
基于词汇评分的汉语作文自动评分
2012-06-29 01:55:38彭星源柯登峰陈振标
中文信息学报 2012年2期
彭星源,柯登峰,赵 知,陈振标,徐 波,2
(1. 中国科学院 自动化研究所 数字内容技术研究中心, 北京 100190;2. 中国科学院 自动化研究所 国家模式识别实验室, 北京 100190)
1 引言
作文自动评分已经成为写作评估发展的一个必然趋势[1]。MHK(民族汉语水平等级考试)的评分准则从语言、条理、内容三方面对考生的作文进行评价。其中,语言表现为句子流畅,用词恰当;条理表现为记叙、论述中,各部分衔接符合条理;内容表现为按规定的主题进行写作。最早的作文评分系统PEG[1],以及国内的李亚男[2]所侧重的研究是对语言形式的考察。而IEA[3],以及曹亦薇、杨晨[4]的方法则着重于比较相同内容的出现,以内容得分为主得到最终的作文评分。再有综合的系统,如e-rater[5]、JESS[6]等,则是从语言、条理、内容三方面综合考虑评分。
本文的研究思路是对作文的用词进行评分,进而通过作文的词汇评分来对作文进行自动评分。首先,优美而富于变化的词汇,能够体现作文的语言水平;其次,词汇的特定指代意义,在很大程度上能够反映作文的内容。因此,词汇对作文评分的语言和内容两方面都有较大地意义。本文提出的作文的评分是由作文所使用的词汇的评分叠加而得到的假设下通过实现词汇评分估计,进而计算作文评分。本文提出行之有效的词汇评分估计方法,在准确估计词汇评分的基础上可以获得较高的作文评分性能,融合各种估计方法后,性能还可进一步提升。本文的结构如下: 第二节介绍一般化的基于词汇评分的作文自动评分方法和用于对比的e-rater的方法;第三节介绍本文提出的经过改进的估计词汇评分方法;第四节分别介绍语料库、实验参数的影响和选定以及最终实验的结果;最后一节对基于词汇评分的作文自动评分进行总结。
2 传统词汇评分方法
基于作文词汇评分的作文自动评分的思想,最初来源于考试词汇大纲。在语言学习中,词汇依据掌握的难度,在词汇大纲中分为不同的等级。由此容易得到如下假设: 词汇的难度与作文水平有密切关系。基于这个假设,可以得到一个等价的衡量作文评分的假设: 作文的评分等于作文所包含词汇的评分的加权均值。用公式表示为:
(1)
其中,tj表示j词在作文中出现的次数,wj表示j词的评分,b为一个线性偏移量。这个公式为本文所提出方法的假设前提。在获得词汇的评分wj后,便能够通过式(1)对作文进行评分。
2.1 通用词汇表评分方法
通常词汇等级表是通过广泛的词频统计为基本依据,同时依靠资深的语言教师们进行经验判断得出的,MHK考试词汇等级表也同样如此[7]。
本文采用了一份包含三个等级的词汇表作为通用词汇表,共计7 277词。考虑到作文的人工评分范围为1~6分,本文将以上的词汇以一级词汇按1分统计,二级词汇按3.5分统计,三级词汇按6分统计。通过式(1)计算出作文的最终得分,b值取0。通用词汇评分方法中,利用广泛的词频和人工建立的评分等级,进行作文评分的赋值,实现作文评分的自动评定。
2.2 常规的词汇评分估计方法
常规的词汇等级方法是按照式(1)类比得到的。既然假定了作文的评分是由词汇的评分所决定,由对偶的原则,估计词汇的评分也同样可以由作文的评分入手,因此有如下假设: 作文词汇的评分为词汇所出现作文的人工评分的均值。公式表示如下:
(2)
其中wj表示j词的评分,tij表示j词出现在作文i中的次数,scorei表示作文i的人工评分。
2.3 E-rater内容向量分析法
E-rater的方法表面上并不完全相似于以上的方法。它通过作文向量与各评分等级向量之间的相似度,对作文进行评分等级归属划分,得到作文评分。但是,其本质上仍然是通过纯粹的词汇统计,得到作文等级划分的向量,此向量上的词汇的特征类似于词汇评分。其方法介绍如下[3]。
每一篇作文都将由一个词汇向量表示,同样每一个作文评分等级也可以由一个词汇向量表示。每一个词在向量中都由一个权重表示。其中评分等级的词汇向量权重的计算公式为:
wjs=(Fjs/Max(Fs))×log(N/Nj)
(3)
其中Fjs为词汇j在s评分等级中出现的频数,Max(Fs)表示所有词在s评分等级中出现的最高频数的那个词的频数,N是训练集的作文数,Nj表示j词在N篇作文中出现的作文的数量。公式的前半部分为词汇在s评分等级的归一化频率;公式的log函数部分为一个倒排文档频率,是一个词语普遍重要性的度量。作文的词汇向量权重的计算公式为:
wj=(Fj/Max(F))×log(N/Nj)
(4)
其中Fj为词汇j在某篇作文中出现的频数,Max(F)表示作文中所有词中出现频率最高的那个词的频数,N和Nj的含义同上。式(4)含义与式(3)一样,只不过针对的是单独的一篇作文。
E-rater V2中,有两种方法由词汇向量得到最终的作文评分。其一是计算待评作文向量与各评分等级的词汇向量的相似度,作文评分为相似度最高的评分等级的评分;另一方法是计算待评作文向量与最高等级评分向量的相似度,最终的作文评分为相似度与最高分的乘积。
3 改进的词汇评分的作文评分方法
现在重新回到式(1)这个假设上。可以看出,如果能够知道每一个词汇准确的评分,那么就能够计算出作文的得分。而估计词汇的评分wj通常的做法就是利用相关的训练集。已知作文评分,可以通过式(1)建立起一个方程组,此方程组在最小二乘的方法下有一个全局最优解。因此,由一个已知人工评分的训练集,可以通过最小二乘法直接得到对wj的全局最优估计,进而就可以通过式(1)完成对作文的自动评分。此方法在实际操作中,会遇到两个问题: I.实际j的取值范围非常大,方程组中的未知变量个数过多,也即方程组矩阵过度庞大。在运用最小二乘法对方程组求解的时候,需要对矩阵求逆,过大的矩阵将导致求逆的难度增大。II.式(1)对每一个词汇都有一个单独的词汇评分,也即模型的参数变量过多,如果求得训练集中的最优解之后,会出现过拟合现象。本文为这两个问题提出一种解决的思路。
将全部词汇评分划分为c个评分,每个词将属于其中一个评分,不再如式(1)中那样对每一个词汇给予一个单独的评分变量。也即式(1)变为:
(5)
其中Tij表示(1)式中归一化后的词汇频数值,也即词汇频率。pjc表示当词汇j属于c评分类的概率。wc表示第c类词汇评分的确切评分值。b为一个线性偏移量。这样,就将对词汇的评分wj的估计转化为对c个评分类的评分wc的估计和词汇j属于c类的概率分布的估计两个过程。现在本文提出三种方法来实现这两个过程的估计,同时在实现的过程中解决了以上提到的两个问题。
3.1 改进的估计方法一
分步求解pjc和wc来解决计算困难的问题,并且通过求得一个局部最优解替代全局最优解以防止过拟合的情况发生。在本方法中,pjc的取值固定为(0,1)。
算法流程:
I. 随机对初始pjc赋值,实现分布初始化。
II. 固定pjc值,这样待求解的方程组将化简为仅包含C个变量wc的线性方程组。通过最小二乘法求得此分布情况下的最优解。
III. 固定wc值,对N个词汇的pjc分布按贪心算法进行逐词搜索,寻找能够让训练集作文按式(5)评分的方差最小的pjc分布。
IV. 计算训练集作文按式(5)评分方差减小量ε,如果ε小于某一预设值或者达到一定迭代次数K,则进入步骤V;否则回到步骤II。
V. 按当前求得的pjc和wc值求得作文评分方程。按此方程得到作文的评分。
此方法中由于wc的类别数C值较小,因此在用最小二乘计算的时候计算复杂度也在可操作之内。同时,求得的pjc和wc并非全局最优的,避免了过拟合现象的发生。具体的循环次数K以及变量个数C值如何确定将在后面的实验参数设置中讨论。
3.2 改进的估计方法二
此方法试图将词汇直接分为c类,将词汇在每一类人工评分中的分布概率通过训练集计算出来,并以此作为特征对词汇进行聚类。同一类的词汇将获得同样的类别评分wc。在确定了词汇的类别分布pjc和类别评分wc后,也即确定了式(5)中的待估变量,实现了作文自动评分的方程。
此方法试图通过聚类的方法,直接求得词汇的评分类别所属。方法考虑了词汇在人工评分等级中的分布情况,一定程度上减少了数据带来的过拟合情况。但同时,引入了一个要判断的变量,即聚类的数目。具体的聚类数目C的确定将在后面的实验参数设置中讨论。
算法流程:
I. 人工的作文评分有11类,计算每一个词汇j在此11类上的分布情况。
II. 用聚类方法对N个词汇在这11类上的分布情况进行聚类,得到每一个词汇分为某一类的判别。也即得到pjc分布。
III. 在已知pjc分布后,待求解的方程组将化简为仅包含C个变量wc的线性方程组。通过最小二乘法求得最优解。
IV. 按当前求得的pjc和wc值求得作文评分方程。按此方程得到作文的评分。
3.3 改进的估计方法三
训练集的作文有11等级人工评分,因此假设词汇的等级也分为11类。在训练集上计算词汇每一类的分布概率。词汇中出现频率低的词,并不具有良好的统计意义,因此可以作为噪声剔除;同样,人工评分分数段分布较为均匀的词汇,其对于作文评分起不到区分意义,这样的词汇也应剔除。这样就可以得到有效(被剔除的词汇不再参与计算当中)词汇的概率分布,再通过最小二乘法得到当前分布下的最优wc值,也即确定了式(5)中待估变量,完成了作文自动评分方程。
算法流程:
I. 人工的作文评分有11类,计算每一个词汇j在此11类上的分布情况,即求得pjc。
II. 计算每个词出现的频率(f)和每个词在11类上的分布方差(dv)。对于词汇频率低于特定频率F或者其分布方差小于某一特定值DV的词汇,删除其对作文分数的影响。即对于符合情况的词汇j有:pjc=0对于任意的c∈C。
III. 在确定了pjc后,待求解的方程组将化简为仅包含C个变量wc的线性方程组。通过最小二乘法求得最优解。
IV. 按当前求得的pjc和wc值求得作文评分方程。按此方程得到作文的评分。
此方法将人工评分等级等价于词汇等级。将词汇属于词汇评分等级的情况,用概率分布的方式描述,而不再是上面方法中的只属于某一评分等级。将统计特性不明显的词汇和分布较均匀没有区分作文评分意义的词汇去除,减少了噪声的引入。这里有两个需要得到的经验变量,一个是截断频率的取值,一个是分布方差的截断最小值。取值确定将在后面的参数设置中探讨。
总结起来,三种方法的基本思路一致,均是将式(1)变化为式(5),通过分别求得词汇的分布pjc和评分类别的评分值wc来解决以上提到的两个问题。其区别在于具体的实现方法上。方法一通过贪心算法求得词汇的划分,方法二则是通过对词汇的分布特征进行聚类来得到词汇的类别划分,方法三则是直接利用了词汇在人工评分中的分布结果。相比于直接去求每一个词的评分wj,求一个类别的评分值wc能够明显地减少模型的参数,从而避免了过拟合现象的发生。
4 实验设计与分析
4.1 语料库介绍
本文中的作文数据的人工作文分数评分设定为1~6分,间隔为1分。每一篇作文由至少两个评分员进行评分。最终的人工作文评分分值为两评分员均分,分值区间1~6分,间隔为0.5分一档,共分为11档。

表1 训练集与测试集人工相关度
本文实验的数据取自一作文集。此作文集中,最初的两个人工评分的相关度约为0.54。考虑到作文评分中人工评分较低的相关度,为避免人工评分的不可靠性对实验带来的影响,本文的实验对象均选自两个人工评分中分差不大于1分的作文。本文共抽取8 000篇作文作为实验对象,其中5 000篇作为训练集,3 000篇作为测试集,测试集分为3份,每份1 000篇。每个数据集中两位老师人工评分相关度数据如表1所示。在此四个数据集上的人工评分分布见图1(数据集选自两个人工评分中分差不大于1分的作文,其中测试集按原始分布抽取获得;训练集则为剩余作文,因此训练集在.5分数段比例较少)。实验中,对于三份测试集分别做参数分析,通过参数的一致性分析获得最优的参数选择。

图1 数据集上人工评分分布
4.2 实验参数的影响以及选定
4.2.1 改进算法一中的迭代次数以及词汇评分等级数
对于改进方法一中,过大的迭代次数将导致评分公式出现过拟合,导致方程的泛化能力下降。因此,如何决定迭代次数,将是本小节所要解决的问题。图2所示,在一次迭代后,就出现过拟合现象。因此迭代次数选1次。由于迭代次数较少,这样也极大地减少了运算消耗的时间。
在确定了迭代次数后,由图3可见,词汇评分种类数在此方法下对评分效果的影响有限而且并无显著规律,因此按人工对作文的评分分为11级评分,而选取词汇评分种类数C=11。
4.2.2 改进方法二中聚类类别数
在方法二中的聚类方法选用K-means方法。对于此聚类方法,聚类数目是一个预先需要确认的变量。为了获得合适的K值,本文在三个测试集上对不同K值下的测试集相关度进行统计。
图4可见,当聚类数目较小的时候,在测试集乃至训练集上的评分相关度较低,且极为不稳定,说明此时的类别数不足以反映实际的情况;当聚类数目达到30以后,测试集上的评分相关度逐步趋于稳定。因此选取聚类数目K值为30。也即此情况下,词汇评分等级数C为30。

图2 迭代次数对测试集相关度的影响曲线(方法一)

图3 词汇评分种类数对测试集相关度的影响曲线(方法一)
4.2.3 改进方法三中词汇过滤条件
在方法三中,需要去掉统计特性不明显以及没有区分意义的词汇,以减少这部分词汇带来的噪声影响。实验采用网格搜索的方法对可能的参数进行逐一尝试,通过性能最优来决定参数。本文通过大致的参数尝试的方法初步得到截断频率的tf取值和截断分布方差tdv的初步值。随后,本文将log(tf)的取值定在-10~-3之间,而log(tdv)的取值在-7~-3之间。网格搜索的步长设为1。
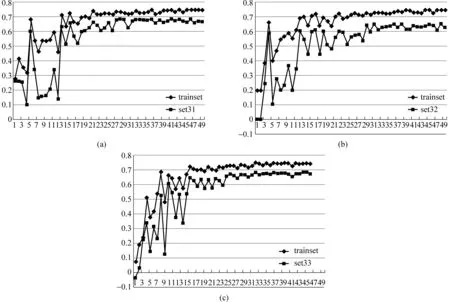
图4 词汇评分种类数对测试集相关度的影响曲线(方法二)
由图5可见,三个集上的最大评分相关度约为0.68。其中,log(tf)取值高于-4时,相关度急剧下降;取值低于-4时,相关度非常平缓的下降。log(tdv)的取值对相关度影响较低,约在-6附近达到一个极值。本实验选取tf的最优取值为0.015 625(2-6),tdv的最优取值为0.062 5(2-4)。
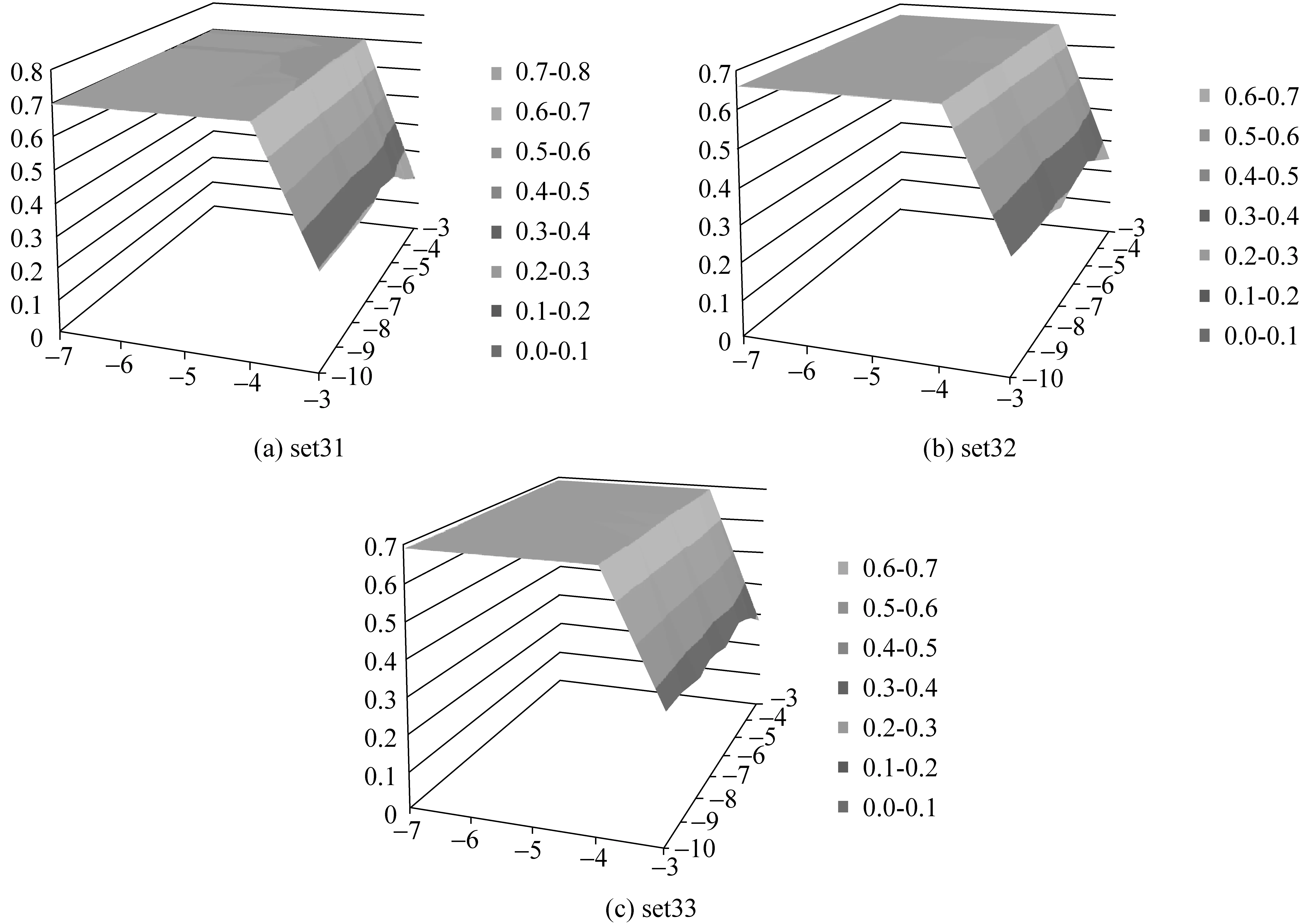
图5 词汇过滤参数对测试集相关度的影响曲线(方法三)
4.3 实验结果与分析
本文将对各个基于词汇评分的作文自动评分方法进行对比。其结果见表2。
各方法的性能如表2所见。从图6中可以直观地看到通用词表方法的相关度极低,这表明一个广泛通用的词表等级对于作文评分并没有代表性的意义。而常规的估计方法,由于其估计的粗略性,因此准确度并不高,影响了其最终的评分效果。本文将E-rater提出的两种方法作为改进方法的性能对比对象。可以看到,在本实验中的数据集上,E-rater_1方法性能较好,自动评分与人工评分相关度达到了0.6左右;相对而言,E-rater_2方法性能则不够理想,分析其原因,应该是由于各个分数段作文并非完全是高分段作文的部分缩影,而可能具有每个分数段内自身的词汇分布特色。因此仅用与高分段作文的相似度来衡量,显得有些不足。从图6中可以看到,本文所提出的三种改进方法在性能上均较平衡,平均相关度达到了0.65以上的水平,已经超过了E-rater方法的相关度。因此,本文提出的对于式(1)的假设是成立的。由于三种改进方法在本质上是一样的,差别在于具体的实现方法,因此它们在性能上也较为接近。考虑到各种方法在实现上的差别,本文试图将各个方法进行线性融合,以期望获得基于词汇等级评分方法的一个综合性结果。

表2 各方法下测试集自动评分与人工评分相关度

图6 各方法下三个测试集上的相关度
将以上方法结果中,性能较优的E-rater_1方法和三种改进方法进行线性融合。在三个测试集中抽取1~2个作为拟合方法的训练集,剩余的一个作为测试集。实验结果如表3所示。
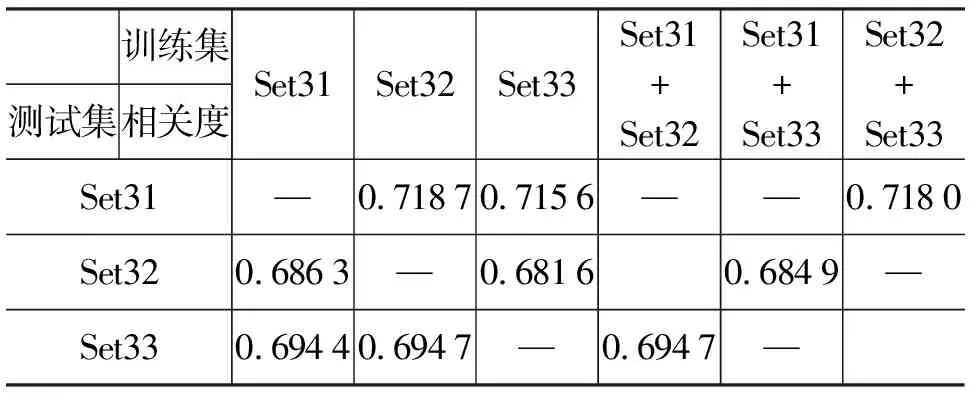
表3 基于词汇评分等级的作文评分性能
从表3中可以看到,融合后的结果与单一的方法比较均有一定的提升,在测试集上的相关度均值达到了0.698 8,而此三个测试集上的人工评分相关度均值为0.754 4(本实验中数据集是经过人工挑选的初始两人工评分不大于1分的作文,实际人工评分相关度约为0.54)。虽然自动评分的相关度低于人工评分相关度,但已经超过了实际全部数据的人工评分相关度。分析其原因是由于实际全部数据的人工评分中,多个评分员存在的个人差异以及人工评分疲劳的存在导致了数据中存在大量的人工噪声(不准确的作文评分),影响了人工评分相关度;而基于词汇评分的方法,在大数据量的情况下能够从带噪数据中学习到正确的词汇评分,一定程度上通过数据数量的优势弥补了噪声数据带来的影响,因此可以在最终结果上获得比实际人工评分相关度更高的结果。另一方面,本文仅仅考虑在词汇评分等级上对作文进行评分,并没有考虑其他许多能够表现作文水平的特征,能够取得如此接近人工评分相关度的性能已经表明本文提出的方法具有可行性。如果进一步融合其他作文评分的方法与特征,作文自动评分的性能还将进一步提高,但这已经超出了本文所讨论的范围。
5 总结与将来的工作
本文从词汇评分和作文评分之间的关系入手,通过建立合理的关系假设,从方法上讨论了如何通过词汇的评分得到作文的评分,并通过实验验证了假设的正确性,实现了基于词汇评分的作文评分。实验结果表明,如何通过相关的训练数据获得准确的词汇评分是进行基于词汇评分的作文评分的关键。基于词汇评分的作文评分在相关度性能上高于E-rater的同样基于词汇的方法,并且在融合了各种方法之后,最终的评分相关度可以接近0.7,说明了方法的有效性。
词汇仅是体现作文水平的一个重要特征。虽然基于词汇评分的作文自动评分方法在性能上已经达到较好的程度,但是相对于作文自动评分研究而言还仅仅是冰山一角。将来,可以继续从作文的语言、条理、内容三方面进行探索,从更加丰富而综合的层面进行作文自动评分的研究。
[1] S. Dikli. An overview of automated scoring of essays[J]. Journal of Technology, Learning, and Assessment, 2006, 5(1): 1-35.
[2] 李亚男. 汉语作为第二语言测试的作文自动评分研究[D]. 北京: 北京语言大学, 2006.
[3] T. Landauer, D. Laham, P. Foltz. Automatic essay assessment[J]. Assessment in Education: Principles, Policy and Practice, 2003, 10(3): 295-309.
[4] 曹亦薇, 杨晨. 使用潜在语义分析的汉语作文自动评分研究[J]. 考试研究, 2007, 3 (1): 63-71.
[5] Y. Attali, J. Burstein. Automated essay scoring with e-rater v.2[J]. Journal of Technology, Learning, and Assessment, 2006, 4(3): 1-30.
[6] T. Ishioka, M. Kameda. Automated Japanese essay scoring system based on articles written by experts[C]//Proceedings of ACL. Sydney, Australia, 2006: 233-240.
[7] 彭恒利. 中国少数民族汉语水平等级考试[J]. 中国考试, 2005, 10:57-59.
猜你喜欢
军事文摘(2022年8期)2022-11-03 14:22:01
小学科学(学生版)(2021年3期)2021-04-13 08:26:18
哈哈画报(2021年11期)2021-02-28 07:28:45
中华胰腺病杂志(2021年1期)2021-02-26 11:28:36
山东医药(2020年34期)2020-12-09 01:22:24
中华胰腺病杂志(2019年4期)2019-08-29 08:52:20
电子测试(2017年15期)2017-12-18 07:19:27
中华老年口腔医学杂志(2016年1期)2017-01-15 14:24:42
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
