
基于内容的音频检索研究
2011-10-11 06:23:22吴春辉陈洪生
大众科技 2011年2期
吴春辉 陈洪生
(咸宁学院计算机科学与技术学院,湖北 咸宁 437100)
基于内容的音频检索研究
吴春辉 陈洪生
(咸宁学院计算机科学与技术学院,湖北 咸宁 437100)
文章介绍了音频检索系统的通用流程,并对其过程逐一进行阐述,最后利用一个简单的系统对基于内容的音频检索方法进行了测试。
基于内容的检索;音频检索系统;音频
(一)引言
随着现代信息技术和存储技术的快速发展以及互不干涉信息网(www)的迅速发展,越来越多的多媒体信息以数字形式存储和传输,人们可以更灵活地使用这些信息。但随之而来的问题是,面对大量包含多媒体数据的数据库,人们不再满足于通过一般的属性(如姓名、时间等)进行检索。如计算机检索音频片断,可以使用基于标题或文件名的文本标注方式。然而传统的基于关键字或文件名的检索方法显然不适于数据量庞大、不具有天然结构特征的各种音频数据。为了使人们快速的检索到所需的多媒体信息,近年来,国内外在多媒体数据库技术的研究中开发了一种基于内容的检索 CBR(Content Based Retrieval)技术。
(二)基于内容的音频检索系统通用流程
基于内容的音频检索技术突破了基于关键词匹配的传统检索技术的限制,它根据音频本身所固有的特征而不是人工标注的外部属性或者关键词对音频进行检索。它的核心思想是通过一定的计算机处理,分析音频的结构和语义,建立它们的结构化的组织和索引,使得“无序”的音频变得“有序”,从而有利于用户的浏览和检索。
基于内容的音频数据库检索系统是一种重要的多媒体信息处理技术。在音频检索中,需要经过特征提取、音频分割、音频识别分类和索引检索这几个关键步骤。图 1为基于听觉内容的间频检索流程图。

图1 基于听觉内容的音频检索流程
(三)音频特征抽取
音频信号携带各种信息,在不同的应用场合下,人们感兴趣的信息也不同。比如,对于语音来说,判断其是否为语音,只需要提取人类语音信号的一般特征就足够了,而为了区分是清音还是浊音,就应该了解其能量谱分布和基音频率。为了满足音频管理和检索的需要,基于内容的音频数据模型需要提取音频的低层特征来表现音频低层内容。音频具有心理属性和物理属性,同样对音频特征的提取也有两种方法,即提取听觉感知特征(音调、响度)和计算非感知特征或称物理特性(对数倒谱系数,线性预测系数)。不同的特征表达音频的不同方面,适用于不同的应用范围。
音频特征抽取是指寻找原始音频信号表达形式,提取能代表原始信号的数据。下面介绍几个常见的特征。
1.音调。音调与基音周期有关,是音频信号的一个重要参数,在音频处理中有重要的作用。比如对于语音数据,音调是分辨男女声的重要参数之一。
2.响度。这是较常用的感性特征,与短时能量密切相关。计算应在时域进行,一般是对每帧数据取平方和,然后计算其平方根。
3.短时平均过零率(Zero-crossing Rate)。它是指在一个短时帧内,离散采样信号值由正到负和由负到正变化的次数,即两个相邻取样值有不同符号时,便出现“过零”现象。单位时间过零的次数称为“过零率”。这个量大概能够反映信号在短时帧内里的平均频率。短时平均过零率是区分音频信号有声或无声的重要标志之一。对于音频信号流x中第m帧,其过零率计算如下:
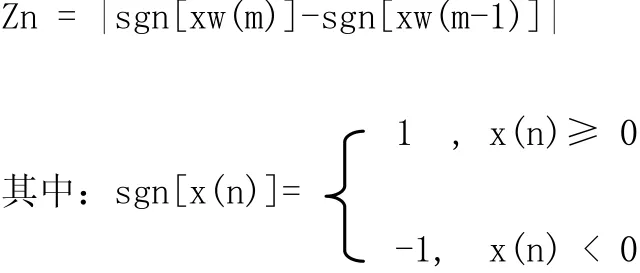
4.Mel变换对数倒谱系数(Mel-Scaled Frequency Cepstral Coefficient,MFCC)。这是音频数据经Z变换和对数处理后得出的结果。一般对每帧数据取12个系数,可以很好地表现每帧的特征。其处理过程如图2所示:

图2 Mel计算过程
5.线性预测。线性预测又称为线性预测编码(LPC),是音频处理的常用技术,即对音频信号的各个取样值,可以用它过去若干个取样值的加权和(即线形组合)来表示。各加权系数的确定原则是使预测误差的均方值最小(即遵循最小方差原则)。
(四)音频分割及识别分类
音频是连续的时间序列信号,犹如不可能对几十分钟或几十个小时视频一起处理一样,也不可能对持续时间很长的音频处理。首先需要对连续的音频流进行分割,将连续音频信号流分割成长短不一的音频单元后,再对每个音频单元进行识别,将它们归属为不同的音频类别,如语音、音乐和环境背景音等。
音频分割方法的研究较少,但音频分割对最终的音频流处理结果的准确率有很重要的影响,它直接关系到音频镜头切分的准确性。传统的音频分割主要采用滑窗法和基于规则的方法。
1.滑窗法
传统的音频分割方法通常是采用简单的滑动窗口技术,即用固定长度的滑窗对音频流简单分割,在滑窗内部按“投票规则”(vote rule)将音频流平滑为一个类别,即哪个类别的clip数最多,就认为该滑窗内所有的clip都属于该类别。然后将具有相同音频类别的滑窗合并得到最终的分割结果。
2.基于规则的分割方法
该方法基于音频连续特性,根据该特性可以设计分割准则对音频clip序列进行平滑,然后再将具有相同类别的音频clip合并得到最终的分割。不同的分割工作中根据需要和具体音频分类的类别可以采用不同的分割准则。
(五)音频检索系统
音频检索系统主要包括音频入库、音频文件特征提取、基于内容的检索和相关音频处理三大部分。其结构如图 3所示。
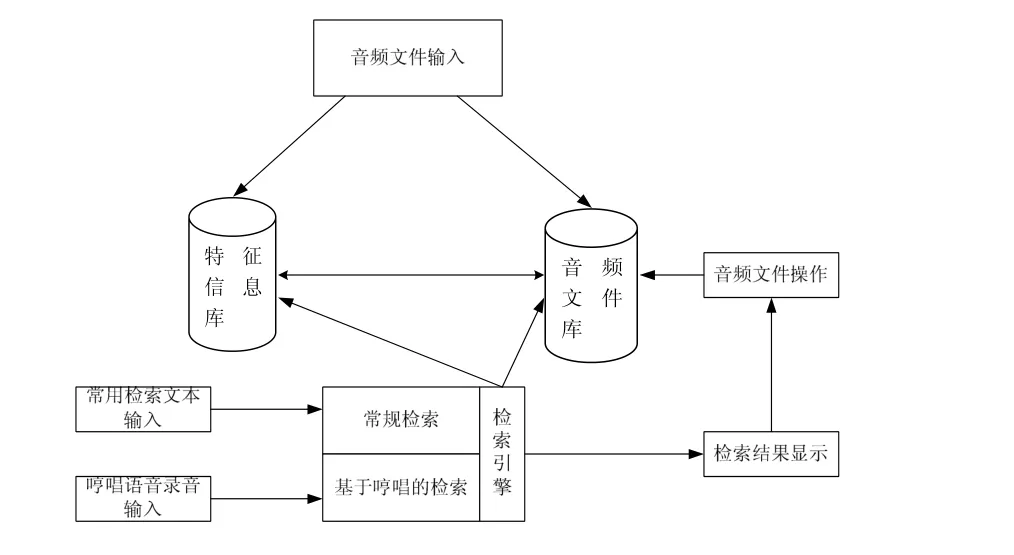
图3 基于内容的音频检索系统结构图
图 4为基于哼唱的检索界面,用户进入该界面后,可以先录一段自己的语音,然后保存为.wav文件,检索时可以检索出来,并且按照匹配的结论把结果按照从小到大的顺序反馈给用户,表示可能是三个人中的一个在说话。并且排在第一位的说话人的概率最大。
在实验中,说话者张龙先“哼”了一段自己的语音,然后检索,可以看出,该实验中检索出说话者最大可能性是张龙。
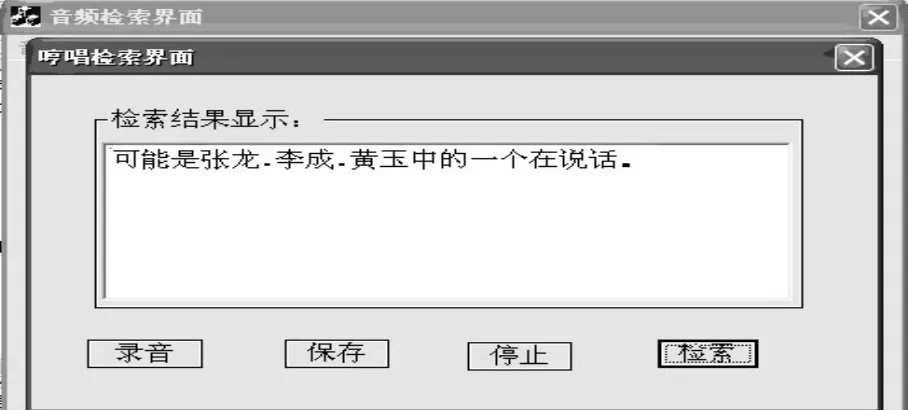
图4 “哼唱”检索界面
(六)结束语
多媒体数据库虽然经过了20多年的发展,但是目前对多媒体数据库技术的研究仍处于初级阶段,特别是基于内容的检索技术在国内外仍处于研究、探索阶段。文章提供了一个简单的基于内容的音频检索系统,该系统能很好的用于检索测试,但是用于实际还需进一步加强和改进。
[1] 黄志军,曾斌.多媒体数据库技术[M].北京:国防工业出版社,2005.
[2] 韩纪庆,张磊,郏铁然.语音信号处理[M].北京:清华大学出版社,2004.
[3] 李恒峰,李国辉.基于内容的音频检索与分类[J].计算机工程与应用,2000,7:54-56.
[4] Frakes W,Baeza-Yates R.Information retrieval:data structures and algorithms[M].New Jersey:Prentice Hall,1992.
[5] Wold E.,Blum T., keslar D.,etal,Content-based classification,search,and Retrieval of audio[J]. IEEE Multimedia,1996,27-36.
TP391.42
A
1008-1151(2011)02-0024-02
2010-12-13
吴春辉(1981-),女,湖北通城人,咸宁学院计算机科学与技术学院讲师,硕士,研究方向为多媒体数据库。
猜你喜欢
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
信号处理(2018年1期)2018-09-03 07:53:04
信号处理(2018年5期)2018-06-28 02:16:02
信号处理(2018年4期)2018-06-27 03:34:16
信号处理(2018年3期)2018-06-27 03:30:18
电子制作(2017年9期)2017-04-17 03:00:46
新校长(2016年8期)2016-01-10 06:43:59
人间(2015年8期)2016-01-09 13:12:42
商事法论集(2014年1期)2014-06-27 01:20:42
