委党校图书馆技术部副主任,主要研究方向为图书技术服务。
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
南风(2020年22期)2020-09-15 07:47:08
小学生优秀作文(低年级)(2019年5期)2019-04-25 13:13:40
汽车观察(2019年2期)2019-03-15 06:00:50
小学阅读指南·低年级版(2017年12期)2017-12-26 17:01:14
中国卫生(2016年5期)2016-11-12 13:25:26
高中生学习·高二版(2015年12期)2016-01-05 13:08:35
生物进化(2014年2期)2014-04-16 04:36:26
中学英语之友·上(2008年2期)2008-04-01 01:19:30
中学英语之友·上(2008年2期)2008-04-01 01:19:30
