
基于高校图书馆流通日志的数据挖掘
2011-10-12 03:06:02毕长泉曹健王朝阳
中国科技信息 2011年4期
毕长泉 曹健 王朝阳
河北理工大学图书馆,河北唐山 063009
基于高校图书馆流通日志的数据挖掘
毕长泉 曹健 王朝阳
河北理工大学图书馆,河北唐山 063009
通过对一定时期内学生读者群流通日志数据,应用关联规则进行数据挖掘分析,发现读者阅读倾向及各学科知识之间隐含的相互关联,从而更好地指导图书馆开展资源建设工作,实现合理资源配置、优化馆藏结构,为教学科研做好服务工作。
在信息资源高度数字化的今天, 图书借阅仍然是高校图书馆开展信息服务的最基本、最主要的内容。高校图书馆自动化管理系统中每天产生着大量的统计数据和表单,为了避免陷入数据丰富、信息贫乏的局面,从海量数据中提取有用信息,更是我们需要考虑和解决的问题。特别是流通系统,更是图书管理子系统的重中之重,通过对流通日志数据的分析,可以得出读者的阅读倾向,而读者的阅读倾向决定了馆藏结构是否合理,对图书馆馆藏建设有着很强的指导作用。如何对大量的流通数据进行分析,目前比较有效的方法就是通过数据挖掘技术。
1、数据挖掘技术
数据挖掘(Data Mining—DM)技术就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的模式的过程。模式也就是所挖掘出的信息和知识。人们把原始数据看做是形成知识的源泉,就像从矿石中采矿一样。原始数据可以是结构化的,也可以是非结构化的。如文本、图形、图像数据,甚至是分布在网络上的异构数据。发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的。发现了的知识可以被用于信息管理、查询优化、决策支持、过程控制等,还可以用于数据自身的维护。
2、数据挖掘过程
数据挖掘过程主要包括三个阶段:数据准备、数据挖掘、结果解释和评价。
(1)数据准备:数据准备又可以分为2个子步骤:数据选取、数据预处理。数据选取的目的是确定发现任务的操作对象,即目标数据。是根据用户的需要从原始数据库中抽取的一组数据;数据预处理一般包括消除噪声、推导计算缺值数据、消除重复记录、完成数据类型转换(如把连续型数据转换为离散型数据,以便于符号归纳;或是把离散性数据转换为连续型数据,以便于神经网络计算)以及对数据降维(即从初始特征中找出真正有用的特征以减少数据挖掘要考虑的变量个数)。
(2)数据挖掘:数据挖掘阶段首先要确定数据挖掘的目标和挖掘的知识类型。确定挖掘任务后,根据挖掘的知识类型选择合适的挖掘算法,最后实施数据挖掘操作,运用选定的挖掘算法从数据库中抽取所需的知识。
(3)结果的解释和评价:数据挖掘阶段发现的知识,经过评估,可能存在冗余或无关的知识,这时需要将其剔除;也有可能知识不满足用户的要求,需要重复上述挖掘过程重新进行挖掘。另外,由于数据挖掘是最终要面临用户的,因此,还需要对所挖掘的知识进行解释,以一种用户易于理解的方式(如可视化方式)供用户所用。
3、关联挖掘结果及分析
我们选取了06级资环学院、计控学院、外国语学院、理学院和文法学院的学生读者共计848人,对其借阅总量和英语类、文学类、自动化及计算机技术、理化类、政治、法律类等图书借阅量分别进行了统计分析,并运用数据挖掘方法计算出其相关的支持度,见(表一)。
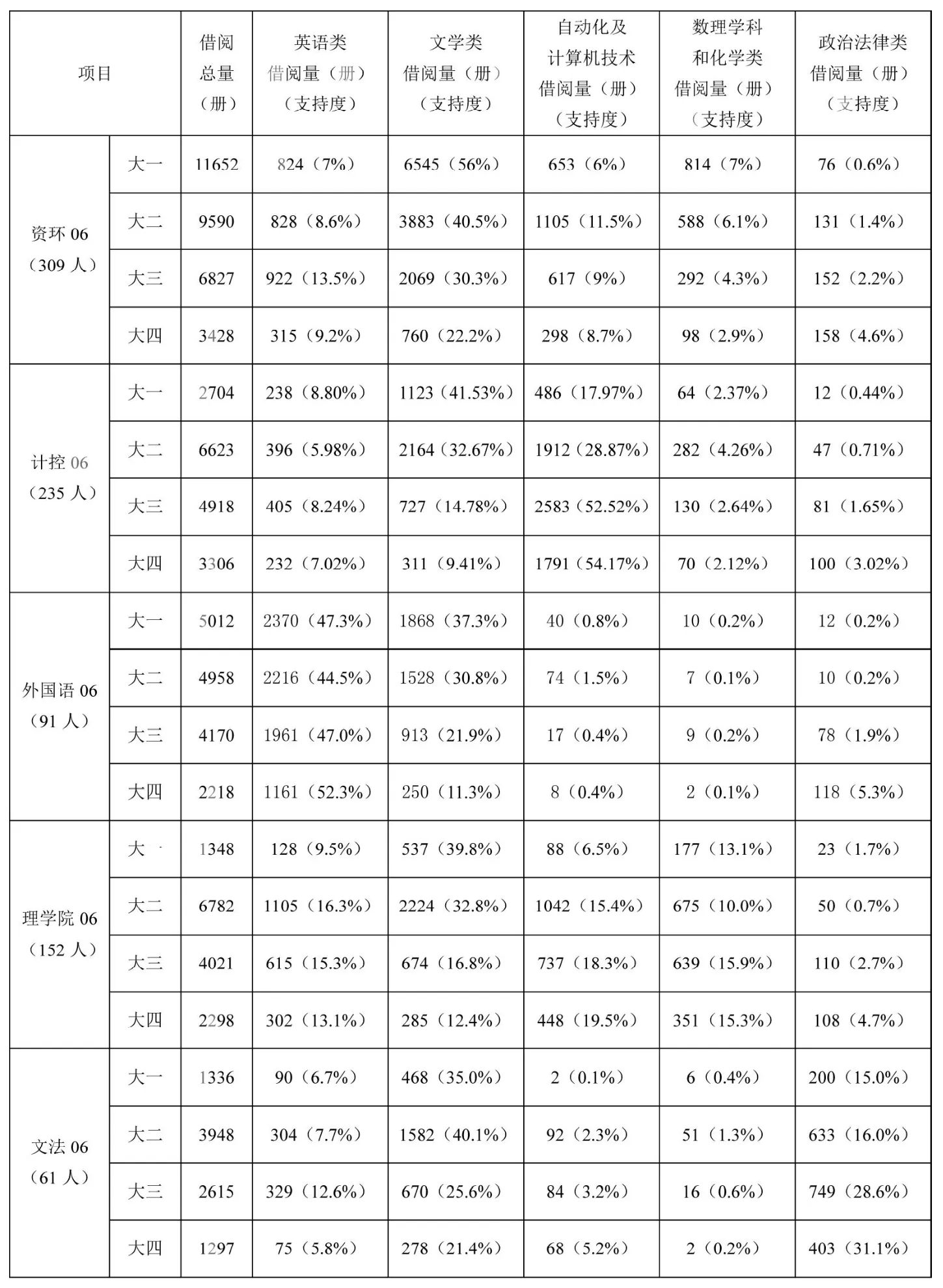
表一 借阅量统计及相关的支持度
通过对表一的分析,发现如下特点:
(1)文学类图书占据借阅量的首位,支持度平均可到30%左右。这说明文学类书籍仍是高校读者课外阅读的首选。大学生读者对语言学习及文学、艺术的学习、欣赏的需求已经大大超过了专业及基础学科学习的需求。
(2)借阅高峰集中在大一、大二阶段,他们对文艺类图书的需求也相对集中,支持度最高达到56%。但是,这部分读者只是借助文学作品来消遣和娱乐,他们阅读倾向于流行、时尚相关联的文学作品,读书不再单纯上的知识获得,很大程度上还是精神消费。
(3)专业图书占据借阅量的第二位,比如计控学院对计算机类图书,理学院对理化类图书、文法学院对政治法律类图书的需求均比较大,外语学院对外语类图书的需求甚至超过了文学类图书占据首位。这也说明我校学生对专业知识的渴求度较大,他们以专业学习为主,在课堂以外,需要借助各类参考书来弥补自己的知识不足,提高专业水平。
(4)不同专业学生对于非本专业图书有一定的需求。特别是计算机类和外语类图书,主要是大学阶段要面临英语四六级考试、计算机等级考试、考研以及近年来毕业生找工作时用人单位都比较注重毕业生的计算机和外语的能力等。
(5)资源、计控、理学院等学院的学生很少借阅政治法律类图书,而外语、文法学院的学生又很少借阅计算机类和理化类的图书。表明理工类和文科类两大学科之间的交叉项较小。
4、数据挖掘应注意的问题
(1)数据挖掘时要选择合适的读者群确定挖掘目标。对于过宽泛的读者群会使我们在庞杂的数据中,很难发现任何有价值的信息。
(2)确定合理的时间段和适当的数据规模,可以保证数据挖掘工作的顺利进行。过小的数据量很难说明普遍性的问题,容易使结果产生偏差;过大的数据量则会明显增加挖掘的难度,降低计算的效率。
(3)实际操作过程中可根据规则产生的实际数量和预定的目标对最小支持度和最小可信度标准作适当的调整,以避免过多或过少规则的出现。
5、总结
基于流通日志的数据挖掘技术可以发现读者的借阅模式和借阅喜好,同时,能够发现庞杂的流通数据中存在的隐含关系,将读者需求从定性分析上升到定量分析,这无疑对图书馆的信息服务工作起到很好的指导作用。它不仅是图书馆建设合理的信息资源保障体系的重要依据,也是图书馆开展以读者需求为导向的各项服务工作的基础。
[1]王伟,张征芳,王明海.基于数据挖掘的图书馆读者行为分析[J].现代图书情报技术.2006, (11): 51-54
[2]冯进.利用数据挖掘技术深入挖掘图书馆工作[J].现代情报.2005,3(3):131-132
[3]罗凤莉.基于关联规则挖掘的图书流通信息分析.晋图学刊.2007(1):28-29
[4]Alex Berson,StephenJ.Smith,Data Warehousing,Data Mining,&OLAP[M],McCraw-Hill Book Co,1997
G258.6
A
10.3969/j.issn.1001-8972.2011.04.040
河北理工大学教改重点项目(项目编号:Z0814-14)
毕长泉,硕士,教授高工,主要研究方向:信息技术、数据挖掘等。
图书流通;关联规则;数据挖掘;馆藏结构
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
西藏艺术研究(2019年4期)2019-09-07 09:12:54
新闻传播(2018年2期)2018-12-07 00:56:02
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
中国建筑装饰装修(2017年2期)2017-06-05 09:15:04
新闻传播(2015年4期)2015-07-18 11:11:31
新闻传播(2015年12期)2015-07-18 11:02:41
江苏年鉴(2014年0期)2014-03-11 17:09:34
电子设计工程(2014年19期)2014-02-27 12:00:42
