
基于字符特征的文本验证码破解
2012-04-23 10:13:14高原
电子科技 2012年6期
高 原
(江苏省邳州市机动车综合性能检测站,江苏邳州 221300)
字符识别技术[1-2]是破解验证码过程中的一项关键技术,而基于特征的字符识别技术相比其他识别技术具有识别速度快的优势,在验证码识别过程中,速度越快,其价值越高。基于特征的字符识别技术,可通过字符的结构特征,来定义可行的区分方法,这种识别方法可根据字符的特征定义不同的算法。在验证码识别过程中,由于验证码是被人识别的,为提高验证码的可用性,验证字符大多使用那些特征明显,不容出现混淆的字符,所以验证码中所用的字符是有限制的,字符集较小,利用结构特征的字符识别技术,特征更加容易辨别,识别速率也更快。
验证码[3-4]作为一种在网页上使用的安全机制,可防止恶意程序自行的注册账号、发送免费邮件、论坛灌水,有效防止黑客对某一特定注册用户使用特定程序暴力破解方式进行不断的登陆尝试。验证码是现在众多网站通行的方式如某银行的网上个人银行、百度社区等是一种简单的区分人与机器的方法。对验证码进行破解研究,发现其设计过程中的漏洞和弱点,对提高验证码的安全性具有重要意义。2004年Dontnod公司的Hocevar S[5]在网络上发布了其验证码识别程序PWNtcha(Pretend We’re Not a Turing Computer but a Human Antagonist),以证明验证码不是一种安全的交互验证手段,现在这个项目已经开源。Hocevar同时还在网站上发布了多个验证码的识别结果,识别率从49% ~100%,其中有著名的电子支付公司Paypal的验证码。PWNtcha针对的验证码主要是背景容易分离和非粘连的验证码,网站也给出了一些难以识别的验证码样本,但未能给出识别结果。2003年 Mori G和Malik J利用形状上下文对Gimpy和EZ—Gimpy验证码进行了识别,识别率分别达到33% ~92%[6]。2008年英国纽卡斯尔大学的Yah J,AHMAD A S E等对Microsoft的验证码进行了成功分割,并通过多分类器进行识别,识别率达到 60%[7-8]。
文中针对某银行的验证码,首先根据其特点将验证码中的干扰色去掉并且提取出目的字符,然后基于字符与数字内部和外部特征,采用颜色填充法,三线条法,全面扫描法对单个字符进行识别,识别率可达到95%以上。相比于模板匹配算法,在时间上也有大的缩减。最坏情况,识别的字符的时间是215 ms,平均识别时间为187 ms。
1 验证码机制
网络中常用的验证码是基于文本图像的验证码,基于文本图像的验证码又可分为字符分离和采用粘连机制两大类。文中所述的破解方法都是针对字符分离的验证码。

图1 某银行验证码
某银行的验证码在字符分离验证码中具有代表性。由于无法得知其验证码生成的原理和代码,于是先从其网上银行中随机获取100个验证码,通过对这100个样本验证码的观察和分析,发现其验证码具有以下特点。
(1)背景色以浅灰色为主,有大量随机的某种色彩线条随机分布在整个验证码中,且彩色线条和前景色的字符重叠时像素值是前景色和背景色叠加而成的。
(2)字符均有不同程度的扭曲和变形,字符的扭曲和变形使得商用的一般OCR软件对字符无法正确识别。
(3)字符位置固定在水平方向上和竖直方向上是随机分布的,因为验证码输入是有顺序限制的,所以在水平方向字符之间是不可交错的,而竖直方向上的随机分布影响了字符破解时对字符的准确定位。
(4)每个验证码都是由固定数目字母或数字构成的,固定的字符数使破解工作相对容易,在分割字符时可以确切的了解需要提取几个字符,而验证码中都采用了6个字符。
(5)每种验证码采用的字符集是相同的,不是所有的字符都会出现在验证码中,因为会降低验证码的可用性。例如,在有背景色干扰的情况下,肉眼较难分清1和I。验证码中共有19个数字和字母出现,8个数字,11个小写字母。
文中以某银行验证码为例,介绍了破解此类字符分离验证码的详细过程。
2 破解过程
破解验证码分为两个步骤,分割和识别。利用前节分析验证码得到的特点,可利用一种简单有效的方法破解验证码。
破解过程可以概括为下面的步骤:
(1)对验证码进行预处理,去除背景色和干扰色。
(2)用颜色填充算法提取验证码中的字符。
(3)根据每种字符特征对单个字符识别。
破解工作是建立在100个样本验证码基础上的,为确保研究的正确性和适用性,对另外100个在破解工作中未能用到的验证码进行了实验。
2.1 预处理
该阶段主要目的是去除验证码中背景色,将字符像素全部置为黑色,其他背景颜色全部置为白色,也可称为二值化处理。
验证码中字符的颜色是灰色与噪音颜色叠加的色彩,而灰色与噪音颜色叠加的色彩与灰色极为相似,只将原本灰色的RGB值进行了微调。所以,本节的目的是将验证码中灰色的像素与灰色相近的像素置为黑色,其他颜色置为白色。
通过大量的实验和观察,发现RGB值中至少有一个分量值>170的像素必定是背景色和噪音色,以170为阈值对图片进行处理,当一个像素点的RGB值分量中有一个>170就将其置为白色,相反则置为黑色。部分结果如图2所示。
用这一方法对100个验证码进行二值化,效果表明这种方法对验证码有较好的去噪点效果。图像的二值化,对于这种不粘连的验证码,本身就是分割的过程。

图2 二值化后的验证码
2.2 提取字符
在这一阶段,可用连通域法提取图片中的字符。连通域法就是将一个连通域里的所有像素提取出来当作一个字符。具体实现使用了颜色填充算法。这里,用一个宽40,高为字符高度的图像存储提取出来的字符。
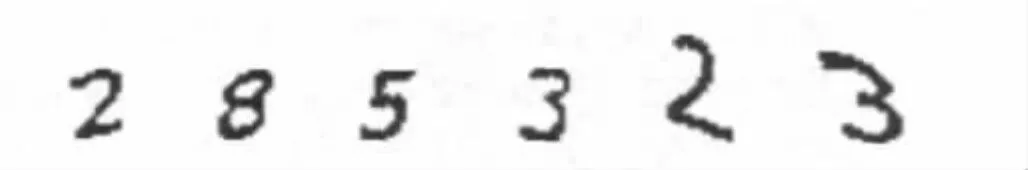
图3 被提取的6个字符
2.3 字符识别
常用的识别方法是模板匹配,在模板集合中依次用模板图片和提取出来的字符进行匹配,选取匹配率最高的字符作为识别结果。模板匹配对扭曲的字符有较大的局限性,字符是随机扭曲的,若要得到理想的结果,就需要一个较大的模板库,但模板库的庞大必然使匹配所用的时间更长。
文中所用的识别方法是基于字符特征的,对单个字符识别的准确率达97%,对100个样本验证码的识别成功率达到82%。
在整个识别过程中,采用了3种方法:颜色填充、三线条和全面扫描法,确保识别结果在准确率和速度上都取得理想的效果。
2.3.1 基于颜色填充的字符识别
在验证码中出现的19个字符中,有9个字符有封闭的区域,这里称为闭环。如图4所示。通过判断各自闭环的位置,可以结合使用颜色填充算法来识别这些字符。

图4 含有闭环的字符
如4的闭环位置相对在中间,闭环的形状为三角形。6的闭环位置在图片的下部。b与6相似,闭环位置在图片的下部,闭环上方无黑色像素。9的闭环位置在图片的上部。a的闭环位置在图片的下部,与d类似,不同点在于a的闭环上方有黑色像素。d与a相似,闭环位置在图片的下部,闭环上方无黑色像素。e的闭环位置在图片的上部,与p类似,不同点是闭环的下方有黑色像素。p与e相似,闭环位置在图片的上部,闭环下方无黑色像素。

图5 颜色填充
根据以上特征,4,6,9,a,b,d,e,p 这 8 个字符被成功地识别。加上已经识别出的8,验证码中出现的19个字符中的9个已经被区分出来,经过实验证明,这种方法的识别正确率在98%以上。
2.3.2 基于三线条法识别字符
三线条法,是针对验证码中字符识别提出的新方法,分别在图片的1/3高度,1/2高度和2/3高度处扫描,记录遇到的黑色像素位置,通过这些黑色像素的位置识别字符。该方法针对的是验证码中的字符m,字符n和字符w。相比于整体扫描得到全部特征的方法,三线条法只通过局部扫描得到局部特征就可识别相应的字符,在速度上具有较大优势,而准确率依然理想。
在经过颜色填充识别字符后,验证码中还有10个字符未被成功识别,分别是 2,3,5,7,k,m,n,s,w,x。在这10个字符中,应用三线条法,m,n,w的特征被明显的体现出来,详细描述如下。
m三个线条上的黑色像素都呈三段分布,中间段的黑色像素与两边段黑色像素中间的非黑色像素数目接近并>3,三个线条上的像素都符合这一特点。
n三个线条上的黑色像素都呈两段分布,两段黑色像素之间的非黑色像素的数目>3,三个线条上的像素都符合这一特点。
w在1/3高度的线条上,黑色像素呈三段分布且中间段黑色像素与两边段黑色像素之间的非黑色像素数目>3,在1/2高度的线条上则呈现三段分布,但是黑色像素之间的非黑色像素的数目<1/3高度上的线条,而在2/3高度上的线条,黑色像素可能呈两段或三段分布,呈两段分布时可被确认为w,呈三段分布只要黑色像素中间的非黑色像素的数目远<1/3高度和1/2高度的线条也可被确认为w。

图6 三线条法
对100个验证码样本中出现的字符m,n和w进行了实验,其识别正确率达到97%。在算法执行时,如果某种字符已经被识别,在后面识别剩余字符时就不去识别该种字符,颜色填充法和三线条法对字符识别的高准确率,保证了算法可行性。
经过颜色填充法和三线条法的处理之后,验证码中的19个字符被识别出来12个,还有7个字符未被识别出来,分别是 2,3,5,7,k,s,x。对于这几个字符,三线条法可以识别出部分,但准确率不高且不能完全识别,因此采用后面的全面扫描观察其特征的方法识别这7个字符。
2.3.3 基于全面扫描识别字符
全面扫描是从上往下,对字符的每一行像素进行扫描,通过每行像素点的分布,行与行之间像素点移动的趋势,判断其是否属于某个特定字符的特征。该方法基本可以识别剩下的7个字符。
比如字符7,扫描图像下半部分的每一行,如果每行的黑色像素都<4,且只有一段连续的黑色像素,符合这一条件的像素被认为是字符7。其他的6个字符也有各自的全局特征,可以通过类似的方法予以识别。

图7 剩下的7个字符
经过全面扫描方法处理之后,验证码中的19个字符已被全部成功识别。对100个样本验证码中的600个字符进行实验,全面扫描方法对这7个字符的识别成功率达97%。
3 实验结果
对作为样本的100个验证码的实验结果进行分析,并且用文中的算法对另外的100个验证码进行了测试,主要测试了破解成功率和破解时间,并对破解失败的原因作出进一步分析和讨论。另外,用同样的方法对同类验证码进行破解,结果证明文中的方法具有一般性。
3.1 成功率
验证码的破解主要分为分割和识别两个阶段,在100个样本中,算法的分割成功率是94%。这表明,在这100个验证码中,有94个验证码的字符都能被提取出来。对另外100个验证码用同样的算法进行了实验,这100个验证码从未在研究过程中用到,算法的分割成功率为96%,这充分说明算法在预处理和提取这一阶段具有较好的通用性。对100个样本验证码的最后识别成功率为83%,对另外100个未在研究过程中使用的验证码识别成功率为78%,与样本验证码的成功率相比略有降低,但结果仍较为理想。
3.2 速度
对作为样本的100个某银行验证码破解,破解一个验证码的平均速度只有187 ms,破解最快的是170 ms,破解最慢的为215 ms。以平均速度计算,一秒钟可以破解5个验证码,破解成功率为78%,则每秒钟可正确识别4个验证码,远快于人类输入验证码的时间。
以平均时间计算,一秒钟破解4个验证码,一分钟就是240个,一天24小时总共可以破解345600个验证码,如果使用多个机器同时灌水或者发送免费邮件,将会消耗极大的网站资源,会对其他用户正常使用造成影响。
3.3 对同类验证码的破解效果
用文中的算法对多个字符分离的验证码进行破解实验,破解对象分别为中国农业银行和交通银行的验证码,如图8所示。破解结果如表1所示,结果表明,文中的方法对于识别同类验证码具有较好的通用性。都采用基于字符特征的识别方法时,验证码采用的字符集越大,识别时间越长,并且呈线性增长,某农业银行的字符集只有9个数字,所以识别速度较快,而某交通银行的字符集有27个,则识别速度相对较慢。

图8 某农业银行和某交通银行的验证码

表1 对同类验证码的破解结果
3.4 改进建议
文中对字符分离验证码的破解工作及结果表明此类验证码在设计过程中存在极大的缺点和漏洞,针对文中的破解方法,可在诸多方面做出改进使这种破解方法无效。
采用与前景色相似甚至相同的颜色作为噪点,在预处理阶段的算法会失去作用,尤其当噪点与字符相交时,这些噪点在字符提取阶段会与字符同时被提取,将会严重的干扰到字符的识别,尤其对于算法所用的基于字符特征的识别方法,对字符的完整性要求较高,笔画的缺失和多余都将影响到算法的成功率。
使用粘连机制,字符与字符相连,简单连通域算法是无法将单个字符提取出的,这样在分割字符时增加了难度,Yahoo和Google的验证码均采用粘连机制,现在还未出现有效的方法破解采用该机制的验证码。使用连机制时,若字符长度不定,将会取得更为理想的防机器识别能力。
4 结束语
文中分析了字符分离验证码的普遍特点,针对这些特点提出了破解方法,并在识别时介绍了一种基于字符特征破解验证码的方法,通过进行实验得出该方法具有较高准确率和较快速度的特点,最终提出了对此类验证码的改进方法。
[1] MOIL S,SUEN C Y,YAMAMOTO K.Historical review of OCR research and development[J].Proceedings of IEEE,1992,80(7):1029 -1058.
[2] SIMARD P,STEINKRAUS D,PLATT J.Best practice for convolutional neural networks applied to visual document analysis[C].Los Alamitos:International Conference on Document Analysis and Recognition(ICDAR),IEEE Computer Society,2003:958 -962.
[3] AHN L,BLUM M,HOPPER N J,et al.The CAPTCHA web page[EB/OL].(2011 -03 -26)[2012 -03 -19]www.captcha.net.
[4] AHN L B,HOPPER M N.CAPTCHA:Using hard AI problems for security[J].Lecture Notes in Computer Sconce,2003,26(9):294 -311.
[5] HOCEVAR S.PWNtcha[EB/OL].(2010 -09 -08)[2012-02 -26]http://caca.Zoy.org.
[6] GREG M,JITENDRA M.Recognising objects in adversarial clutter:breaking a visual CAPTCHA[C].IEEE Conference on Computer Vision and Pattern Recognition(CVPR'03),2003,1:134 -141.
[7] HELLAPILLA K,LARSON K,SIMARD P,et a1.Computers beat humans at single character recognition in readingbased human interaction proofs[C].Stanford University,CA,USA:In Proceedings of the second Conference on Email and Anti-Spam,2005.
[8] YAN J,AHMAD A S E.A low - cost attack on a microsoft CAPTCHA[C].New York,USA:Proceedings of the ACM Conference Off Computer and Communications Security,ACM Press,2008:543 -554.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
电脑迷(2014年8期)2014-04-29 07:37:40
河南科技(2014年3期)2014-02-27 14:05:36
