
高速3780 点FFT处理器的设计与实现
2012-06-25 03:31解春云刘光辉牛俊峰
电视技术 2012年5期
解春云,刘光辉,牛俊峰
(电子科技大学电子工程学院,四川 成都 610054)
地面数字电视广播经过多年的发展,取得了很多成果,目前已经提出的地面数字电视广播标准有:欧洲的DVB-T、美国的ATSC和日本的ISDB-T。在此背景下,2006年8月国家标准化管理委员会颁布了中国数字电视地面广播传输系统标准 GB20600—2006[1],即中国的DTMB。DTMB系统包括单载波和多载波两种模式,其中,多载波传输模式采用时域同步正交频分复用(TDSOFDM)作为核心技术。在DTMB接收机中,为实现TDSOFDM技术,需要进行多次快速傅里叶变换(FFT),FFT处理器占据了大量的运算时间及资源,在很大程度上决定了DTMB接收机的功耗和复杂度,必须采用复用的方式来减少资源的占用。因此,寻求一种高速有效的3780 点FFT处理器,对整个DTMB接收机系统具有重要的现实意义。
1 3780点FFT算法
目前,关于FFT的计算,主要是基于基-2和基-4的算法,对于基-2和基-4的FFT,算法仿真和硬件实现都已有很多种成熟的算法。3780 点FFT不是以2或4为基,所以在实现时主要有两种方法[2]:
一种方法是把3780 点通过内插得到4096 点,利用现已成熟的基-2和基-4的FFT算法计算4096 点FFT,再抽取得到3780 点的FFT。
另一种方法是综合利用混合基算法、素因子算法(PFA)和Winograd傅里叶变换算法(WFTA)算法将3780 分解实现3780 点FFT的计算。
第一种方法没有计算准确的3780 点FFT,必然会带来计算误差,且采样速率发生改变,将增加OFDM系统中同步的复杂度,故不予考虑。本文重点对后者进行研究。下面先对混合基算法、素因子算法及WFTA算法进行介绍,并在此基础上,给出本文3780 点FFT的算法设计。
1.1 混合基算法
混合基算法[3]是一种将长点数的DFT转换为短点数DFT组合的算法。设有N点序列经x(n),其傅里叶变换(DFT)定义[3]为
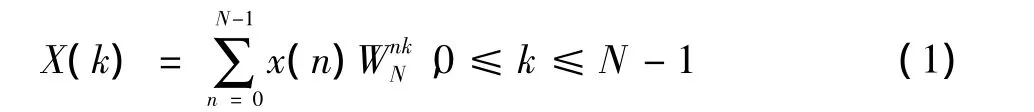
若N=N1×N2(N1,N2可有公因子),通过映射得到
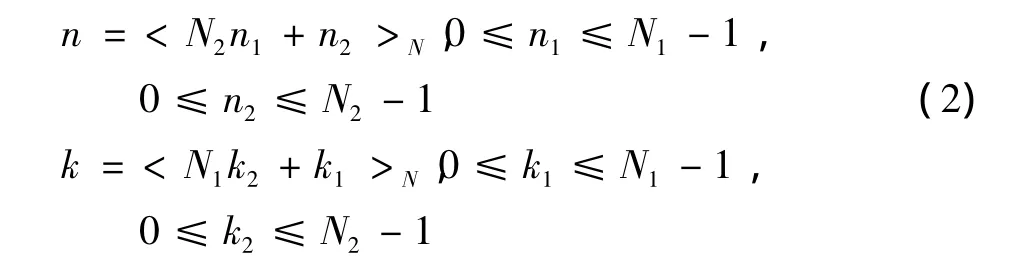
式中:<>N表示对N取模运算。将式(1)转化为

式中:将 x(n1,n2)和 X(k1,k2)看作二维数组,对 x(n1,n2)的行(列)作DFT得到X',再对X'的列(行)作DFT就得到X(k)。其中N1,N2可以继续利用上述特征进行二层分解以减少运算量。
1.2 素因子算法(PFA)
当混合基算法[3]中的 N1,N2互素时,可以通过选择n1,n2,k1,k2前的特殊系数消去旋转因子,进一步简化FFT的计算。通过映射得到

当 A,B,C,D 满足下列条件时
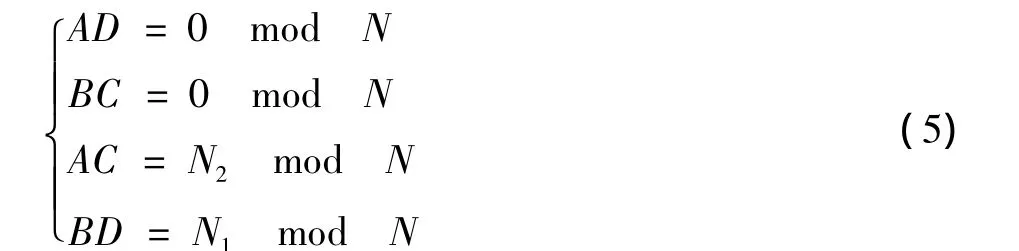
式(3)转化为
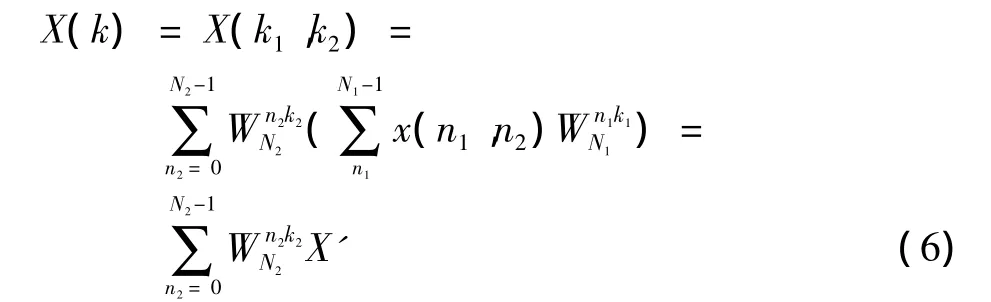
与混合基算法相比,素因子算法减少了中间的旋转因子,不仅减少了运算量,也减少了旋转因子的存储。其中N1,N2可以继续利用上述特征进行二层分解以减少运算量。
1.3 Winograd小点数DFT算法
Winograd小点数DFT算法[3]是一种高效的DFT算法,其特点在于乘法次数显著减少。
一个N点DFT可以写成矩阵的形式为

式中:WN是N×N的矩阵,第k行n列元素为WnkN,x=[x(0)…x(N -1)]T,X=[X(0)…X(N -1)]T。Winograd证明,当 N ∈ {2,3,4,5,7,8,9,16}时,复数矩阵 WN能以下列方式分解

式中:G为对角矩阵,且对角线上元素为实数或纯虚数;B,C为平凡矩阵,仅由0,-1,1或一些小点数构成。
1.4 3780点FFT算法
3780 可分解为3780 =7×5×3×3×3×2×2,在考虑到WFTA 算法提出的16,9,8,7,5,4,3,2 几种小点数 DFT 算法,且优先使用PFA的基础上,给出如图1所示的算法方案。

图1 本文算法方案分解图
将3780 点先通过素因子算法分解成27×140点,再对27点和140点分别采用混合基算法和素因子算法分解成9×3点和7 ×5×4点,其中9,3,7,5,4点FFT 利用WFTA 算法计算。与文献[4-7]中的3780 =60×63的混合基算法分解方案比较,该方案可节省3780 个旋转因子的存储。
2 3780点FFT处理器设计
DTMB系统采用TDS-OFDM技术,在长时延环境下,符号间干扰(ISI)会严重影响接收机性能。文献[8]提出了一种迭代门限检测(ITD)与判决反馈均衡(DFE)相结合的算法,该算法能够有效消除ISI干扰,获得精确的信道状态信息(CSI),同时复杂度也相对较低。然而迭代的检测CSI需要增加FFT/IFFT运算次数,FFT次数与迭代次数的关系为:NFFT=2+3×N迭代次数。采用1次迭代操作即要求5次FFT/IFFT运算,因此,FFT处理器在DTMB接收机中需消耗大量的运算时间及资源,必须寻求一种高速有效的3780 点FFT处理器,以复用的方式来减少逻辑资源的占用。
文献[4-7]均对DTMB系统中3780 点FFT处理器进行了详细介绍,其处理器内部WFTA运算单元均采用串行数据处理方式进行硬件设计,吞吐率只能满足1帧时间内的2次复用条件。为提高系统吞吐率,本文将对上述3780 点FFT处理器的实现结构进行改进,其内部WFTA单元改用并行处理方式,吞吐率提高为上述文献中处理器的4倍,实现了高速3780 点FFT处理器的设计目标。在硬件实现过程中,由于内部WFTA基本运算单元以不同并行度进行DFT运算,所以需要协调不同WFTA模块间的吞吐率。同时,为满足并行处理要求,存储模块需采用内存分组方式提高数据并行度。下面对该3780 点FFT处理器的设计进行详细描述。
2.1 3780 点FFT处理器结构
为了使3780 点FFT处理器在DTMB接收机系统中能充分复用,在第1.4节算法基础上,采用流水线结构进行3780 点FFT处理器的硬件设计,且为进一步提高系统吞吐率,其内部WFTA单元采用并行数据处理方式进行硬件实现。处理器结构如图2所示,其中1,9,7,4表示各单元的输入输出并行度。
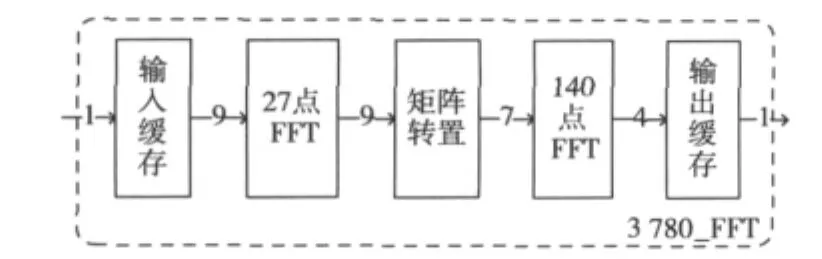
图2 3780 点FFT处理器框图
3780 点FFT处理器内部27点FFT和140点FFT运算分时交替进行,矩阵转置模块不需要采用双缓存结构,只需要存储3780 个中间变换结果。输入、输出缓存模块则分别采用两组双口RAM,以乒乓操作方式实现数据缓存及顺序调整。下面对图2中各单元的设计依次进行详细介绍。
2.2 输入缓存单元
由于27点FFT模块以9路输入并行度进行DFT运算,所以输入缓存单元需要完成数据缓存、顺序调整及9路数据并行输出功能。为保证流水线处理的高速进行,输入缓存单元采用两组存储器进行乒乓存储操作,每组存储器结构如图3所示。
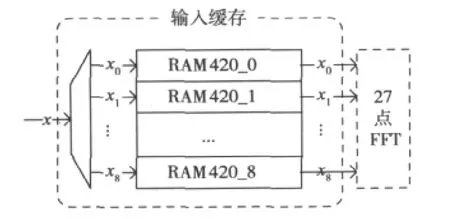
图3 输入缓存内部结构图
由1.2节可知,3780 =27×140时,一层分解采用PFA算法,相应的一层映射公式为

又27=9×3,二层分解采用混合计算法,相应的二层映射公式为

根据式(9)~(10),用Matlab对下标如何调整进行仿真,生成存储地址映射表,通过查表方式,将串行接收的数据存储到9个深度为420的存储器中,并可按地址累加的方式输出9路并行数据,送入27点FFT模块进行运算,以满足27点FFT模块的9点并行度处理要求。
2.3 27点FFT单元
27点FFT运算分9点FFT和3点FFT两级,由混合基算法实现9点FFT和3点FFT的级联,其实现结构如图4所示,其中9点和3点FFT采用第2.6节WFTA运算单元。

图4 27点FFT单元结构
图4中Cache1以乒乓操作方式完成混合基算法所需要的整序[2]。9点和3点WFTA单元分别以9路和3路输入并行度进行DFT运算,为解决不同基WFTA单元间吞吐率的协调问题,内部同时采用3个3点WFTA单元,使整个27点FFT单元以9路数据并行度进行DFT运算。
2.4 140点 FFT单元
140点FFT单元内部由素因子算法实现7点、5点和3点FFT的级联,其实现结构如图5所示,其中Cache2、Cache3以乒乓操作方式完成素因子算法所需要的整序[2],7点、5点和3点FFT采用第2.6节WFTA运算单元。

图5 140点FFT单元结构
7点、5点和4点WFTA单元分别以7路、5路和4路的输入并行度进行DFT运算,不同基WFTA单元间吞吐率的协调原则是,高并行度运算单元的处理速度同步于低并行度处理单元。以35=7×5为例,完成1次35点FFT运算,7点和5点WFTA单元各需5个和7个时钟周期,可通过控制信号,占用每7个时钟周期中的5个完成1次7点WFTA运算,使35点FFT的运算速度同步于5点WFTA单元。同理,140点FFT运算速度同步于4点WFTA单元。
2.5 输出缓存单元
该模块完成3780 点FFT结果存储及整序输出功能。为了匹配140点FFT单元的4路数据并行输出要求,内部采用4个深度为945的双口RAM,以地址累加的方式对输入数据进行缓存。为保证流水线处理的高速进行,输出缓存单元采用两组存储器进行乒乓存储操作,每组存储器结构如图6所示。
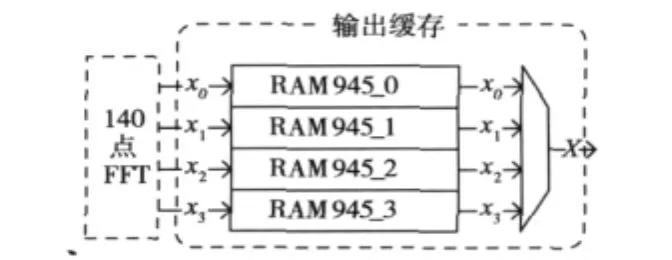
图6 输出缓存内部结构图
由1.2节可知,3780 =27×140时,一层分解采用PFA算法,相应的一层映射公式为

又140=35×4,二层分解采用混合计算法,相应的二层映射公式为

根据式(11)~(12),用Matlab对下标如何调整进行仿真,生成存储地址映射表,通过查表方式,将缓存数据以串行方式输出,实现3780 点FFT输出整序功能。
2.6 WFTA算法FFT单元
为了提高吞吐率,WFTA运算单元采用并行数据处理方式进行硬件实现。3,4,5,7,9点WFTA模块结构相似,以3点为例说明其实现过程。
N=3时,WFTA计算公式为

X=Wx,对 W 分解得 X=CGBx,C,G,B 分别为
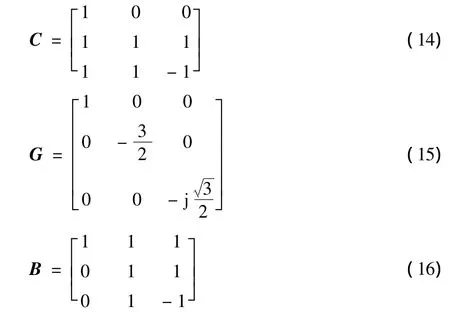
3点WFTA信号流如图7所示。
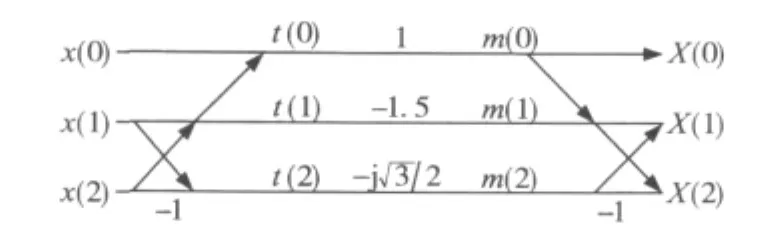
图73 点WFTA信号流图
其硬件结构如图8所示。
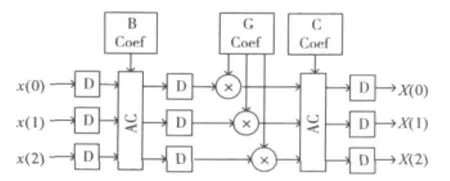
图8 WFTA硬件结构图
其中,D为寄存器,AC为累加器,B,G,C为矩阵系数产生器。
3 综合及分析
编写Verilog程序[9],输入复随机数据,采用Modelsim进行功能仿真,用 ISE软件并选用 Xilinx Virtex-5 XC5VLX330t芯片来进行综合。将1000 次仿真输出数据导入Matlab分析,当输入为10 bit数据,输出为18 bit数据时,系统信噪比可达69 dB,满足TDS_OFDM系统对信噪比的要求。在对信噪比有更高要求的应用场合,可以在WFTA运算模块后加入块浮点模块来提高处理精度。
文献[4-7]及本文处理器完成一次3780 点FFT运算所需时钟数Nclk如表1所示。其中,若3780 点FFT分1,2,…,n 级计算,且各级并行度为 vi(i=1,2,…,n),则有


表1 1次3780 点FFT运算所需时钟数比较
从表1可以看出,本文3780 点FFT处理器的吞吐率是文献[4-7]中处理器吞吐率的4.5倍。但是与文献[5]中处理器相比,该处理器所占逻辑资源是其1.5倍,即该设计的3780 点FFT处理器,是用高1.5倍的逻辑资源换取4.5倍的高吞吐率。
4 结束语
综合利用混合基算法、素因子算法及WFTA算法实现3780 点FFT运算,满足了系统的高计算精度要求;为提高系统吞吐率,在采用流水线结构进行硬件实现的基础上,其内部小点数WFTA单元采用并行数据处理方式进行硬件实现,使系统吞吐率提高为串行处理方式时的4.5倍。
[1]GB 20600—2006,数字电视地面广播传输系统帧结构、信道编码和调制[S].2006.
[2]杨旭霞,归琳,余松煜.3780点FFT处理器的研究[J].电视技术,2005,29(11):32-34.
[3]崔振,王永贺,门爱东.DMB-T系统中FFT模块的设计与实现[J].电视技术,2008,32(S1):6-7.
[4]YANG Zhixing,HU Yupeng,PAN Changyong,et al.Design of a 3780-point IFFT processor for TDS-OFDM[J].IEEE Trans.Broadcasting,2002,48(1):57-61.
[5]余飞.DTMB系统中3780点FFT处理器的算法设计及FPGA实现[D].武汉:武汉理工大学,2008.
[6]上海明波通信技术有限公司.3780点快速傅里叶变换处理器及运算控制方法:中国,200810043761.X[P].2010-03-10.
[7]复旦大学.流水线结构的3780点快速傅里叶变换处理器:中国,200710044716.1[P].2008-03-05.
[8]LIU Guanghui.ITD-DFE based channel estimation and equalization in TDS-OFDM receivers[J].IEEE Trans.Consumer Electronics,2007,53(2):304-309.
[9]夏宇闻.Verilog数字系统设计教程[M].北京:北京航空航天大学出版社,2003.
猜你喜欢
现代装饰(2022年5期)2022-10-13
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
数学小灵通(1-2年级)(2020年6期)2020-06-24
数学小灵通(1-2年级)(2020年4期)2020-06-24
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
电子设计工程(2015年12期)2015-02-27
中国卫生(2014年12期)2014-11-12
汽车零部件(2014年1期)2014-09-21
电子设计应用(2004年7期)2004-09-02
