
基于Hadoop的录波数据的存储与访问
2011-12-27 01:05:50白红伟马志伟朱永利白红浩
河北省科学院学报 2011年3期
白红伟,马志伟,朱永利,白红浩
(1.华北电力大学控制与计算机工程学院,河北保定 071003;2.华能沁北发电有限责任公司检修部,河南济源 459012;3.南华大学环境保护与安全工程学院,湖南衡阳 421001)
基于Hadoop的录波数据的存储与访问
白红伟1,马志伟2,朱永利1,白红浩3
(1.华北电力大学控制与计算机工程学院,河北保定 071003;2.华能沁北发电有限责任公司检修部,河南济源 459012;3.南华大学环境保护与安全工程学院,湖南衡阳 421001)
在智能电网环境下,录波数据具有广域、全景、海量和可靠的特征,传统的存储硬件采用磁盘阵列,数据库管理软件采用关系数据库系统的方法由于系统扩展性差、成本高、可靠性低,难以适应要求。本文提出了一种基于Hadoop的录波数据分布式存储与访问的新方法,并将其与传统方法的访问速度进行了对比,证明了新方法的高效性。
录波数据;Hadoop;数据存储;数据访问
故障录波器监视电网运行状况,根据录波数据能分析系统的故障参数、谐波含量、故障点定位和系统元件参数测量[1]。故障录波系统已经成为电网自动化控制和管理的必不可少的组成部分。
实现电网的信息化是智能电网的基本特征之一,即信息的高度集成、共享和利用。这就要求电网调度端可以随时收集分布于各个厂站的故障录波器的信息,建立故障信息处理系统总站,改变传统装置分散、各自独立、故障信息不能共享的缺陷。建立故障录波联网系统后,系统总站将从各分站接收大量故障报告,并做整理和分析。面对这些数据量大、可靠性和实时性要求高的录波数据,常规的数据存储方法会遇到极大的困难。
如何将录波数据快速存储成为本文研究的重点。Hadoop具有超大规模、高可靠性、高可扩展性、按需服务和极其廉价的特点,为上述问题的解决带来了机遇。
1 故障录波数据及其在Hadoop中的存储
1.1 Hadoop主要技术介绍
Hadoop是最知名的云计算开源系统[2],它模仿和实现了Google云计算的主要技术,可以在大量廉价的硬件设施组成的集群上运行应用程序,为应用程序提供了一组稳定可靠的接口,旨在构建一个具有高可靠性和良好扩展性的分布式系统。Hadoop的核心技术是HDFS、Map Reduce和HBase。
本研究数据存储系统HDFS[4]采用分布式存储的方式来存储数据,它是一个分布式文件系统,有着高容错性的特点。而且它提供高传输率来访问应用程序的数据,适合有着超大数据集(录波数据)的应用程序。
HBase[5]是一种构建在HDFS之上的分布式、面向列的存储系统,适合实时读写、随机访问超大数据集的应用。HBase通过线性方式从上到下增加节点来进行扩展,不是关系型数据库,也不支持SQL,但它巧妙地将大而稀疏的表放到廉价服务器上。它是一个稀疏的,长期存储的,多维度的,排序的映射表。这张表的索引是行关键字,列关键字和时间戳。每个值是一个不解释的字符数组,数据都是字符串,没类型。用户在表格中存储数据,每一行都有一个可排序的主键和任意多的列。由于是稀疏存储的,所以同一张表里面的每一行数据都可以有截然不同的列。列名字的格式是"<family>:<label>",都是由字符串组成,每一张表有一个family集合,这个集合是固定不变的,相当于表的结构,只能通过改变表结构来改变。但是label值相对于每一行来说都是可以改变的。
1.2 故障录波数据结构
微机故障录波器在电力系统的广泛应用,可以得到电网故障状态下丰富的暂态数据,但是由于在电网运行的这些装置来自不同的制造商,种类繁多、数据格式互不兼容。智能电网环境下,需要建立统一的故障录波分析平台,这样就可以利用故障线路的两侧录波数据,精确计算出故障点位置,建立统一的故障分析平台。因此本研究采用暂态数据交换通用格式,即COMTRADE数据格式,它能为故障录波器之间交换数据提供有效手段,便于不同型号故障录波器联网。
COMTRADE标准的数据文件有三种类型[3]:引导文件,以HDR作后缀;组态文件,以CFG作后缀;数据文件,以DAT作后缀。引导文件为用户提供一个附加信息的描述样本,以便更好地了解暂态记录条件。组态文件由计算机程序识别,有特定的格式。组态文件中记录的数据包括采样率、通道号及线路频率等内容。
以组态文件和数据文件为例,对COMTRADE标准进行解析。组态文件是ASCII文本文件,为数据文件提供必要的信息,以便解释相关数据文件中的数据值。文件被分为行,每一行以回车和换行为终止,逗号用以分隔一行内的内容。包含(1)站名,记录装置的特征,COMTRADE标准的修改年份。(2)通道的数量和类型。(3)通道名称、单位和转换系数。(4)线路频率。(5)采样速率和每一速率下的采样数量。(6)第1数据点的日期和时间。(7)触发点的日期和时间。(8)数据文件类型。(9)时间标记倍乘系数。配置文件实例:

数据文件包含被采样的暂态事件的数据值。数据必须完全符合配置文件定义的格式,即ASCII文本文件或Binary二进制文件。本文采用ASCII数据文件格式,在文件中,一个采样中每个通道的数据通过一个逗号与下一通道分开。序列采用回车/换行在一个采样的数据值与下一采样的采样数值分开,数据行的数量根据记录的长度而变化。每一行分为TT+2列,TT是记录中通道的总数,另外两个是时间标记和采样数量。每个数据采样记录应包含排列如下的整数:
n,timestamp,A1,A2,…,Ak,D1,D2,…,Dm<CR/LF>:其中,n为采样数,必须是整数;timestamp为时间标记,基本单位是μs。一个数据文件中以第1个数据采样至任意一个时间标记区所标志的采样所经过的时间是配置文件中的时间标记与时间乘数(timestamp*timemult)的乘积(单位为μs)。下面给出一个有6个模拟值和6个状态值的例子:
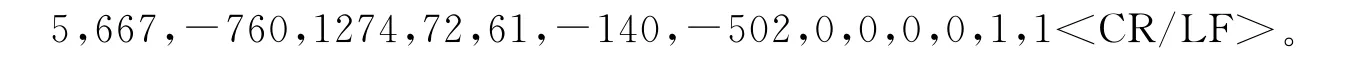
1.3 录波数据模型设计
根据HBase数据模型的特点,设计的录波数据模型如表1所示。将变电站的名称作为主键。表1共有3个列族:HDR列存储任何需要的信息。CFG列存储通道的数量和类型、通道名称、单位和转换系数、线路频率等信息。Data列存储被采样的暂态事件的数据值。该表设计为一张半结构化的表,一张表就已经能够满足系统大部分要求。对于一个Rowkey来说,只需要指定相关的列族名就可以获取相关数据的全部数据。

表1 录波数据模型
2 利用Map Reduce访问录波数据实验
在海量的智能电网录波数据中及时访问到需要的数据,以便进行故障诊断与预测是十分重要的,Hadoop平台通过Map Reduce方法实现数据访问和处理。Map Reduce[6]是一种并行编程模式,它的主要两个概念是Map(映射)和Reduce(化简)。Map函数是用来把一组键值对映射成一组新的键值对,用于子任务执行;而Reduce函数是用来保证所有映射的键值对中的每一个共享相同的键组,用于子任务处理结果的合并。
在Hadoop平台上实现数据访问时,借助广度优先的思想,进行基于层的扩展。设计思想如下:
(1)将用户访问请求交给Hadoop平台的名字节点,Job Tracker将访问任务分发给各个名字节点上的Map函数。
(2)Mapper进行Map操作(Initial Key,Intial Value)->[(Inter Key,Inter Value)]从Input key,value产生中间数据集。
(3)Reducer进行Reduce操作(Interkey,Inter Valueslterator)->[(Inter Key,Inter Value)],Reducer遍历所有节点取得需要的中间数据集,再对其进行去重、过滤等后期处理,得到结果。
(4)由Output Format类内含的Record Writer,将最终结果输出到所需程序。
下面给出Map、Reduce以及Run函数伪代码:

接下来交给Hadoop系统[7]运行。它的主要工作有:
(1)Job Tracker,创建一个Input Format的实例,调用它的getSplits0方法,把输入目录的文件拆分成FileSplist作为Mapper task的输入,生成Mapper task加入Queue。
(2)Mapper Task先从Input Format创建Record Reader,循环读入FileSplits的内容生成Key与Value,传给Mapper函数,处理完后中间结果写成SequenceFile;Reducer Task从运行Mapper的Task Tracker获取中间值执行Reducer函数,最后按照Output Format写入结果目录。
(3)Task Tracker每10s向Job Tracker报告一次运行情况,每完成一个Task,10s后,就会向Job-Tracker索求下一个Map/Reduce。
(4)将结果导出,存放到指定的数据库中,这些数据有一定的标准输出格式,经过一系列计算后方便在数据库中进行数据挖掘,为智能电网故障诊断提供方法。
3 实验结果分析
由一台单独的机器单机模拟HBase集群,由一台机器单机测试Oracle。由3台服务器组成的Hadoop集群组成分布式文件系统,均使用red-hat Linux操作系统,安装好Hadoop、HBASE以及JDK。其中一台部署HDFS的名字节点,另外两台部署HDFS的数据节点。
实验采用单层扩展方式,考察数据规模对Hadoop平台的性能。数据源分别为10万,50万,500万,2000万,5000万条记录,为了减少单次试验的偶然性,表2的实验结果是5次实验的平均值。
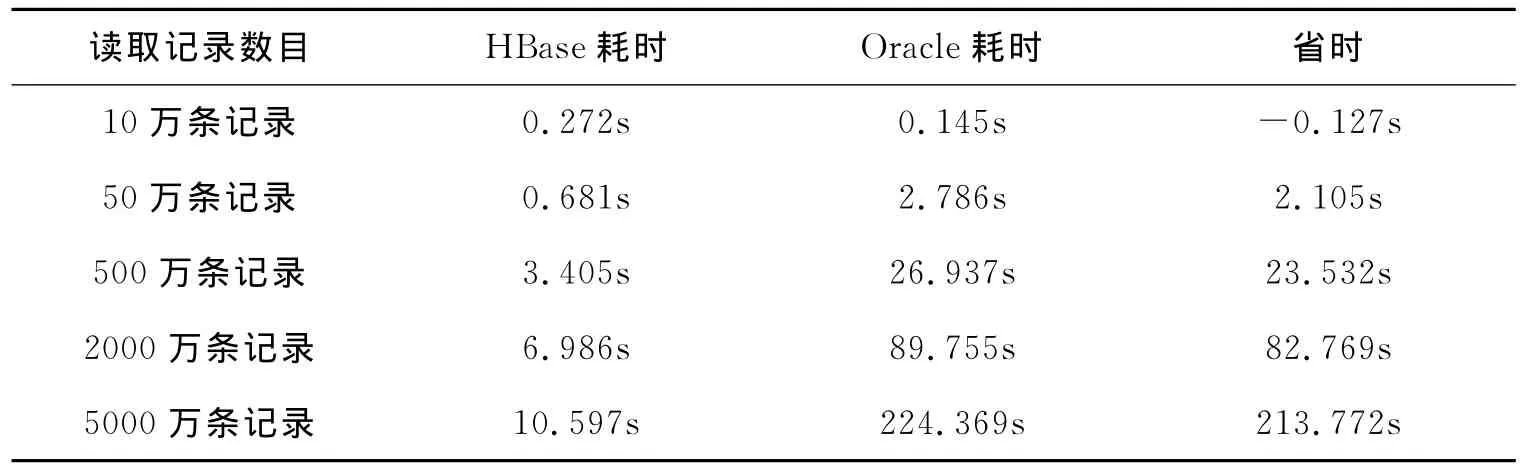
表2 不同数据规模扩展实验耗时比较
为了直观观察结果,将表用折线图(图2)表示出来,其中横坐标为数据集大小,纵坐标为时间,“☆”为Oracle单机版,“○”为单机模拟的HBase集群。
从图2中可以看出:随着数据量的不断增大,Hadoop版系统解约的时间越多,优势越明显。对于实验数据源按照一条记录2k来计算,5000万条记录实际上只有大约80G的数据量,而Hadoop平台只有在处理超大规模数据量时优势才能明显显现。如果其处理的是智能电网内部的录波数据,Hadoop平台就能发挥出强大的数据处理能力。
4 结语
本文根据智能电网环境下录波数据的特点提出用Hadoop作为平台、用HDFS作文件存储系统的云存储方法,并设计了录波数据在HBase中的面向列的存储格式,最后将用Oracle做数据库的传统方法与本研究所提方法进行了访问速速的对比,证明了新方法的高效性。下一步的工作主要是在原型系统上利用Map Reduce分析HBase数据库中存储的录波数据,更高效地对电网故障进行状态评估与预测。
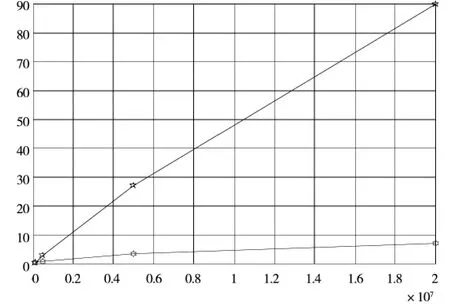
图2 不同数据规模实验结果对比图
[1]赵宾.电力系统故障录波器的研究与实现[D].东北大学,2006.02.
[2]http://hadoop.apache.org/.
[3]张杰,涂东明,张克元.基于COMTRADE标准的故障录波的分析与再现[J].继电器,2000,20(11):20-21.
[4]The Hadoop Distributed File System:Architecture and Design.http://hadoop.apache.org/core/docs/r0.16.4/hdfs_design.html.
[5]Hadoop HBase Performance Evaluation Introduction.http://www.cs.duke.edu/~kcd/hadoop/kcd-hadoop-report.pdf.
[6]Jeffrey Dean,sanjay Ghemawat.MapReduce:simplified data processing on large clusters[C]//6th Symposium on Operating Systems Design and Implementation.USA,2004.
[7]http://www.hadoop.org,2009-5-15.
The storage and access of the recorded data based on Hadoop
BAI Hong-wei1,MA Zhi-wei2,ZHU Yong-li1,BAI Hong-hao3
(1.SchoolofControlandComputerEngineeringNorthChinaElectricPowerUniversity,BaodingHebei071003,China;2.HuanengQinbeiPowerPlantDepartmentofElectricalMaintenance,Jiyuan,Henan459012,China;3.SchoolofEnvironmentalProtectionandSafetyEngineering,UniversityofSouthChina,HenyangHunan421001,China)
In the smart grid,recorded date is wide,panoramic,reliable and mass.The old way is using ER database management system based on disk arrays,which leads the poor system scalability,high cost,and low reliability,those are all really hard to match the requirements.Compared the access speed with the traditional method,the method of the access and recorded data based on the Hadoop with distributed storages It is proposed more efficiently.
Recorded data;Hadoop;Data Storage;Data Access
TP393
:A
1001-9383(2011)03-0043-05
2011-06-30
国家自然科学基金资助项目(60974125);中央高校基本科研业务费专项资金项目(10QG22)
白红伟(1985-),女,硕士研究生,主要研究领域:计算机应用、云计算.
猜你喜欢
电气技术(2022年8期)2022-08-20 02:33:22
数学大王·趣味逻辑(2021年11期)2021-12-03 11:04:30
网络安全和信息化(2018年9期)2018-03-03 18:11:15
信息安全研究(2018年1期)2018-02-07 01:44:46
网络安全和信息化(2017年12期)2017-11-08 10:39:14
河南电力(2016年5期)2016-02-06 02:11:32
云南电力技术(2015年2期)2015-08-23 01:32:08
河南电力(2015年5期)2015-06-08 06:01:46
河南电力(2015年5期)2015-06-08 06:01:46
电测与仪表(2015年2期)2015-04-09 11:29:26
