
基于信息挖掘的高校网络舆情监测系统开发*
2012-07-26 06:31孙新领
河南工学院学报 2012年1期
于 琨,孙新领
(河南机电高等专科学校计算机科学与技术系,河南新乡453000)
1 选题背景及意义
目前,在我国近3亿庞大规模的网络舆情主体[1]中,学生网民规模已达到7600万人,其中高校大学生网民比例就占据了21.2%。相对于一般社会群体,高校大学生是对社会诸多现象、现实和问题等反应最为敏感的重要群体,加上高校大学生自身知识积累不足、社会阅历不够丰富、思维不够严密、情感活跃,易受到错误言论的蒙蔽和误导等特点,以及高校校园网络舆情监测与预警手段方面的严重不足,使得高校校园最易成为网络舆情的发源地和扩散地。
所以,能否对校园网络舆情进行科学正确的引导、规范,进一步发挥网络舆论的积极作用,克服其消极作用,是构建社会主义和谐校园面临的重要课题,是高校思想政治教育工作的内在要求,亦是衡量高等院校舆情应对能力的一项重要标准。
2 需求分析
网络舆情监控系统[2]需要通过对互联网上各类信息进行采集、分类、整合、筛选等技术处理,来实现对网络热点、舆情动态、网民意见等实时统计报表的具体功能。通过对热点问题和重点领域比较集中的网站信息,如:各大网站、论坛、百度贴吧、校内BBS、微博等,进行24小时监控,随时采集最新的消息和意见,然后完成对数据格式的转换及元数据的标引。同时对采集到本地的信息,进行初步的过滤和预处理。对热点问题和重要领域实施监控,并在监控知识库的指导下进行基于舆情的语义分析,使管理者看到的民情民意更有效,更符合现实。最后将监控的结果,分别推送到不同的职能部门,供制定对策使用。
3 系统设计
3.1 系统设计思路
本课题的主要思路是针对高校校园网络管理及舆情发生特点开发一个基于网络信息挖掘技术的网络舆情监测系统,利用网络蜘蛛技术、中文分词技术和文本聚类技术,通过对互联网信息采集、处理,舆情识别分析,进行公共危机和热点事件的舆情监测,对高校网络舆情进行监测和预警。
3.2 系统功能模块划分
该系统的功能模块设置如图1所示:
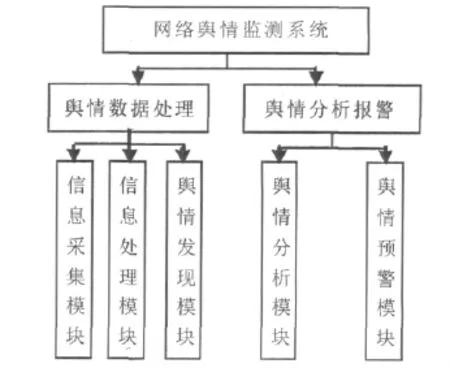
图1 系统功能模块图
4 系统实现
4.1 系统开发平台
系统采用C#作为编程语言,采用 Microsoft Visual Studio2005作为开发工具,采用客户端/服务器(C/S)与浏览器/服务器(Browser/Server)作为开发结构,数据库采用SQL Server 2005,Web服务器采用 IIS。
4.2 系统开发关键技术
4.2.1 Web 信息挖掘技术
随着互联网的蓬勃发展,数据挖掘技术被运用到网络上,并根据网络信息的特点发展出新的理论与方法,演变成Web信息挖掘技术。Web信息挖掘是指对目标样本进行分析并提取特征,以此为依据从Web文档和Web活动中抽取人们感兴趣、潜在的有用模式和隐藏的信息。所挖掘出的知识能够用于信息管理、查询处理、决策支持、过程控制等方面,信息挖掘流程如图2所示。

图2 Web信息挖掘流程图
4.2.2 网络蜘蛛技术
本文采用网络蜘蛛作为获取舆情语料的辅助工具。
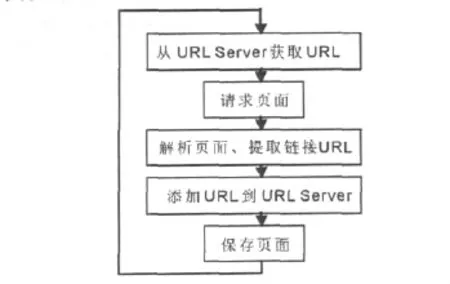
图3 网络蜘蛛工作流程图
网络蜘蛛[3]实质上是一个爬行程序,一个抓取网页的爬行程序,通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止(如图3所示)。如果把整个互联网当成一个网站的话,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
4.2.3 中文分词技术
中文分词技术是中文信息处理领域的一项基础性课题,也是智能化中文信息处理的关键,中文分词系统的实现及效果依赖于分词理论与方法。
现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。由于基于统计的分词方法对歧义、新词的识别能力强、分词的准确性高以及技术成熟、便于实施等方面的优势,结合网络舆情的特点,基于统计的分词更为适合网络舆情监测系统的研究。
4.2.4 文本聚类技术
文本聚类技术是文本挖掘分析技术的一个重要研究分支。它是在无类别标记信息的情况下,根据事物的不同特征,将事物划分为不同的组,使得不同聚类中的数据尽可能的不同,而同一聚类中的数据尽可能的相似。近年来,文本聚类较多应用于自动产生文本的多层次的类或者簇,并利用这些生成的类对新文本进行高效率的归类。
4.3 系统功能实现
4.3.1 信息采集模块
信息采集模块为整个舆情监测系统的基础模块,该模块主要完成了对指定数据采集空间内的信息资源进行采集与存储。该模块所采集的信息资源,将作为舆情分析的有效文本集。
4.3.2 信息处理模块
信息处理模块包含两个工作:分词与建立索引。该模块主要对信息采集过程采集到的文本数据库进行读取,逐条进行数据清理,去除文本中的脚本等无用信息,提取出文本的标题、内容,并利用 Lucene.Net对文本进行分词索引,为热点话题发现模块创建文本模型提供数据资源。
4.3.3 舆情热点发现模块
舆情热点发现模块是整个系统的核心模块,是舆情监控以及舆情热点的发现、突发事件的发现等功能的实现模块,该模块主要利用文本聚类技术,对获得的文本信息进行聚类分析,获取聚类中心,即舆情热点。
4.3.4 舆情分析模块
舆情分析模块使用了B/S设计模式,便于各级管理部门及舆情观察人员随时随地可观察到当前舆情信息。
系统在进行舆情分析后,利用SQL Server2005的ETL功能对舆情信息进行清洗,存储至数据仓库中,建立维度模型。ETL主要分为四个步骤:分别是抽取、清洗、一致性处理和交付。
4.3.5 舆情预警模块
舆情预警模块[4]主要是针对舆情分析模块交付的热点信息与突发事件进行监听分析,然后根据信息的语料库与报警监控信息库进行分析,将某一具体网络舆情信息的安全性划分为安全、较安全、临界、较危险、危险五个区间,从而针对某一网络舆情信息的安全指数通过图表等形式呈现给高校专业化网络政工的研判人员和监管人员的机制,能帮助他们及早发现舆情信息,从而实现对高校重大舆情事件的及时响应。
5 结语
本课题所开发的高校网络舆情监测系统,着重于实现舆情热点与话题信息的推送与跟踪功能,可进一步分析舆情内容的观点与态度问题,筛选并判定各级别网络舆情的发生,这对于高等院校充分利用网络舆情倾听学生的呼声,变网络舆情由被动为主动,进一步加强新闻宣传和信息传播的安全管理、引导舆情发展、制定策略方针,并及时采取措施进行有效的干预,缓解舆论压力,建设和谐校园具有重要的应用价值和意义。
[1] 徐楠,戴媛.面向高校网络舆情安全的监管与预警研究[J].信息系统工程,2009,(7):62 -66.
[2] 梅中玲.基于Web信息挖掘的网络舆情分析技术[J].中国人民公安大学学报(自然科学版),2007,(4):85 -88.
[3] 李振.网络舆情预测关键技术研究[D].郑州:郑州大学,2010.
[4] 罗晖霞.网络舆情监测系统研究与开发[D].太原:中北大学,2010.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
