
基于行为和内容协作分析的垃圾短信过滤系统
2011-06-09 07:23颜世莹
电信工程技术与标准化 2011年9期
颜世莹
(国家知识产权局专利局, 北京 100088)
1 引言
手机短信已经融入到人们的日常生活。然而,垃圾短信也随之而来并逐渐泛滥。愈演愈烈的垃圾短信不仅影响了人们的日常生活、浪费了宝贵资源和时间、甚至破坏了和谐的社会环境。全面彻底地治理垃圾短信需要从立法、管理、技术、宣传等多个角度进行。其中,从技术角度建立高效的垃圾短信过滤机制具有较低的实施成本和实施难度,因此有必要深入研究垃圾短信的过滤技术并部署垃圾短信过滤系统。
从技术角度研究垃圾短信过滤可以分为“网络服务器端”和“手机端”过滤两类方案。前者指垃圾短信在到达目标手机之前即被过滤,后者指通过手机中安装的垃圾短信过滤软件进行短信过滤。鉴于手机端过滤时垃圾短信已经送达并已对用户造成了影响,因而网络服务器端过滤方案的客户感知效果要好很多。为此,本文将主要针对网络服务器端的过滤。
主流的短信过滤机制包括针对短信发送者的静态黑白单策略和针对短信内容的字符串匹配策略。然而,仅依靠短信发送频率、发送数量等单一行为准则很难建立准确的垃圾短信黑名单,常常造成误判和漏判;而现有的比较短信内容与预设关键词是否匹配来决定短信投递的方法很容易被垃圾短信发送者绕过。此外,单纯地针对短信内容的字符串匹配具有较高的计算复杂度和计算时延。为此,有必要研究准确地、动态地黑白名单构建机制及简单高效的字符串匹配机制,并且结合两者的优点建立统一高效的垃圾短信过滤系统。
2 背景与需求
2.1 垃圾短信的定义和特征
尽管垃圾短信已经充斥了我们的日常生活,但是准确定义什么是垃圾短信仍然比较困难。到目前为止,无论是企业界还是学术界都没有统一的、权威的定义。从用户的观点看,凡是来自于和自己没有社交关系且超出用户预期的发送者,同时,用户认为其不需要此信息的短信,均可视为垃圾短信。这是一个相对宽泛的描述性定义。然而,我们很难度量用户是否需要此短信,因而这种定义缺乏可操作性。
为此,有必要从技术观点描述垃圾短信的特征来辅助判断和界定垃圾短信。通常具有以下6方面特征的短信均可视为本文研究的垃圾短信。(a) 社交缺失:短信的发送者和接受者基本没有通信联系;(b) 单向短信:短信的接收者针对短信回复率极低;(c) 内容类别:常常为广告类、涉黄类、欺诈类等信息;(d) 发送数量:相同或近似内容短时间内发送给成千上万甚至上百万目标号码;(e) 目标号码:短信的目标号码具有极高的相似性;(f) 短信位置:短信发送时常常位于单一位置。深入分析和识别以上6方面特征是件非常复杂的技术工作。采用何种工具和技术,对于以上这些信息进行分析和处理,构成了垃圾短信过滤和拦截的关键机制。
2.2 垃圾短信的发送方式
垃圾短信大致有两种发送方式:SP(Service Provider)型短信和点对点型短信(见图1,左侧实曲线路径代表SP型短信的发送路径,右侧实曲线代表点对点型短信)。前者通过运营商的短信接口系统或短信网关,利用计算机和互联网进行发送;后者通过普通的手机SIM卡或手机模块,利用计算机短信群发软件进行大量发送。随着短信资费下降和短信优惠套餐推出,点对点短信的发送成本急剧下降,加之运营商对SP型短信监管的加强,近些年点对点方式的垃圾短信逐渐成为主流。

图1 垃圾短信发送示意图
2.3 垃圾短信的过滤需求
垃圾短信过滤系统的核心需求包括:(1) 对用户侵扰尽量少,最好在用户不可知的情况下过滤垃圾短信;(2) 尽可能保证实时性,最好在尚未有任何用户收到垃圾短信之前过滤;(3) 较高的检出率;(4) 令人满意的误检率。从技术上讲,垃圾短信过滤本质上是模式识别问题。具有理想的较低的误检率是任何模式识别技术所必须的前提条件。
此外,系统还要满足其他条件:(1) 支持可扩展性和可伸缩性;(2) 支持动态配置和自动参数调节;(3) 支持与现网各相关网元的接口,例如与BOSS(Business& Operation Support System)、SMSC(Short Message Service Center)等;(4) 系统对现网系统改造小、成本低等。
3 垃圾短信过滤机制

图2 垃圾短信过滤机制流程图
本文提出的垃圾短信核心过滤机制见图2。3.1~3.3节将从三个方面详细描述相关细节。
3.1 非确定性动态名单
不同于现有采用黑白名单的静态过滤技术,本文采用非确定性动态名单。短信发送号码按照是否为垃圾号码(为便于讨论,将发送垃圾短信的号码简称为垃圾号码)的可能性建立三份名单。白名单中存在垃圾号码的概率为0%;黑名单中所有号码均为垃圾号码的概率为100%;灰名单中为可能的垃圾号码并且按照概率由高到低进行排列。通常将集团类用户、具有良好发送记录的老用户、已明确身份的用户等纳入白名单;将已经检测出发送垃圾短信行为的号码纳入黑名单;将处于两者之间的号码列入灰名单。名单内容按照垃圾短信的过滤和确认结果进行动态调整。
3.2 行为分析
垃圾短信发送者在发送行为上具有明显特征,大多垃圾短信发送者都采用群发的方式进行垃圾短信发送。由于对于短信内容的判断对系统性能的消耗较大,如果能够从发送行为特征的角度对垃圾短信发送者进行监控则可以很大程度的节约过滤系统的系统开销。此外,过滤系统的行为分析模型支持日常模式、节假日模式两种监控模式,在节假日采用节假日模式,适当提高各指标的阈值,在不影响业务量的前提下进行监控。
垃圾短信发送者行为分析的原理是对关键词过滤算法确定的垃圾短信发送者的各种发送行为进行统计,得出垃圾短信发送者发送行为规律的统计规律,某个用户的短信发送行为符合垃圾短信发送者行为规律,则初步判定该用户为垃圾短信发送者,利用关键词过滤算法对其发送短信的内容进行抽查,如果有垃圾短信则认定该用户为垃圾短信发送者。
具体行为分析模型(特征字段可以扩充,相应阈值根据实际统计情况确定)见表1。
3.3 内容分析
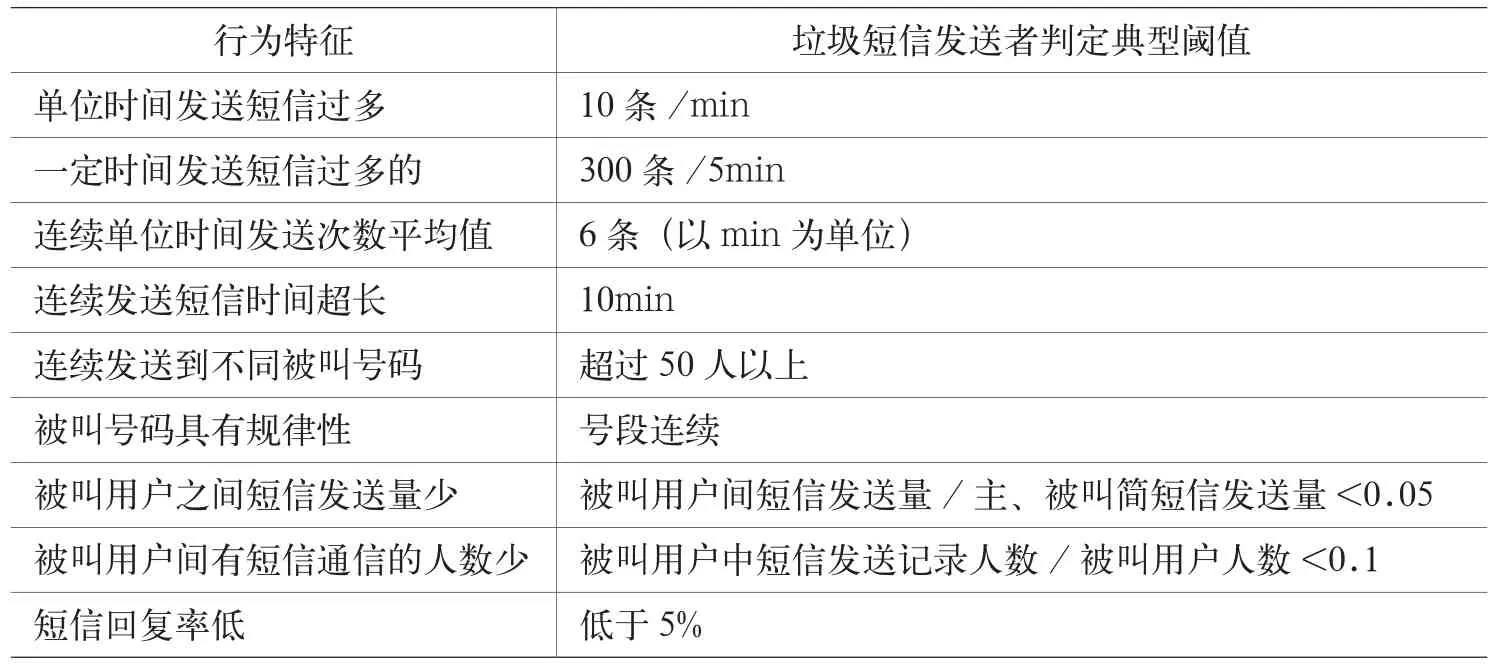
表1 垃圾短信行为建模
通过黑、白、灰名单以及短信发送行为的分析,将放行绝大多数正常短信,并识别出大部分垃圾短信。对于不太容易判断的短信,结合灰名单,需要进一步进行内容分析。
3.3.1 中文短信归一化
中文短信归一化指短信的内容转化为拼音或者模糊拼音。同时为了应对垃圾短信中加入混淆的内容,可以采取进一步的归一化措施。采用模糊匹配来查找关键字。为了降低误检率,可以限定模糊匹配的关键字之间的距离的范围。例如“漂】据”关键字的距离为单位,中间隔了2个字节。如果间隔范围过大,则认为匹配不成功。这种策略主要是为了提高过滤算法的实用性。例如在传统方法中,号码“+86133xxxx9750”发送的垃圾短信“本公司有多行业专用【漂】据,税点低,可网上查询”,如使用发票、票据等关键词均无法过滤。通过以上策略,采用归一化后的短信可轻松检出采用同音或近音字替换、加入混淆的垃圾短信。
3.3.2 短信内容分析关键算法
关键词过滤技术通常创建一些简单或复杂的与垃圾短信关联的单词表来识别垃圾短信。根据第一部分的分析可以了解到,每类垃圾短信都特定、经常出现的一些关键词,对这次关键词建立相应的关联词表,将用户发送的短信利用分词技术进行分词,然后利用KMP匹配算法匹配用户发送的短信是否包含垃圾短信关联词表中所包含的关键,如果包含则判定该条短信为垃圾短信。具体算法如下:
(1)收集大量的垃圾短信和非垃圾短信,建立垃圾短信集和非垃圾短信集。
(2)提取特征来源中的独立字符串,例如 AAA等作为TOKEN串并统计提取出的TOKEN串出现的次数即字频。按照上述的方法分别处理垃圾短信集和非垃圾短信集中的所有短信。
(3)每一个短信集对应一个散列表,hashtable_good对应非垃圾短信集而hashtable_bad对应垃圾短信集。表中存储TOKEN串到字频的映射关系。
(4)计算每个散列表中TOKEN串出现的概率P=(某TOKEN串的字频)/(对应散列表的长度)。
(5)综合考虑hashtable_good和hashtable_bad,推断出当新来的短信中出现某个TOKEN串时,该新短信为垃圾短信的概率。数学表达式为:A事件表示短信为垃圾短信;t1,t2…….tn代表 TOKEN串;则P(A|ti)表示在短信中出现TOKEN串ti时,该短信为垃圾短信的概率。设P1(ti)=ti在hashtable_good中的值,P2(ti)=ti在hashtable_bad中的值,则P(A|ti)=P2(ti)/[(P1(ti)+P2(ti)]。
(6)建立新的散列表hashtable_probability存储TOKEN串ti到P(A|ti)的映射。
(7)根据建立的散列表 hashtable_probability可以估计一新到的短信为垃圾短信的可能性。 当新到一条短信时,按照步骤2,生成TOKEN串。查询hashtable_probability得到该TOKEN串的键值。假设由该短信共得到N个TOKEN串,t1,t2…….tn,hashtable_probability中对应的值为P1,P2,……PN,P(A|t1,t2,t3……tn) 表示在短信中同时出现多个TOKEN串t1,t2……tn时,该短信为垃圾短信的概率。由复合概率公式可得:P(A|t1,t2,t3……tn)=(P1×P2×……PN)/[P1×P2×……PN+(1-P1)×(1-P2)×……(1-PN)]。当P(A|t1,t2,t3……tn)超过预定阈值时,就可以判断短信为垃圾短信。
(8)当新短信到达的时候,就通过关键词过滤器分析,通过使用各个特征来计算短信是垃圾的概率。通过不断的分析,过滤器也不断地获得自更新。比如,通过各种特征判断一个包含单词AAA的短信是垃圾,那么单词AAA成为垃圾短信特征的概率就增加了。
4 系统设计和原型实现
4.1 系统分析与设计
4.1.1 系统总体结构
垃圾短信过滤系统的总体结构分为6层(见图3),第0层为数据源层、第1层为数据采集层、第2层为数据存储层、第3层为数据分析层、第4层为系统互动层、第5层为过滤拦截层。其中,第0层为数据源层为逻辑层,是对数据源的逻辑抽象。其余各层具体功能描述如下:
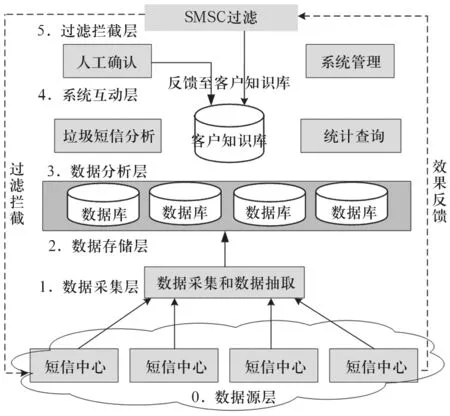
图3 垃圾短信过滤系统的总体结构
(1)数据采集层。该层从短信中心以FTP方式获得点对点短信原始数据文件,文件中记录包括短信主、被叫号码,短信发送时间,短信内容;短信中心作为服务器端。
(2)数据存储层。该层对数据源传过来的数据进行存储。主要完成对文件数据进行抽取、转换、加载,通过该过程将原始数据转换到分析数据库进行存储。
(3)数据分析层。该层作为垃圾短信过滤系统的核心层,负责垃圾短信的分析和中间模型的建立。包括如下软件模块:(a) 数据分析模块。分析的短信属性包括连续发送短信时间超长、连续发送到不同被叫号码、被叫号码具有规律性、单位时间发送短信过多、一定时间发送短信过多、连续单位时间发送次数平均数等;(b)异常用户分析模块。通过对用户属性的分析,对于异常的用户进行进一步的分析;(c) 客户知识库模型。建立相关的行为模型并进行调度和运算,对黑白名单的客户轮廓(短信发送频率、时间段、被叫号码的连续性等)进行全面的描述。(d) 统计查询模块。满足操作人员对用户数据的查询需求,包括黑白名单查询、异常用户信息查询、按照地域、短信内容、短信发送频次等条件进行查询、垃圾短信内容分类查询等。
(4)系统互动层。该层对垃圾短信的确认和对垃圾短信拦截的派单工作,包含如下软件模块:(a) 垃圾短信确认。通过人工的方式对垃圾短信进行确认;(b) 垃圾短信拦截派单。如果经人工确认为垃圾短信号码,则根据垃圾短信由BOSS系统向HLR、关口局、汇接局发送号码拦截指令,向系统发送垃圾短信黑名单,由系统转发SMSC进行过滤,并把BOSS系统反馈的黑名单结果记录到垃圾短信过滤系统中,由客户知识库进行管理。
(5)过滤拦截层。该层提供嫌疑名单给BOSS,由后者根据名单内容分别发送停机指令和屏蔽指令到HLR、关口局和汇接局。垃圾短信拦截功能具体由HLR或SMSC实现。
4.1.2 系统部署结构
系统采用模块化设计,多层化系统技术架构,层与层之间相互独立,数据通过内部接口传递,每层数据结构的改变不影响其他层的结构,有利于系统的扩展。因此系统相对独立,支持多种数据源的采集,不受数据采集方式的影响。系统由三类节点组成:采集节点、分析节点、管理节点,如图4所示。
(1)采集节点。垃圾短信采集节点需要从短信内容和短信发送方式两个方面着手,采用关键词过滤和概率算法对短信内容进行监控。
(2)分析节点。垃圾短信分析节点负责大量复杂的数据处理和综合分析,对原始数据进行分析,并进行沉淀,为垃圾短信分析提供数据和运算的基础。该节点部署数据挖掘软件,从数据库中获取数据,调度和运算各种模型,并将运算结果返回到数据库中。
(3)管理节点。垃圾短信管理节点提供人工确认界面、查询统计、系统管理等功能,提供与BOSS、SMSC的接口,用户传输灰名单和黑名单。系统管理主要包含如下功能:(a) 操作员管理,包括操作员信息管理、增加、删除、修改操作员、操作人员权限管理等;(b) 操作员日志管理,包括操作员对疑似骚扰号码确认结果、操作员拦截工单派发记录、拦截反馈记录等;(c)拦截有效期管理,对拦截有效期进行设定和修改,拦截有效期过后,将不再对骚扰电话号码进行通话拦截;(d)系统参数配置,对话单采集频度、话单保存时长等系统参数进行配置管理。

图4 垃圾短信过滤系统的系统部署结构
4.2 原型实现与验证
采用C++语言实现了该系统的关键算法和原型。从现网随机采集某时段的40万条短信进行验证分析。由于采用了非确定性动态名单、归一化关键字过滤等技术手段,一方面大大提高了过滤速度,另一方面也显著提高过滤的准确性。
5 结束语
日益泛滥的垃圾短信已经成为了一个亟需解决的重要课题。当前的垃圾短信过滤技术很难满足过滤的准确性与实时性要求。本文提出一种基于行为和内容协作分析的垃圾短信过滤机制并构建了原型系统。该系统可以大幅提高垃圾短信的过滤效率和效果。
[1] 中国移动通信有限公司. 垃圾短信监控平台接口规范V1.0.0[S].2007.
[2] 中国移动通信有限公司. 垃圾短信监控平台设备规范V1.0.0[S].2007.
[3] 中国移动通信有限公司. 垃圾短信监控平台总体技术要求V1.0.0[S].2007.
猜你喜欢
产经评论(2022年2期)2022-06-08
新媒体研究(2021年15期)2021-09-18
新闻研究导刊(2021年14期)2021-09-10
蒲松龄研究(2020年3期)2020-10-28
小学生学习指导(低年级)(2020年6期)2020-07-25
故事会(蓝版)(2020年1期)2020-01-19
奥秘(创新大赛)(2019年10期)2019-10-24
当代工人(2019年4期)2019-04-22
当代工人(2018年21期)2018-03-06
小说月刊(2014年1期)2014-04-23
