
基于JAVA技术的搜索引擎的研究与实现
2012-07-13 03:07:46殷锋社
电子设计工程 2012年7期
焦 蕾,殷锋社
(陕西工业职业技术学院 陕西 咸阳 712000)
搜索引擎一词在国内外因特网领域被广泛使用,然而他的含义却不尽相同。在美国搜索引擎通常指的是基于因特网的搜索引擎,他们通过网络机器人程序收集上千万到几亿个网页,并且每一个词都被搜索引擎索引,也就是我们说的全文检索。着名的因特网搜索引擎包括 FirstSearch、Google、HotBot等。在中国,搜索引擎通常指基于网站目录的搜索服务或是特定网站的搜索服务。
搜索引擎是根据用户的查询请求,按照一定算法从索引数据中查找返回给用户。为了保证用户查找的精度和新鲜度,搜索引擎需要建立并维护一个庞大的索引数据库。一般的搜索引擎由网络机器人程序、索引与搜索程序、索引数据库等部分组成。
1 搜索引擎工具实施的影响因素
为了企业的生存、发展,企业必须以市场环境作支撑,不论依靠传统营销模式,还是依靠搜索引擎营销模式,只要企业考虑营销就不得不从宏观环境、微观环境两个方面来考虑营销战略实施的影响因素[1],如图1所示。
在整个宏观环境中,企业营销过程中首要监视的第一个因素应该是人口,因为市场是由人组成的。其次是与人口因素密切相关的经济环境因素,因为市场不仅需要人口,还需要购买力。再者就是人们赖以成长和生活的社会形成了人们的基本信仰、价值观念和生活准则的社会文化环境。接下来是决定搜索引擎营销模式是否存在的技术环境,最后是具有政策导向的政治法律环境。这些因素都是不可控制的,但企业必须监视这些因素的动态并对此作出反应。
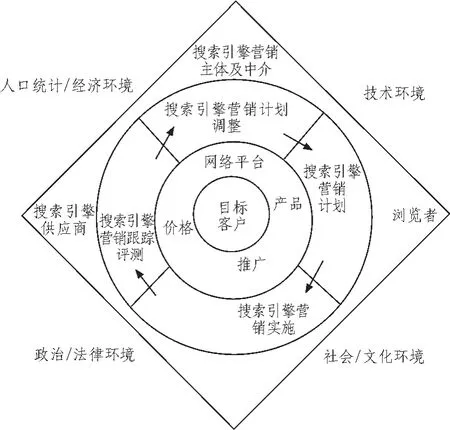
图1 搜索引擎营销实施影响因素Fig.1 Influence factors of the implementation of search engine marketing
相对于宏观环境,企业在微观环境下更能发挥其主动性。对于那些决定利用搜索引擎进行营销的企业来说,竞争对手、搜索引擎供应商、浏览者、搜索引擎营销中介是他们在得到目标客户之前必须考虑的,因为它们影响着其营销策略的制定及实施。
2 搜索引擎的搜索效果优化
搜索引擎优化[3]简称SEO,与搜索引擎定位、搜索引擎排名是同一种工作,指通过对各类搜索引擎如何抓取互联网页面,如何进行索引以及如何确定其对某一特定关键字的搜索结果排名等技术的了解,对网站进行优化,最终提升网站曝光率的一项技术。
2.1 网站结构优化
目前一些企业网站结构基本由首页、公司简介、产品信息、招聘信息、联系信息等组成。这样的网站结构基本上是把网站当作电子化的宣传册,并没有充分发挥网络的互动性。为了弥补这种缺陷,可以对企业网站进行结构优化。
2.2 网站内部链接优化
网站内部结构如同企业中的各个职能部门,只有保持部门间的信息传递渠道畅通、彼此之间协调运作,才会提高整个企业的运营效率。为了提高网站内部之间的相互关联度,需要利用网站内部链接优化[4]技术,与此同时,加上一个FAQ栏目,这是因为企业通过网站在宣传产品的过程中,会遇到一些比较常见的问题,企业如果能够预先想到这样一些问题及其解答,并做成一个专门的页面,这不仅有利于访问者了解企业的产品、促成业务合作,同时也为企业避免了人力资源的浪费。
2.3 网页标题优化
搜索引擎检索结果的主要部分就是网页的标题和围绕检索关键字选取的部分正文,Ifu网站标题也是浏览者判断目标信息相关与否的关键所在,因此,网页标题对于搜索引擎至关重要,是网页优化的重要内容,必须仔细选择网页的标题。一般来说,应该遵循以下原则[5]。
首先,不同内容的网页选择不同的标题。不要将网站所有页面设成同一个标题,网页标题应该围绕该页的内容进行编排,尽量反映该页的主题内容。这样可以提高浏览者检索到信息与查询条件的匹配度,增强浏览者对网站的信任度;同时,也保证了搜索引擎在网站上获取信息的质量,根据Google的相关度得分法,这样的网站会得一个好的分数,可以增加该网站的排名级别。另外,为了保证整个网站页面不同标题的统一性及提高企业在网站上可识别性,可以在不同页面的标题中加入统一的称谓。
其次,在标题中出现关键字。在标题中出现关键字主要是为了提升搜索引擎检索结果的排名。强调在主要网页标题中设置尽可能丰富的关键字。
3 搜索引擎的软件实现
利用Java技术对搜索引擎的3个主要部件 (网络蜘蛛、索引器、搜索器)做了实现,能完成搜索引擎的基本功能。下面对在系统设计中用到的技术及具体的实现技术逐一进行介绍。
3.1 软件开发环境
在实现搜索引擎的时候用到了以下几个软件:
1)Java 2 Platform Standard Edition 5.0(Java程序开发包)
下载地址:http :l’ava.sun.com/j2se/1.5.0/download.}sp
2)Lucene 1.4.3(实现索引和搜索的Java类库)
下载地址:http:/lapache.}ustdn.org/luceneJaavaL
3)Tomcat 5.5(Servlet/JSP 容器)
下载地址:http:LLtomcat.apache.org/download-SS.cgi
上述3个程序包在相关的网页上均有详细的安装及使用方法,在此不再赘述。现主要对在实现搜索引擎是用到的相关Java技术做一简要介绍。
3.1.1 Java的Internet连接技术
网络蜘蛛为了抓取网页,首先要能够跟Web服务器通信,进行网页的下载。Java提供了许多支持Internet连接的类。一种是套接字类,另一种是与URL地址一起工作的URL类。
1)使用套接字类
网络上的每一台计算机都有很多套接字辅助计算机程序生效,这些套接字叫端口,它们都编了号。在任一台计算机上,服务器程序必须指定端口号用于“倾听”每个连接,而客户端程序必须指定端口号用于请求连接。多个客户端能够连接到同一个服务器端口,但是,每一时刻只有一个服务器程序能侦听同样的服务器端口。HTTP的默认端口为80,是一个非常重要的端口。
2)使用 URL 类
URL类允许解析URL,或者是将其拆成各个组成部分。一旦为指定的URL创建了一个URL对象,就很容易将该URL解析成主机名和路径。URL类还具有打开某个地址连接的能力,以及从该URL检索信息的能力。
3.1.2 Java中的中文处理
程序的开发过程中,在网页抓取、索引、搜索结果输出这几个部分都遇到了汉字乱码的现象,经过分析发现问题主要出现在字符编码上。目前Java已经能够很好的支持汉字,但前提是正确设置编码方式。
3.1.3 Java的多线程机制
本研究使用丁酸钠干预,结果显示,丁酸钠组SD大鼠放疗后,放射性肠损伤动物模型成功率只有83.3%,显著低于模型组的100%成功率,提示丁酸钠有可能发挥保护肠黏膜的功能。赖衍宗等[8]在结肠炎的小鼠模型中发现丁酸钠通过促进Th1/Th2/Th17类细胞因子平衡,减轻模型小鼠肠黏膜的损伤发挥治疗作用。本研究的肠黏膜形态学检测显示,丁酸钠组黏膜绒毛高度和黏膜厚度显著高于模型组,也证明丁酸钠可以保护放射治疗导致的肠损伤。
网页抓取、索引、搜索都应以多线程的机制运行,这样能大幅地提供工作效率。一个线程的工作是在后台执行程序的一些部分,而程序的其它部分能够继续运行。当用Java建立一个线程时,必须明确指出后台执行的代码,此代码包含在Java线程的run方法中。Java通过两种方法操作多线程。
执行多线程的第一种方法是继承Thread对象,Java用Thread对象来封装线程,通过覆盖Thread类的run方法来为特定线程提供代码。由于Java不支持多继承,当一个类需要继承其它类时,此种方法就不适用。执行多线程的第二种方式是执行由Java提供的Runnable接口,并在本类中建立一个:un方法。由于Java可以执行多个接口,所以它没有第一种方法的限制.下面对上述两种方法做一个简要介绍:
1)继承 Thread类
通过Java的extends关键字直接继承Thread类来建立一个线程,这种方式允许你建立一个自包含线程对象,也就是说此对象中不仅包含run方法而且包含控制run方法执行的其它方法。示列如下:

2)执行 Runnable接口
Java建立线程的第二种方法是执行Runnable接口,Java接口本身不做实际的工作,它仅定义完成工作的方法的原型。当执行一个接口时必须包含此接口的方法,对Runnable接口来说要包含run方法的代码。如下代码完成与上列相同的功能,Runnable接口用于代替Thread类。


3.1.4 JDBC应用
如果网络蜘蛛要访问大量的网站,就必须有一种有效的方式来存储驱动Web Spider的站点队列。这些队列用来管理Web Spider必须维护的大量的网页列表。为了管理如此大的列表需要用到DBMS(Database Management System)。在Java中使用 JDBC<Java Database Connectivity)提交 SQL(Structured Query Language)命令来操作数据库。
3.2 网络蜘蛛的实现
利用Java构建Spider程序是一个非常不错的选择,Java对HTTP协议具有内建的支持,而WEB上的信息大部分都是通过HTTP进行传输的。同时Java还具有一个内建的HTML解析器,在编写Web Spider程序的过程中构造了几个相关的接口和类下面逐一对其进行介绍。
1)Spider类
Spider类有3个作用。首先它作为Spider的接口提供了使用Spider的方法;此外,Spider对象管理线程池并且向启动Spider的对象报告Spider发现的页面。最后,确定Spider的工作何时完成也是Spider。Spider类允许两个附加的类来定制化Spider的操作,这两个类由ISpiderReportable和IWorkload Storable两个接口定义。
2)ISpiderReportable接口
ISpiderReportable接口定义T几类事件,Spider将这些事件送回到它的控制器,在控制器中再定义对这些事件的处理方法。执行ISpiderReportable接口的类取回Spider找到的页面,然后对这些页面进行处理。
3)IWorkloadStoralbe接口
这个接口用于定制化Spider的行为。Spider的一个主要任务是组织要访问的站点的列表,这些列表被称为作业(workload)。这个接口定义一个对象,它能从作业中存储和取回页面。
4)SpiderWorker类
Spider程序下载Web站点并将页面上的链接添加到作业中,这个基本任务由SpiderWorker来完成。Spider程序启动的时候,建立一个SpiderWorker类池,相当于一个线程池,每个线程同时处理Spider找到的页面。
5)SpiderDone 类
由于有多个同步运行的线程,所以很难知道什么时候Spider的工作已经完成。这样就需要一个对象来跟踪还在运行的线程的数量,当数量变为零时就意味着Spider的工作结束。SpiderDone类就是为此目的而引入的。
3.3 利用Lucene实现索引和搜索
Lucene[6]是一个高性能,易于扩展的 IR<Information Retrieval)Java类库,可以利用其中的Java类轻松地在应用程序中增加索引和搜索功能。Lucene完全用Java实现,具有良好的跨平台性,是ApacheJakarta项目中的一个子项目。
Lucene允许添加索引和搜索功能到应用程序中,它能索引并搜索任意能转换为文本格式的数据,Lucene并不关心数据的来源、格式、甚至它的语言,只要它能转换成文本。远程WEB服务器上的Web页面,存放在本地文件系统中的文档,简单文本文件,MS-Word文档,HTML或PDF文件,以至于其它任何能够抽取出文本信息的文件格式。同时Lucene能够索引存储在数据库中的数据,给予用户许多数据库都不能提供的全文检索功能。
Lucene[7]提供了一些核心类用于在应用程序中增加索引和搜索功能。Lucene的API接口设计的比较通用,输入输出结构都很像数据库的表今记录今字段,所以很多传统应用的文件、数据库等都可以比较方便的映射到Lucene的存储结构/接口中。总体上看可以把Lucene当成一个支持全文索引的数据库系统。
4 结束语
由于许多技术型搜索引擎频繁地改变其算法以保持公平性,造成其搜索结果排名顺序经常变动,因此企业要不断的跟踪这类搜索引擎的技术变化,及时作出相应的调整,以保持自己在搜索引擎中的优势地位。
虽然对搜索引擎的基本功能进行了实现,但还存在许多的不足,只能用作理论研究,离实用还有很长的距离。文中构建的网络蜘蛛程序利用队列和多线程机制,具有较高的效率,但只能抓取简单的HTML页面[8],对由JSP,ASP等生成的动态页面还显得无能为力,也不支持CSS (Cascading Style Sheets,层叠样式表)页面等等。在索引部分因为借用了Lucene软件包中的一个HTML解析器,虽然经过改进能较好地支持中文,但在索引时还是会经常报错,主要是这个HTML解析器只支持HTML的一个子集。
[1]土淡.搜索引擎营销研究及“ED”公司搜索引擎营销实施[D].成都:电子科技大学,2001.
[2]乔冬梅.搜索引擎现状与发展研究 [D].郑州:郑州大学,2002.
[3]刘建元.我国中小企业网络营销策略[D].长沙:中南林学院,2002.
[4]王正平.现代企业网络营销策略思考[D].武汉:华中师范大学,2001.
[5]Rusty E,Harold.Java Network Programming,3rdEdition[M].O’Reillv,2004.
[6]Java2 Platform Standard Edition 5.0 API Specification[M].Sun Microsystems,2004.
[7]吴代文,郭军军.基于Lucene站内全文检索系统的设计与实现[J].现代电子技术,2011(6):42-44,48.
WU Dai-wen,Guo Jun-jun.Design and implemention of fulltext retrieval system in website based on Lucene[J].Modern Electronics Technique,2011(6):42-44,48.
[8]张俊兰,都欣娟.基于ASP技术的数据库连接应用探讨[J].电子科技,2010(8):115-117.
ZHANG Jun-lan,DU Xin-juan.Application ofdatabase connection based on ASP[J].Electronic Science and Technology,2010(8):115-117.
猜你喜欢
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
环球市场(2017年36期)2017-03-09 15:48:21
电子测试(2015年18期)2016-01-14 01:22:58
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
计算机与网络(2014年7期)2014-03-25 10:57:07
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08 07:28:38
