
基于人工智能技术的教育资源搜索引擎研究*
2012-03-31 03:06杨娜王岩
吉林建筑大学学报 2012年3期
杨 娜 王 岩
(1:吉林建筑工程学院计算机科学与工程学院,长春 130118;2:吉林建筑工程学院学生工作处,长春 130118)
1 研究背景
近年来,随着互联网的普及和快速发展,信息资源与站点越来越多,而且信息的组织方式也非常自由.当网上的信息越来越多,单纯地通过传统、手工的获取信息方式,达到快速而且准确地获取信息显然不太可能.现在,在互联网上人们用来查询信息的工具是搜索引擎.据统计,搜索引擎是排在电子邮件之后的第2个人们用的最多的网络工具[1].但随着网络信息增长的速度越来越快,而且人们对知识的要求也更为精确,现在的搜索引擎已远远不能满足人们的需要,需要更为智能化、个性化的搜索引擎.如何快速、准确地从浩瀚的信息海洋中找到自己需要的信息,已成为互联网应用中一个极为重要的研究课题.目前,现有的搜索引擎存在的问题是:
(1)现有的搜索引擎仍存在着高覆盖率和低查全率的问题;
(2)用于表示Web信息的数据类型的多样性、数据格式的松散性,导致了这些信息之间的格式转换成为了挖掘中的一个瓶颈,从而阻碍了挖掘和搜索的速度,延长了响应时间[2];
(3)搜索引擎在用户接口设计方面和互动性方面存在的缺陷,使用户无法准确地定义检索条件,检索结果偏离用户的意图,降低了搜索结果的准确率.
(4)对搜索的结果无法按照用户的个性特征进行一定的排序,使用户需要用大量的时间在搜索的结果中寻找自己最想获取的信息[3].
2 提出一种新的人工智能搜索技术
2.1 人工智能搜索知识
为了有效描述搜索路径,这里引入了“路标”网页的概念.所谓“路标”网页,就是指该网页的存在对指导搜索路径目标网页起着积极的引导作用.接着,将会看到引入“路标”网页,对有效约束可能发生的搜索路径以及确认搜索路径的有效性都起到了很好的促进作用.如图1中,各菱形框代表与搜索过程密切相关的各基本网页,这些基本网页或其中部分信息可能包含在最终的信息搜索结果中,或标志着搜索过程的一个重要阶段,或它能够被较为容易地识别出来.
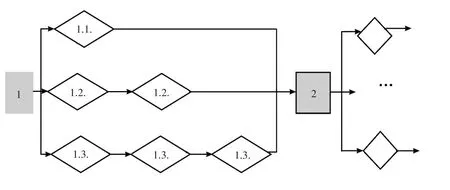
图1 多层知识表示方法的示意描述
例如,由于在大学计算机系教员信息网页搜索过程中,所获得的大学主页和计算机系教员信息网页搜索过程中,所获得的大学生主页和计算机系主页中的一部分信息内容,最后将与教员的有关信息结合在一起,作为最终的搜索结果反馈给用户.因此,在描述大学计算机系教员信息网页搜索知识时,大学主页和计算机系主页全部都将作为基本网页参与描述有关的搜索路径.
所示搜索知识的基本含义就是:从一个基本网页1搜索到下一个基本网页2时,中间最多可能存在3条基本搜索路径,这3条基本搜索路径分别是:
(1)通过基本网页1中的某个网链,就可直接(到达)获得基本网页2;
(2)经过基本网页1中的某个网链,以及一个中间网链(一个过渡网页中的某个网链),便可(到达)获得基本网页2;
(3)经过基本网页1中的某个网链,以及两个中间网链(分别经过两个过渡网页中的各自一个网链),方可(到达)获得基本网页2.
多层知识表示方法是通过两个层面来描述进行网页准确搜索所需的有关搜索知识.这两个层面分别是:与网站内部组织结构密切相关的搜索路径知识的相关描述,以及与网站内容(网页)密切相关的搜索基本单元(网页或网链)知识的相关描述.采用这种以搜索路径对象描述为搜索知识的表示主体,网页或网链对象(搜索基本单元)描述为搜索知识基本组成的多层知识表示方法,不仅能够帮助准确有效搜索出所需要的目标网页,而且也有助于实现搜索知识的自我完善.
2.2 示例说明
利用前面所介绍搜索知识表示方法,及其所表示的具体知识,采用深度优先的启发搜索策略,从事先指定的若干网站和教育资源数据库中,分别搜索出所需要的各目标网站的整个处理流程.此外,在搜索的过程中,还可根据已完成的搜索过程及结果,不断地进行完善目前所拥有的搜索知识,以便能够不断地提高自己的搜索能力.
我们用从B网页到C网页搜索的部分过程进行实验,
BC11:Faculty(2,2)
BC21:Faculty(2,2)+Title(2,2)+Staff(2,2)
BC22:Faculty(2,2)
搜索知识中基本网页共有两个B和C,前者无需再识别;后者则是利用标题内容中的两个特征就可加以识别.其中特征类型说明所使用的T和L分别表示该特征为网页的标题(title)内容和超级链接(anchor text)内容.在实际操作时,一般都是将以上所描述的人工智能搜索所需的搜索知识用3个知识对象,即搜索路径、基本网页和搜索路径基本单元(网链),结合在一起来加以描述.
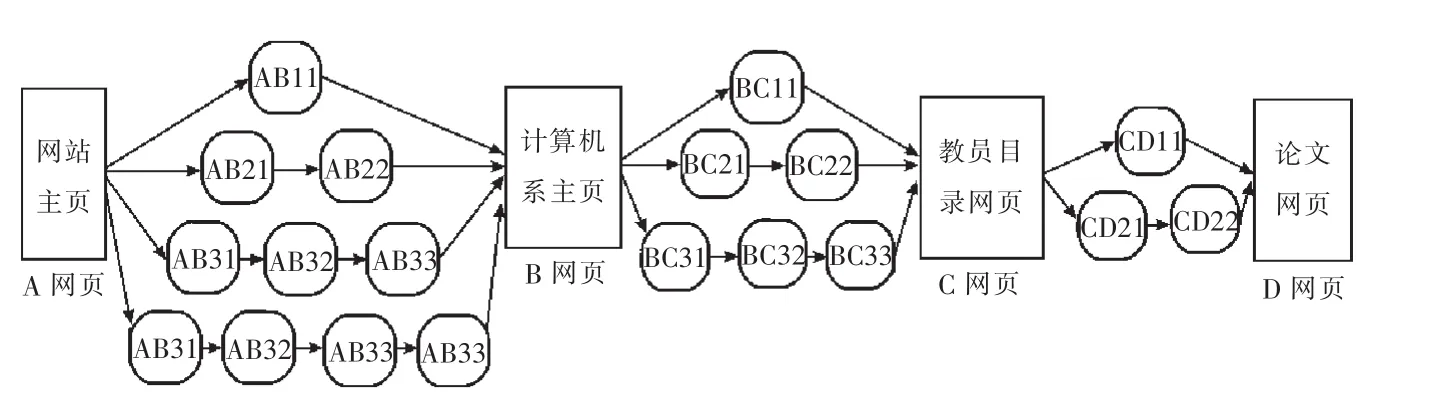
图2 某学校网站
3 基于人工智能搜索算法的教育资源搜索引擎设计
3.1 工作流程
①用户提出搜索请求;②据当前的搜索状态和搜索知识以及当前所获得的网页,推断下一步网址;③根据前一步分析结果决定是继续搜索数据库还是搜索已失败或成功;④在当前网站搜索结果结束;⑤不断重复上述4个步骤,直到事先给定的网站均被搜索完毕为止;⑥将搜索到的符合用户标准的结果返回给用户.
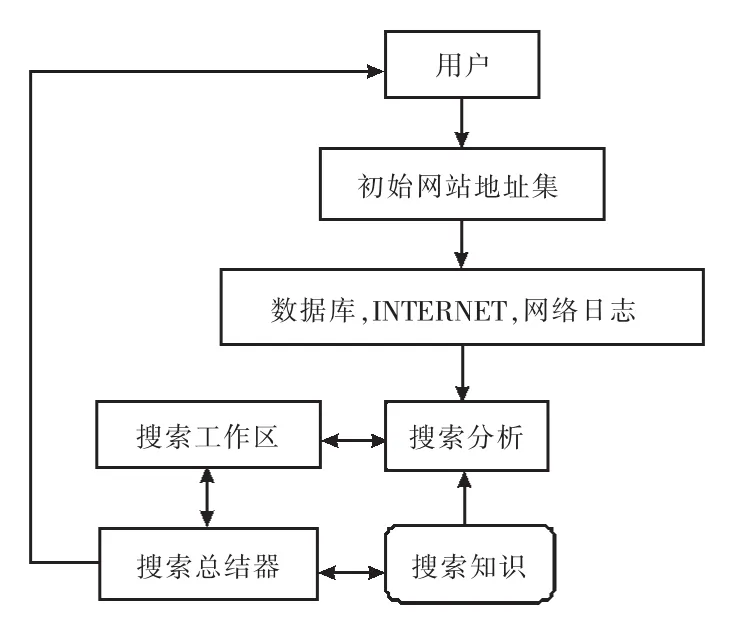
图3 基于智能搜索的教育资源搜索引擎结构
3.2 搜索步骤
人工智能搜索算法所采取的主要处理步骤如图3所示.
①用户提出搜索请求,根据给出的网址获取相应的主页;②在教育资源数据库,网络以及用户的网络日志中搜索,根据当前的搜索状态和搜索知识,以及当前所获得的网页,推断下一步搜索网址;③根据前一步分析结果,决定是继续搜索教育资源数据库,网络以及用户的网络日志,还是搜索已失败或成功;④在当前网站搜索结果结束(无论搜索失败或者成功),对本次搜索所经历的所有搜索路径进行分析总结,以完善自己的搜索知识;⑤不断重复上述4个处理步骤,直到事先给定的网站均被搜索完毕为止;⑥将搜索到的符合用户标准的结果返回给用户.
4 结语
在这个新的模型中,不仅能够对网站中网页进行深度优先的人工智能搜索,而且还能够通过对其搜索过程和结果的自我学习来获取更多更好的搜索知识.在新模型的设计过程中,使用了一种有效的搜索知识的新型表示方法,并且为了有效描述搜索路径,在搜索路径中引入了“路标”网页的概念.通过路标网页不仅可以搜索出存在的网页,而且对指导搜索路径确定目标网页起到了积极的引导作用.
[1]赵夷平.传统搜索引擎与语义搜索引擎服务比较研究[J].情报科学,2010,10(2):10-13.
[2]张培荣.元搜索引擎与独立搜索引擎比较研究[J].现代图书情报技术,2004(11):35-37.
[3]李观金.基于搜索引擎自然检索的搜索引擎优化[J].硅谷,2011,3(7):48-50.
猜你喜欢
长治学院学报(2019年2期)2019-07-24
电子制作(2018年10期)2018-08-04
中学生博览(2017年12期)2017-06-27
中学生博览·文艺憩(2017年6期)2017-06-19
电子制作(2017年2期)2017-05-17
电子测试(2015年18期)2016-01-14
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
计算机与网络(2014年7期)2014-03-25
技术经济与管理研究(2014年11期)2014-03-11
