
高速无损压缩的FPGA实现方法研究
2012-06-07 04:15尹维汉孟令军
电视技术 2012年21期
尹维汉,孟令军,龚 敬,严 帅
(中北大学电子测试技术国家重点实验室仪器科学与动态测试教育部重点实验室,太原 山西 030051)
当今社会,信息技术发展飞快,快速、高效的存储与传输信息变得尤为重要,从而使得数据压缩技术在工程上具有了很大的需求背景。数据压缩分为无损压缩和有损压缩,无损压缩指的是压缩还原后的数据与压缩前的数据完全相同,而有损压缩压缩还原后的数据与压缩前的数据相比存在一定的偏差。无损压缩主要应用于对数据要求很高,不允许数据失真的场合,如文本数据、程序和特殊应用场合的图像数据(指纹图像、医学图像等)的压缩。有损压缩广泛应用于语音、图像和视频数据的压缩[1-3]。本文主要研究了一种基于LZW算法的无损压缩FPGA实现方法[4-5],利用该方法设计的数据压缩系统压缩速度高达66.67 ~246.15 Mbit/s。
1 高速无损压缩方法的过程描述
LZW无损压缩算法的实现通常采用计算机软件的方法[6],而软件方法一般存在着压缩速度慢、占用资源多等缺点,而采用硬件实现的LZW无损压缩可以很好地克服这些缺点,并能够实现对数据流的实时、高效及自适应压缩。本文主要研究了一种无损压缩的FPGA实现方法,该方法基于LZW算法的改进算法。改进后的LZW算法使用分级字典体系[7],以充分利用FPGA的并行处理[8]能力来实现高速无损压缩。这种分级字典体系由字宽度不同的多个并行字典组成,不同字典间的字宽度连续递增,每个字典的地址空间为分级字典体系地址空间中的一段。修改后的算法实现过程描述如下:
假设分级字典体系中字典个数为n,字典DICT0字宽度为1个字符,字典DICT(n-1)字宽度为n个字符,其中n=2,3,…;数据缓存区长度为n个字符;字典DICT0的地址空间为0 ~ADDR0,ADDR0=256;字典DICT1的地址空间为ADDR0~ADDR1;字典DICT(n-1)的地址空间为ADDR(n-2)~ADDR(n-1);则分级字典体系的地址空间为0~ADDR(n-1)。
1.1 压缩过程描述
压缩过程步骤:
1)字典(字符串表)初始化,i=0。
2)如果有数据流输入,从输入数据流中读取1个字符填写到数据缓存区C(i)中,i加1;如已没有数据流输入,缓存区中字符数为j(j<n),执行步骤4)中的(2)。
3)如果缓存区中字符数为n,执行步骤4)中的(1);如果缓存区中字符数小于n,执行步骤2)。
4)(1)将数据缓存区中n个字符所组成字符串{C0 C1 C2…C(n-1)}、{C0 C1 C2…C(n-2)}…{C0 C1}同时与字典DICT(n-1)、DICT(n-2)…DICT1中已经存储的字符串进行比较即查字典。
①如果在字典DICT(n-1)中查找到对应的字符串,则将该字符串对应的匹配地址(索引号)DICT_MATCHAED_ADDR(n-1)输出到压缩数据流中。数据缓存区清空,i=0,执行步骤2)。
②如果在字典DICT(n-1)…DICT(n-m)(m=1,2,3,…,n-1)中没有查找到对应的字符串,而在字典DICT(n-m-1)中查找到对应的字符串,则将该字符串对应的匹配地址DICT_MATCHAED_ADDR(n-m-1)输出到编码数据流中。同时将字符串{C0…C(n-m)}写入到字典DICT(n-m)的写入地址DICT_ADDR(n-m)处,字典DICT(n-m)写入地址DICT_ADDR(n-m)加1。数据缓存区中C0=C(n-m)、C1=C(n-m+1)…C(m -2)=C(n-2)、C(m -1)=C(n-1),i=m,执行步骤2)。
(2)如果j=0,压缩结束;如果j≠0(j<n),将数据缓存区中j个字符所组成字符串{C0 C1 C2…C(j-1)}、{C0 C1 C2…C(j-2)}…{C0 C1}同时与字典 DICT(j-1)、DICT(j-2)…DICT1中已经存储的字符串进行比较即查字典。
①如果在字典DICT(j-1)中查找到对应的字符串,则将该字符串对应的匹配地址DICT_MATCHAED_ADDR(n-1)输出到编码数据流中,j=0,压缩结束。
②如果在字典 DICT(j-1)…DICT(j- m)(m=1,2,3,…,j-1)中没有查找到对应的字符串,而在字典DICT(j-m-1)中查找到字符串,则将该字符串对应的匹配地址DICT_MATCHAED_ADDR(j-m-1)输出到编码数据流中。同时将字符串{C0…C(j-m)}写入到字典DICT(j-m)的写入地址DICT_ADDR(j-m)处,字典DICT(jm)写入地址DICT_ADDR(j-m)加1。数据缓存区中C0=C(j-m)、C1=C(j-m+1)…C(m -2)=C(j-2)、C(m -1)=C(j-1),j=m。
③如果j>1,执行步骤4)中(2);如果 j=1,将字符C0对应于DICT0的匹配地址输出到编码数据流中,压缩结束。
1.2 解压缩过程描述
解压缩过程步骤:
1)字典初始化。
2)从编码数据中读取一个编码值到OLD_CODE。
3)将字典DICT(n-1)或字典DICT(n-2)…DICT0中对应于地址OLD_CODE处所存储的字符或者字符串{OLDC0…OLDC(i-1)}(i=1,2,3,…,n)输出。
4)如果还有编码数据输入,读入一编码值到NEW_CODE;如果已没有编码数据输入,解压结束。
5)(1)如果NEW_CODE的值小于字典写入地址DICT_ADDR0的值,得DICT0中对应于字典地址NEW_CODE的字符C0。
如果NEW_CODE的值大于字典地址ADDR(j-1)的值,且小于字典写入地址DICT_ADDR(j)的值,其中0<j<n,得DICT(j)中对应于字典地址NEW_CODE的字符串{C0…C(j)}。
将字符串{OLDC0…OLDC(i-1)}和字符C0或字符串{C0…C(j)}中第1个字符 C 0组成新字符串{OLDC0…OLDC(i-1)C0}。如果 i< n,将字符串{OLDC0…OLDC(i-1)C0}添加到字典DICT(i)写入地址DICT_ADDR(i)处,字典 DICT(i)写入地址DICT_ADDR(i)加1;如果i=n,不处理。
(2)如果NEW_CODE不满足步骤5)(1)中的条件,将字符或字符串{OLDC0…OLDC(i-1)}加上该字符串中第1个字符OLDC0组成新字符串{OLDC0…OLDC(i-1)OLDC0}(i<n),将字符串{OLDC0…OLDC(i-1)OLDC0}添加到字典DICT(i)写入地址DICT_ADDR(i)处,字典DICT(i)写入地址DICT_ADDR(i)加1,这样字典地址NEW_CODE对应的字符串为{OLDC0…OLDC(i-1)OLDC0}。
6)将NEW_CODE的值赋给OLD_CODE,执行步骤3)。
1.3 压缩及解压缩实例
以上对算法进行了详细描述,为了更好地表达算法的实现过程,以下给出了一个压缩及解压缩实例。在该实例中,输入为字符数据流“/WED/WE/WEE/WEB/WE”,分级字典体系中字典个数为4,字典 DICT0,DICT1,DICT2,DICT3 的字宽度分别为1,2,3,4 个字符,字典地址分别为0~255,256~511,512~767,768~1023。表1给出了压缩实现的过程,表2给出了压缩过程中所使用的分级字典体系结构。
解压缩过程中使用的分级字典体系与压缩时完全相同。表3给出了解压缩的实现过程,字典重构如表2所示。
2 硬件实现的体系结构
采用上文所描述的算法,笔者设计了基于FPGA的高速无损压缩系统,原理如图1所示。

表1 压缩过程描述
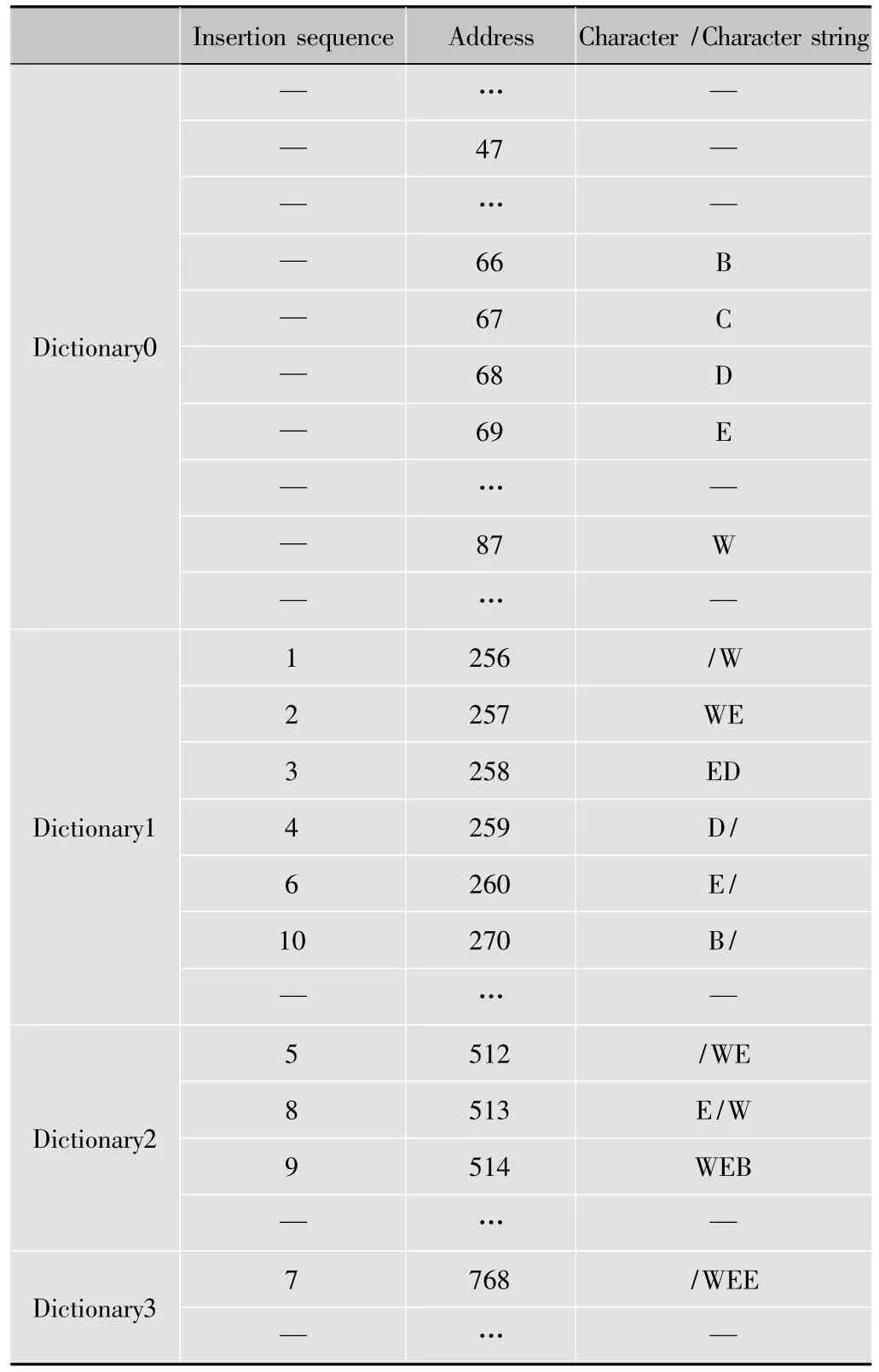
表2 分级字典体系结构
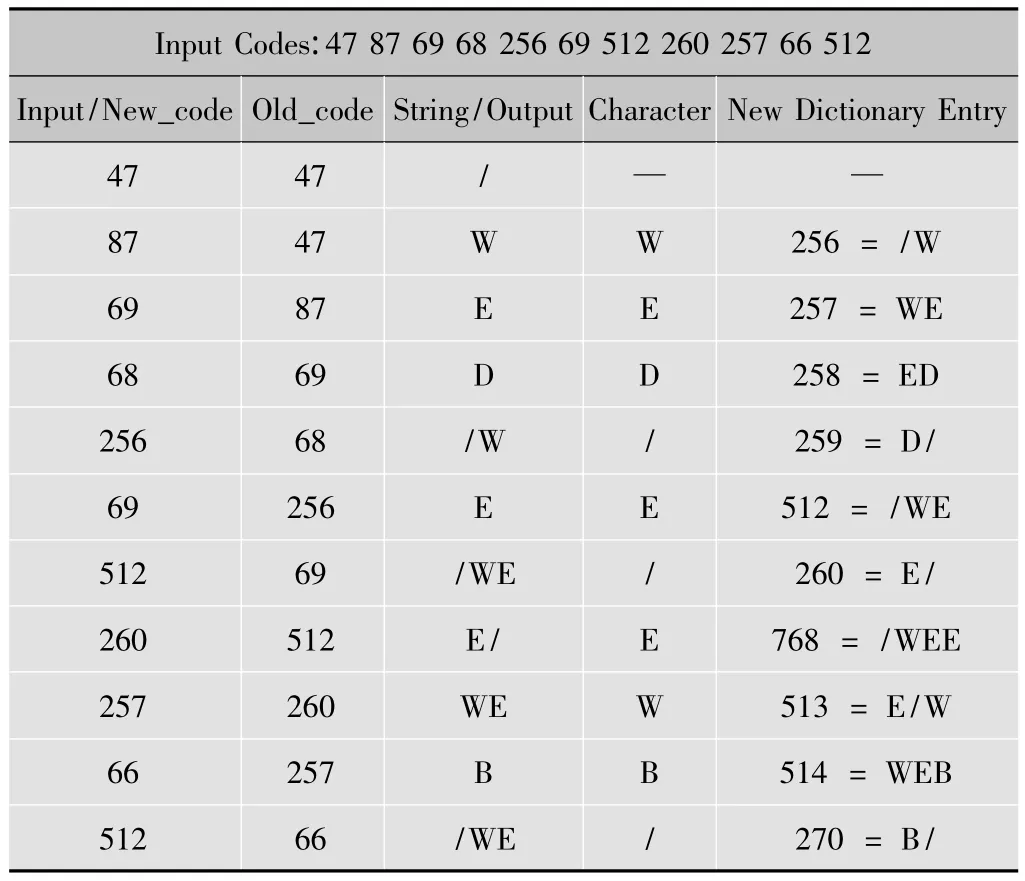
表3 解压缩过程描述

图1 硬件系统原理框图
该系统主要由算法控制模块、分级字典、数据输入FiFo及数据缓存区等组成,系统时钟为50 MHz。其中算法控制器为整个系统的核心部分,协调控制系统其余各个模块共同完成算法的计算流程。分级字典是系统的关键组成部分,用于存储无损压缩过程中产生的中间数据。数据缓存区完成对输入字符数据流8字符缓存,从而实现并行查找字典的功能。FiFo模块用于协调输入数据流与无损压缩之间的速度差。系统中字典更新采用先进先出策略,即一个字典填写满后将从该字典低地址处开始覆盖写人,而不清除字典高地址处已写入内容;分级字典由8个字典组成,其中字典0字宽为1个字符,由256个字符组成,占用地址空间为0~256,不需要在硬件中实际构建,其余7 个字典字宽分别为2,3,4,5,6,7,8 个字符,占用的地址空间长度分别为 256,128,128,64,64,64,64,在硬件系统中需要实际构建。
图2为作者在FPGA上设计的高速无损压缩系统在测试时获取的一张SignalTap波形图,其中clk为系统时钟输入管脚,reset为系统复位输入管脚,wrreq,wrclk,data[7..0]分别为数据流输入请求信号、输入数据同步时钟、输入数据流管脚,dataend为压缩结束信号输入管脚;wrfull为 FiFo 满信号输出管脚,encodedata[0..9],codeclk分别为编码数据流输出、编码数据流同步时钟管脚。

图2 SignalTap波形图(截图)
对系统的实际测试表明,当系统时钟为50 MHz时,压缩速度可达8 bit× 8=246.15 Mbit/s,平均压缩比约为55%。
3 结语
本文首先阐明了硬件实现基于LZW算法的高速无损压缩基本原理,分别对压缩过程与解压缩过程进行了详细描述,并给出了压缩与解压缩实例。根据这些基本原理在FPGA上设计了高速无损压缩系统并进行了实际测试。测试结果表明,系统压缩速度快,压缩比高,达到了预期设计目标。
利用该高速无损压缩FPGA实现方法所设计的无损压缩系统,可极大地提高数据压缩速度,减少数据的存储空间。同时,在数据传输领域,该系统能够将高速信号转换为缓变信号进行传输,从而降低通信的信道占用费用,提高数据传输的可靠性。
[1]李锦明,张文栋,毛海央,等.实时无损数据压缩算法硬件实现的研究[J].哈尔滨工业大学学报,2006,38(2):315-317.
[2]王伟,刘文怡,秦丽,等.遥测数据实时压缩技术的设计与实现[J].仪器仪表学报,2006,27(6):2467-2469.
[3]王文延,赵中华,朱磊.一种JPEG无损压缩专利算法的改进与实现[J].电视技术,2010,34(5):26-29.
[4]AKIL M,PERROTON L,GRANDPIERRE T.FPGA-based architecture for hardware compression/decompression of wide format images[J].Journal of Real-Time Image Processing,2006,1(2):163-170.
[5]古海云,李丽,许居衍,等.一种Virtex系列FPGA配置数据无损压缩算法[J].计算机研究与发展,2006,43(5):940-945.
[6]AGNEW G B,SIVANANDAN A.A fast method for determining the origins of documents based on LZW compression[J].International Journal on Digital Libraries,2000,3(4):297-301.
[7]LIN M B.A hardware architecture for the lzw compression and decompression algorithms based on parallel dictionaries[J].The Journal of VLSI Signal Processing,2000,26(3):369-381.
[8]应骏,李莉.MPEG-4解码的并行处理优化[J].电视技术,2007,31(8):29-31.
猜你喜欢
汽车维修与保养(2020年10期)2021-01-22
无线互联科技(2020年11期)2020-12-01
汽车维修与保养(2020年11期)2020-06-09
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
读者(2016年14期)2016-06-29
西北工业大学学报(2015年3期)2015-12-14
中国卫生(2014年7期)2014-11-10
燕山大学学报(2014年1期)2014-03-11
通信学报(2014年12期)2014-01-01
