
基于数据流聚类的手机短信监管系统
2011-09-07 10:17:10谢冬青
计算机工程与设计 2011年9期
綦 科, 谢冬青
(广州大学计算机科学与教育软件学院,广东广州510065)
0 引 言
手机短信的泛滥不仅对网络产生冲击,更造成严重不良社会影响。加强短信,特别是垃圾短信的监管是维护短信市场的正常秩序,保障信息安全的关键[1]。短信监管的基础是短信的内容识别问题。目前短信监管过滤功能的技术实现绝大部分是基于内容关键字过滤技术和号码黑白名单过滤技术[2-3]。这二类过滤技术存在严重不足:①过滤规则需要事先定制,缺乏及时性和动态性,用户操作麻烦;②无法满足用户个性化定制需求;③基于文本匹配的方法处理效率较低,无法满足大规模短信实时过滤监管的要求;④容易发生错误过滤,识别精度不高。
与正常短信比较,需要监管的短信具有如下特点[4]:①短信的内容都很近似,某段时间内不会做修改或者做很小的修改;②发送频率比较高,发送数量大;③相同内容的短信发送给不同的接收者;④发送没有时间特征,即任何等长时间段发送短信的数目相同,因此,考虑到短信的接收发送都必须经过短信中心的转发,结合以上需要监管短信的特点,短信的监管大多在短信中心实施。但这种监管方式存在的不足在于:某些短信,对于不同的人有着不同的作用,它可能是垃圾短信,也可能正是接受者所需要的短信,因此监管需要有个性化的选择,而这在短信中心是比较难实现的。因此,针对现有短信监管方法的不足,本文基于文本数据流聚类算法和Bayes分类算法,利用短信中心可以集中监控发送者的优势,设计短信接收者和短信中心端互动的二层监管模型的技术手段,实现高效的手机短信监管系统,有效的发现短信的发送者,使之成为个性化手机短信监管过滤和源头跟踪的有效解决方案。
1 短信监管系统的设计
1.1 系统框架
系统采用数据流聚类算法,利用短信中心可以集中监控发送者的优势,设计短信接收者和短信中心端互动的二层监管模型的技术手段,实现高效的手机短信个性化监管系统。系统服务器端应用在Windows平台上,以Oracle8i为数据库,实现提出的基于数据流聚类的短信监管系统;客户端支持以Windows Mobile为操作系统的智能手机终端。系统体系结构如图1所示。

图1 系统架构
1.2 功能设计
系统结构分为中心服务器和客户端代理引擎二部分:系统将核心分类算法放置在短信中心服务器端,将客户端引擎作为客户端代理放置在客户终端。短信中心从终端上收集用户反馈的信息,然后对它们进行机器学习。机器学习后更新特征库,客户终端从中心下载这些更新特征。
(1)客户端代理引擎--分类引擎
客户端代理运行在终端上,以后台服务的方式运行,短信分类引擎将用到存储在终端并与短信中心实现同步更新的数据:个性化短信特征库。分类引擎具有以下功能:
1)当短信到达时,根据分类特征库,调用分词模块和贝叶斯分类模块,判别接收的短信是否属于垃圾短信。
2)由用户根据自己的喜好自行决定短信是否属于垃圾短信。
3)通过网络向短信中心反馈接收到的短信是否属于垃圾短信,信息发送者号码,发送时间,接收者号码等信息。
4)通过网络定期从短信中心下载更新的个性化特征库,在下一条短信到达终端时,采用更新后的特征库进行分类判别。
(2)中心服务器--短信处理中心
短信处理中心实现的是一种分布式的短信分类学习系统,同时采用数据流聚类算法对短信源头进行跟踪。其具体功能点如下:
1)黑白名单库和个性化特征库的维护更新。以二种途径进行特征库的更新:一是接收客户终端反馈的短信分类信息,进行增量学习,每隔一段时间形成增量更新。服务器端在收到用户反馈的短信后自动触发Bayes机器训练算法,进行机器学习,更新个性化特征库;经过Bayes机器学习后的增量更新包括:新增的特征项及其在垃圾短信和正常短信中出现的条件概率;客户端反馈的删除的特征项;重新计算后的特征项及其在垃圾短信和正常短信中出现的条件概率。二是在短信中心维护黑白名单库,由人工更新。
2)短信内容处理模块。包括分词处理模块、特征提取模块。分词处理模块对短信进行高效率分词;特征提取模块则提取短信长度特征、频率特征、规则特征、文本特征等信息。
3)数据流聚类模块。通过数据流聚类算法找出潜在的监管短信,再根据这些短信找到潜在短信的短信发送者。
1.3 工作流程
如图1所示,系统对短信的分类流程如下:
(1)短信中心收到短信后,将短信文本送入黑白名单库,依据黑白名单库对短信进行第一层过滤。未通过第一层过滤的垃圾短信被屏蔽;通过第一层过滤的短信送入数据流聚类模块。
(2)通过第一层过滤的短信送入数据流聚类模块后,应用数据流聚类算法进行垃圾短信源头的识别,并将识别结果存入黑白名单库,封锁该号码。
(3)没有被封锁的短信,由短信中心转发短信给接收者。
(4)用户接收到经过短信后,根据终端上的分类引擎和分类特征库,调用分词模块和贝叶斯分类模块,将短信正确分类(垃圾或非垃圾短信)。
(5)由用户根据自己的需求自行决定短信分类类别。
(6)通过网络向短信中心反馈短信的分类类别,信息发送者号码,发送时间,发送者号码等信息。
(8)短信接收者通过网络定期从短信中心下载更新的个性化特征库,在下一条短信到达终端时,采用更新后的特征库进行分类判别。
2 关键技术实现
(1)服务器端和客户终端的短信文本分词
要实现短信的监管,首先必须理解短信的内容。对于短信中文文本而言,要理解短信内容,必须对中文文本进行分词[5]。分词是将短信分割成一个个有意义的单词。与英文等以词为最小语言单位不同,中文的最小语言元素是字,字再构成词,而且词之间没有分隔标记(比如空格),所以中文的分词相对来说复杂很多。
针对短信文本,在对其进行分词之前,首先进行文本预处理,去除对分类没有用处的词,主要是分词后形成的单个的字,以及代词、叹词、语气助词等。预处理可以通过查表(助词表、代词表)方式进行。
系统分别在服务器端和客户端进行分词。现在的分词算法[6-7]主要包括二类:一类是机械式分词法,一般以分词词典为依据,通过文档中的汉字串和词表中的词逐一匹配来完成词的切分,另一类是理解式分词法,即利用汉语的语法知识和语义知识进行分词,需要建立分词数据库、知识库和推理库。由于理解式分词法在语义分析和语法分析等方面远未成熟,因此现有分词系统多采用机械式分词法。
本系统采用中科院FreeICTCLAS分词系统[8],该分词系统为机械式分词系统,具有较高的分词准确度和分词速度,且具有较高的灵活性,可以依据需要裁减分词词典。考虑到短信文本中所用的词汇一般都为常用词,且服务器端对短信处理实时性的要求,以及手机终端存储和处理能力的限制,我们对分词词典进行了精简和压缩,减少了词典规模,最终分词词典包含约4万条左右的词条,占用存储空间为2.5M左右,完全满足服务器端和客户终端的分词需求。
(2)黑白名单库和特征项条件概率表的维护更新
小流域是山区水源涵养和集水的基本单元。只有把小流域保护好、治理好,大流域的河道、水库水质、水量和生态才有基本保障。建设生态清洁小流域的最终目标,是促进生态系统良性循环,人与自然和谐相处,实现流域人口、资源、环境协调发展。
系统在服务器端维护黑白名单库,设置黑白名单过滤特征库和关键词库,由人工随时更新。同时,系统在数据流聚类模块,应用数据流聚类算法进行垃圾短信源头的识别,并将识别结果经人工确认后更新黑白名单库。
再者,系统维护一个最多包含200项特征项的条件概率表。客户终端通过Internet或3G无线网络向服务器端传输反馈的个性化短信分类信息,包括短信分类类别(垃圾或非垃圾短信)、信息发送者号码、发送时间、接收者号码等信息。服务器接收客户终端反馈的短信分类信息,应用Bayes算法进行增量学习,收到用户反馈的短信后自动触发机器训练算法,进行机器学习,更新或新增特征项及相应的条件概率。
(3)贝叶斯分类
贝叶斯分类[9]是基于贝叶斯定理进行的分类,该算法可以预测样本属于每类成员的可能性,最后将样本分到可能性最大的那个类别中去。
贝叶斯分类过程如下:
1)读入训练样本短信,并统计各类短信数目;
2)读入分词词典,对训练样本短信进行分词处理,得到各词条及对应的文档频率(document frequency,DF)值。
3)根据特征向量选取方法,按DF值从大到小,各类选前200个特征词形成特征向量;
4)读入训练样本短信,对贝叶斯分类器进行训练;
5)读入待分类短信,用训练后的贝叶斯分类器进行识别,并给出分类结果。
系统在短信中心端设置了二个贝叶斯分类器:一个用于短信的实时分类,当用户短信到达短信中心,由服务器调用,对短信进行分类判断;另外一个作为后台服务程序,定期轮询每个用户,根据用户反馈的信息进行训练学习,并更新每个用户的个性化特征库。
系统在用户终端上同样启用了贝叶斯分类器,对到达用户终端的短信进行分类判断,然后提示用户作出选择判断。
(4)基于数据流聚类的短信源头跟踪
服务器端的数据流聚类模块根据客户端反馈的信息和监管短信发送者的特点,识别出真正的短信发送者,该模块的核心算法就是数据流聚类算法。数据流聚类是对元素集进行分组,使得组内元素尽量相似,组间元素尽量相异的数据处理方法。数据流聚类研究的方向很多,如:针对基于划分的k-中心聚类问题,Guha[10]在2000年首先提出基于k中心聚类的smallspace算法,该算法使用一个迭代过程实现了在数据流环境下的 k-中心聚类;将传统数据聚类思想应用到数据流聚类中,Cao[11]等人提出了Denstream算法,用基于密度的方法进行数据流聚类;针对多数据流的聚类问题,Beringer[12]等人提出了基于K-means的多数据流聚类方法,能够快速近似地计算数据流间的相似度,使数据流聚类算法在各个领域得到广泛应用。
数据流聚类算法可分为基于划分[13],基于密度[14]和基于网格[15]等几类,其中以基于划分的居多。但这些方法都只适合处理数值型数据,不适用于文本聚类,而短信一般表现为文本,因此必须采用适用于文本的数据流聚类算法用于文本的聚类。本系统应用Guha提出的k-中心聚类算法,找出潜在的被监管短信,再根据这些短信找出潜在的短信发送者,实现短信源头跟踪。
系统在数据流聚类模块,应用如上数据流聚类算法进行垃圾短信源头的识别,并将识别结果经人工确认后更新黑白名单库。
3 实验结果及分析
测试数据由某电信研究院提供,共20000条短信。经人工标注,垃圾短信共计1400条(色情类205条、诈骗类45条、广告类940条、谣言类80条、公共安全类130条),占所有用户短信的7%;正常短信18600条,占所有用户短信的93%。系统的软硬件测试环境为:服务器为Intel Pentium4 CPU,3GHz主频,4GB内存,500GB硬盘,Windows Server 2003操作系统;用户终端为dopodA8188型号手机,该型号运行Windows Mobile操作系统,CPU为600MHz的AMD微处理器,带有512M内存。

表1 测试结果
实验中从客户端收集到反馈的垃圾短信号码汇报个数共计64个,经系统的数据流聚类模块自动识别属于垃圾短信发送者的号码有53个,经人工确认垃圾短信发送者号码59个,源头跟踪准确率达到89.8%,这说明数据流聚类算法对识别垃圾发送者有较大帮助。
实验还对客户端性能进行了测试。表2给出了客户端性能测试结果。从测试结果看,贝叶斯分类时间很短,影响处理速度的是短信分词算法。但整体来看,客户端处理时间不超过2s,而且相对于当前智能手机的内存配置,客户端所占用的内存不超过10M,一般智能手机的运算速度和内存完全可以满足性能要求。
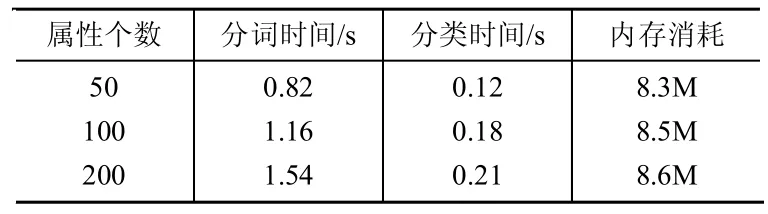
表2 客户端性能测试结果
4 结束语
本文描述了基于数据流聚类的短信监管系统的功能设计和关键技术分析,利用基于文本内容的数据流聚类算法,设计短信接收者和短信中心端互动的二层监管模型,实现短信的个性化监管和源头跟踪。系统经过实验测试,已经在某通信部门进行中小范围的试用,取得了良好的效果。提高系统的性能以支持更多的并发短信用户,以及综合考虑垃圾短信的特点以提高数据流聚类精度和源头跟踪精度将是本文的后续研究工作。
[1]黄文良,陈纯,罗云彬.一种高效垃圾短信过滤系统的实现[J].电信科学,2008,24(5):61-67.
[2]易阳峰.垃圾短信的监控与原理实现[J].中兴通讯技术,2005,11(6):49-54.
[3]Zhang ya,Fu jianming.Identifying and tracebacking short message spam[J].Application Research of Computers,2006,23(3):245-247.
[4]邓维维.数据流挖掘算法的研究及应用[D].广州:华南理工大学博士学位论文,2007:73-74.
[5]He Guobin,Zhao Jinglu.Search on algorithm of Chinese word automatic segmentation[J].Computer Engineering and Applications,2010,46(3):125-127.
[6]张启宇,朱玲,张雅萍.中文分词算法研究综述[J].情报探索,2008(11):86-91.
[7]文庭孝.汉语自动分词研究进展[J].图书与情报,2005(5):54-63.
[8]张华平.计算所汉语词法分析系统ICTCLAS[EB/OL].http://sewm.pku.edu.cn/QA/reference/ICTCLAS/FreeICTCLAS/,2009-12-01.
[9]Du Huifeng,Liu Qiongsun.Bayesian classifier using copula[J].Computer Engineering and Applications,2010,46(10):111-113.
[10]Guha S,Mishra N,Motwani R.Clustering data streams[C].IEEE Symposium on Foundations of Computer Science,2000:359-366.
[11]Cao F,Martin E,Qian W N,et al.Density-based clustering over an evolving data stream with noise[C].Proceedings of the Sixth SIAM International Conference on Data Mining,2006:328-339
[12]Beringer J,Hullermeier E.Online clustering of parallel data streams[J].Data and Knowledge Engineering,2006,58(2):180-204.
[13]Aggarwa C C,Han J,Wang J,et al.Frame work for clustering evolving data stream[C].VLDB Conference,2003:81-92.
[14]Cao F,Martin E,Qian W N,et al.Density-based clustering over an evolving data stream with noise[C].Proceedings of the Sixth SIAM International Conference on Data Mining,2006:328-339.
[15]朱蔚恒,印鉴,谢益煌.基于数据流的任意形状聚类算法[J].软件学报,2006,17(3):379-388.
猜你喜欢
新媒体研究(2021年15期)2021-09-18 02:10:24
新闻研究导刊(2021年14期)2021-09-10 07:22:44
蒲松龄研究(2020年3期)2020-10-28 01:38:41
汽车维修与保养(2020年11期)2020-06-09 05:42:22
智富时代(2019年6期)2019-07-24 10:33:16
电脑与电信(2018年12期)2018-03-23 02:37:36
高中生·天天向上(2016年9期)2016-11-22 09:10:34
西北工业大学学报(2015年3期)2015-12-14 13:08:48
中国卫生(2014年7期)2014-11-10 02:32:54
河南科技(2014年5期)2014-02-27 14:08:47
