
中小型网站基于分布式数据库的渐进优化策略
2012-04-29 00:44:03马一宁张霞陈静汝
电脑知识与技术 2012年12期
关键词:多线程
马一宁 张霞 陈静汝
摘要:用户量的不断增加,使传统的集中式数据库已难以满足网站用户者的需求,采取分布式数据库Client/Server模式的协作式处理,可以提高了数据传输速率,从而提高了整个网站的传输效率。同时,根据分布式数据库物理分散性的特点,在Server端上运用多线程技术,采取多处理器并行处理,进一步提高网站效率。最后一步,采取合适的查询优化策略,降低查询代价,选择最优方式缩减查询时间,优化网站性能。
关键词:分布式数据库(DDBS);Client/Server;并行;查询优化;多线程
中图分类号:TP393文献标识码:A文章编号:1009-3044(2012)12-2665-02
数据库存储容量的增加,应用范围的急剧扩大,使得数据库查询、计算时间大幅度增加,用户等待时间加长,难以满足网站用户者的需求。分布式数据库将数据库系统和计算机网络系统有机地相结合,有效地避免了集中式数据库的局限性,充分发挥数据库技术和网络技术的优势。分布式数据库系统的研究开始与20世纪70年代,80年代进入成长阶段,随着信息的爆炸式增长,其研究越来越深入,国际上每年都召开专门会议对分布式数据库做出分析及预测。其中,DDBS可采用Client/Server模式,将应用程序服务器和数据库服务器分离,提高并行执行的效率。
1分布式数据库概述

分布式数据库系统是在物理上分散而逻辑上集中的数据库系统,具有物理分布性、逻辑整体性、站点自治性等特点。除此之外,分布是数据库不同于集中性数据库,具有数据分布透明性、集中与自治相结合的控制机制。由于具有物理上分散的特点,适当增加数据冗余性,以此来提高系统的可靠性是其独有的特点。另外因为计算机网络的飞速发展,数据传输速率加快,传输费用降低,形成了一种新的计算环境——Client/Server体系。Client/Server体系兴起于90年代,到现在已经成为了信息处理的计算机主流模式。
2基于分布式数据库的渐进优化
2.1采取Client/Server模式
分布式数据库Client/Server模式的协作式处理是一种特殊的分布式处理,它把整个系统分成Client和Server两大主要部分,通过网络相连接,协同工作,共同完成客户请求,如图1所示。Client主要用于应用程序的处理,面向最终用户,从分布式数据库系统中访问数据,负责完成大部分的应用性功能。Server又称数据库处理器,主要用于数据管理,进行数据计算更新等操作,完成DBMS的核心操作。Server端集中处理数据,不进行应用程序的操作,大大加快了数据处理的速度。Client端只是通过简单的命令(SQL查询、更新语句)传送,提高了网络传输速率,从而提高了整个系统的传输效率。
2.2采取多处理器并行处理方式
分布式数据库的数据库处理器(即Server端)需要进行大批量数据的更新、计算工作,通过利用数据库的多处理器并行操作机制,可以有效提高数据库的效率。针对这一性能,做了如下实验,这里使用windows 2003和sql server 2000作为平台,将全校学生的评课记录作为实验对象,利用sql server2000内部支持多cpu并行工作的机制,在win2003的环境下,处理117152个学生的评课记录,对每位同学的评课结果计算。可得以下结果:使用单cpu时用时0:28:40,双cpu时用时0:27:55,四cpu时用时0:25:48。从上述数据可得,sql server2000内部的对多cpu分配任务的平衡机制可以对大量的数据计算进行少量优化,但是优化的效果不明显。所以,当对大量数据进行计算时,对查询、计算、插入等多种操作进行分片处理,合理调度多线程,更能发挥多处理器的优势,提高处理器的执行效率。针对本次试验得出结论,在Server端上,我们可以运用多线程技术,加快运算效率,优化网站性能。调度如图2所示。
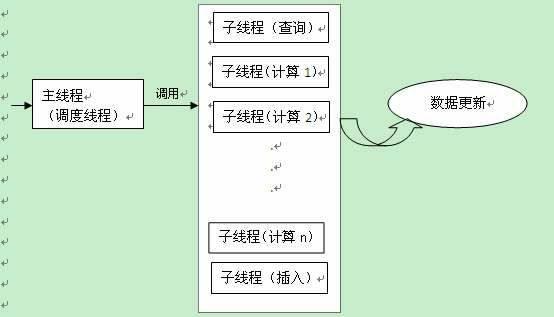
图2
2.3选择数据查询优化方式
在分布式数据系统中,由于Client和Server端不在同一服务器上,需要通过网络连接,因此进行查询优化的准则就是尽可能地降低通信费用、减少响应时间,就是以最小的代价最短的时间获得所需要的数据。因此根据网络模型,首先提出具体的查询处理模型,如图3所示。局部查询一般只涉及到本地或者说是单个站点的数据,所以查询的优化技术与集中式数据库没有太大差别。对于远程查询,也是只涉及单个站点的数据,所以与局部优化策略相同。因此,采取合适的全局优化策略,可以在最大程度上对数据查询进行优化。文献[2]中提到了多种数据查询优化算法,基于关系代数等价变换的查询优化处理、基于半连接算法的查询优化处理、基于直接连接算法的查询优化处理、Hash划分算法等。根据网站的特征以及操作的不同种类,选取合适的查询优化策略。查询命令经过优化处理之后,在本地的数据库服务器上按类似于集中式数据库的方式进行查询。经过全局查询的优化,整个系统的响应时间明显缩短,提高了系统的整体效率。

图3
3分布式数据库的局限性
分布式数据库采用Client/Server模式,根据服务的观点对功能进行了明确划分,但是如果把应用的主要功能转移到Server上,则又会出现像传统集中式数据库的瓶颈问题,用户数的不断增长,会导致速率的降低。同时,由于Client和Server的物理上的分散性,导致数据安全性降低,所以需要采取更加强大加密和解密技术用以保证数据传送的安全。此外,分布式数据库进行并行计算、采用多线程技术,的确很大幅度上加快了运算的效率,在一定程度上满足了客户的需求,解决了用户量过多的问题。但同时也加大了数据访问的冲突,如何采用更有效的封锁机制也成为了一个值得研究的课题。
4结束语
随着网络技术的迅速发展,用户量不断增加,如何更高效地利用便捷的网络技术和数据库本身固有的特性,发挥分布式数据库的最大优势,已成为当今的一个热点研究,受到人们越来越多的关注。分布式数据库的高效性能必然会更好地应用于中小型网站,同时在进一步的研究后,也会得到更多的利用,应用于越来越广泛的领域。
参考文献:
[1] Ceris S,Navathe B,Wiederhold G. Districution Design of Logical Database Schemas[J]. IEEE Transactions on Software Engineering,1983,9(4).
[2] Epstein R,Stonebraker M R. Analysis of Distributed Database Processing Strategies[J].Proceeding of VLDB,1980.
[3]李华,赵建平.分布式数据库数据查询的优化处理方法[J].长春理工大学学报,2005,25.
[4]昌月楼,杨利.分布式数据库技术的现状和发展方向[J] .计算机工程与科学,1995 (3) .
[5]周龙骧.分布式数据库实现技术[M].北京:科学出版社, 1998.
[6]邵佩英.分布式数据库系统及其应用[M].北京:科学出版社,2000.
猜你喜欢
吉林省教育学院学报(2016年8期)2016-12-26 21:51:22
电脑知识与技术(2016年21期)2016-10-18 21:47:47
电脑知识与技术(2016年17期)2016-07-23 18:56:09
电脑知识与技术(2016年16期)2016-07-22 21:21:08
电脑知识与技术(2016年9期)2016-05-18 14:21:48
能源研究与信息(2015年2期)2016-01-13 01:07:56
