
CMMB信号测试数据异常值的检测方法研究
2011-06-07 05:53:18崔竞飞张国庭李婷婷
电视技术 2011年16期
白 鹤,崔竞飞,张国庭,李婷婷,赵 明
(国家广播电影电视总局 广播科学研究院,北京 100039)
0 引言
随着中国移动多媒体广播电视(CMMB)技术标准体系的成熟和产业链的完善,全国已有220多个城市进行了CMMB单频网的建设,覆盖测试是建设过程必不可少的环节,对测试数据进行分析能够指导网络规划、优化以及评估效果,但是作为后续处理基础的测试数据可能因为设备异常等因素造成数据失真,因此,需要检测异常值以保证测试数据的真实性和可靠性。
在城市的CMMB覆盖测试中,数据多元、大量,含有地理和时间等多维标记信息。目前,业界还没有针对CMMB信号测试数据进行异常值检测的有效方法,而利用统计学中的一般异常值检测方法的甄别效果也不理想。笔者基于对CMMB网络信号特征的分析,在采用欧氏距离对数据样本进行聚类之后,使用Z-统计量进行度量,可以有效地检测出CMMB测试信号异常值。
1 CMMB信号测试数据异常值
异常值[1]定义为“严重偏离了样本集合中其他观测值的观测值”,包括某样本的单个属性与该属性的大多数值出现分布偏离,或者该样本的属性间的结构和相关关系与整个属性集的属性之间结构和相关性不同。
异常值检测是数据挖掘中数据准备的重要环节,也是学界探讨和研究的内容[2]。目前主要有3种策略:
1)统计法。对样本总体分布作出假设的基础上,构造如四分位点、标准差等统计量进行检测,主要适用于单属性值的情况。
2)距离法[3]。将两个样本视为K维空间的两点,计算两点间的Minkowski,Chebyshev或Mahalanobis距离来度量,此方法能够应用于多元数值,但没有综合考虑总体分布的因素,导致太依赖于参数的选择。
3)分类法。建立分类模型判断数据类别,以认定其是否与总体偏离,一般需要有大量样本集以训练分类模型,并且此方法判断的颗粒度较大,相对于精细的数据要求显得误判率较高。
CMMB信号测试数据有经纬度、时间等标记属性以及Powerlevel,CNR等指标属性,各属性值有合理的取值范围,并且指标属性对应于一定的区域和时间内的标记属性,但是由于设备故障、无线特性或系统误差会使得指标属性在总体范围出现偏离或局部区域内发生跳变。因此异常值检测方法既需要考虑指标属性的统计学特征,同时要兼顾指标与标记属性的具体相关性。基于以上分析,各种异常值检测的通用方法不适合CMMB信号异常值检测的具体应用场景。
2 综合聚类和统计的检测方法
笔者处理的异常值包括因设备问题造成的标记空缺或指标超过正常范围的样本以及在一定区域内明显与周围指标值不同的孤立点。在对CMMB信号的数据特征分析的基础上,针对以上的检测对象,设计了一种结合统计学和地理信息聚类的检测方案。首先将多个CMMB信号测试文件合并为一个数据集合,在此基础上进行了空缺标记检测、界外指标处理、地理信息聚类以及对各区域数据进行孤值点甄别几个算法步骤,如图1所示。

2.1 空缺标记检测
如前所述,CMMB信号测试样本SCMMB有经度ALongtitude、纬度ALatitude和测试时间ATime等标记属性,可以准确地标定某一地点、某一时刻的信号强度APowerlevel、载噪比ACNR等指标属性
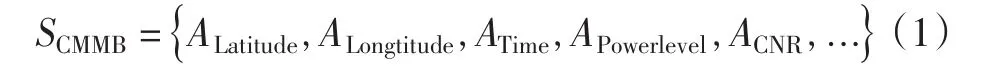
但是因为GPS设备搜索定位时延等原因,ALongtitude,ALatitude的标记信息可能出现空缺,此时记录下来的对应点的指标属性相对于评估来说就没有意义,因此需要将ALongtitude或ALatitude为空缺值的信号样本识别出并剔除。可以对此类异常值定义为
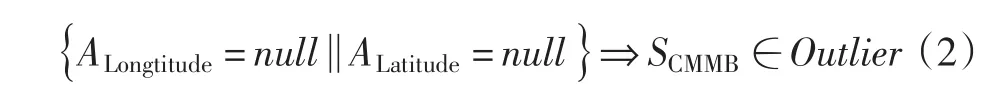
式中:null表示空缺值,Outlier表示异常值,此步骤从标记属性的角度保证了信号的完整性。
2.2 界外指标处理
CMMB信号测试样本SCMMB的指标属性包括APowerlevel、载噪比ACNR、误码率ABER等,其中对于接收效果最直接、最有效的评估度量是APowerlevel,在发射台站规划合理、测试地点空旷、频率干扰弱以及多径时延小等情况下,APowerlevel测试值会比较理想,即使信号覆盖不理想,指标值也会在一个合理范围内,但是在实地外场测试中由于设备、系统误差等原因,APowerlevel取值会超过合理范围,此时SCMMB因为测量值处于合理范围外而没有意义。定义此类界外值为

此步骤保证在全部样本集合内测试数据属性值取值的合理性。
2.3 孤值点甄别
数据集合一般包括了城域范围的测试数据,在空缺标记和界外指标处理后,在整体上从数据样式和取值范围角度保证了可靠性,但是就某个小颗粒度的区域(比如街道)来说,某样本的APowerlevel虽然已处在{minAPowerlevel,maxAPowerlevel}的合理取值范围内,同样不能保证其可信。在单频网建设中,1 kw功率的有效发射机覆盖半径是10 km左右,一般情况下对百米量级、物理遮蔽情况类似的区域来说,信号强度值比较平滑,因此,街道区域内,信号的APowerlevel值不应该出现跳变的孤值。实测中与邻近信号强度差别较大的样本出现,可能是由于设备故障造成的系统误差,即使并非误差,如采用对孤值敏感的测试评价算法就会对这一区域内的信号总体评估结果产生较大影响,因此,定义此类邻近区域内的孤值为异常值。
经分析,孤值点甄别的分析对象是小区域内的样本集合,因此需要对城域测试数据集合根据地理信息进行聚类。聚类需要确定方法、策略、距离度量算法以及聚类个数。对样本的聚类需要采用Q型聚类中的系统聚类方法,聚类策略采用类平均法(Between-groups Linkage),因为ALongtitude,ALatitude两个属性值无关,对于聚类同样重要,因此使用p=2时的Minkowski,也就是欧式距离DEuc来计算两样本间的距离
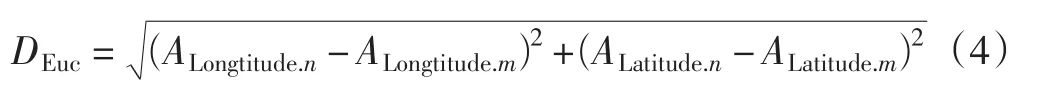
聚类个数需要根据城域数据总体的样本个数、路测仪器的记录间隔、路测车速等几个变量综合判断。
划分出小颗粒度的数据集合Ui后,可以看到Ui的数据趋势比较平滑,APowerlevel值接近,绝大部分单样本APowerlevel值xi与Ui的APowerlevel数据均值xˉ在一定范围内,此时Ui符合中心极限定理,样本APowerlevel值xi与xˉ之差绝对值在两个标准差之外的概率小于1%。因此,构建Z-统计量zi,以统计孤值点,具体为
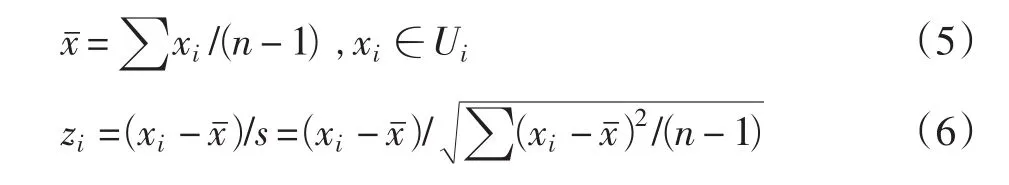
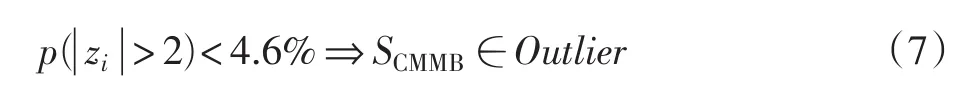
3 实例分析
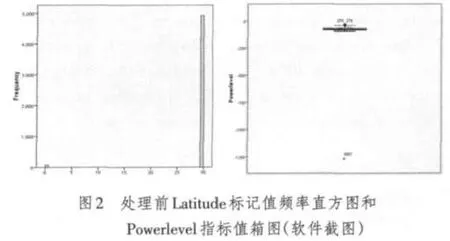
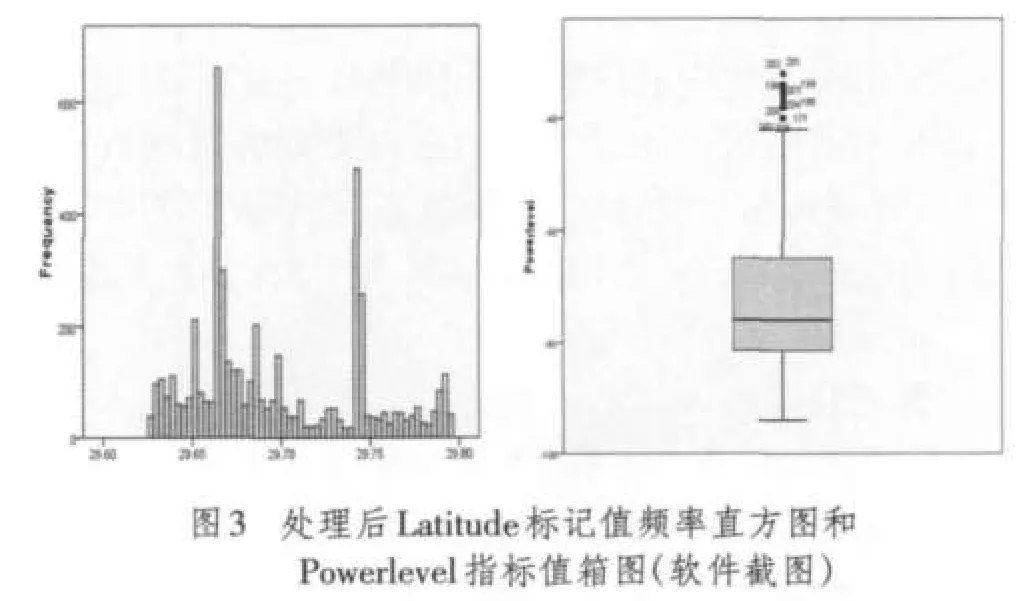
笔者参与了重庆部分区县的CMMB单频网覆盖测试,获得了大量的测试数据,对其进行异常值检测和处理。首先使用编写的程序合并某县的测试文件,然后按照提前预定义的规则将合并后的数据导入SPSS软件。经过探索性分析,由图2a可知,ALongtitude,ALatitude标记属性空缺的样本值占有一定比例;由图2b可知,APowerlevel指标属性存在较明显的界外值,综合原理分析和测试经验,APowerlevel取值范围应为(-100 dBm,-20 dBm)。使用SPSS经过空缺标记检测和界外指标处理之后,图3可看出样本总体的可靠性得到了保证。
综合分析覆盖测试中车速、间隔、样本总数3个因素后,聚类个数被设计为5。图4为样本集形成的5个聚类类别中各类的样本数目所占百分比。聚类作为一种探索性分析方法,没有明确的检验方法,但本方案中聚类情况与实际地理情况非常吻合,城域的整体样本基本按照距离邻近原则得到了有效划分。
之后对每类数据分别计算样本的Z-得分,并检测出孤值点。表1所示数据取自第二区域的邻近样本,其中Z-得分为2.231 9的APowerlevel值与邻近数值明显不同,跳变了大概10 dBm,以此方法可以直观地对孤值点进行甄别,以避免敏感值对评估结果的影响。

图4 聚类后各类样本所占比例饼图

表1 聚类后一段样本的Z-得分
4 小结
在分析CMMB信号覆盖和属性特征的基础上,笔者设计了一种结合聚类与统计学方法的检测方案。在实际案例上的应用中,既能提高处理效率,使数据分析人员能够摆脱以往依靠人工对异常值的检测,并且可以更加准确地甄别测试数据,从而保证了数据的可信度,有效地为网络优化和评估提供数据支撑。在数据准备中,还需要处理重复标记值,当然不属于异常值范畴,不在讨论范围之内。
[1]HAWKINS D M.Identification of outliers[M].[S.l.]:London Chapmanand Hall,1980.
[2]刘云霞.数据规约的统计方法研究及应用[D].厦门:厦门大学,2008.
[3]KNORR E M,RAYMOND T N,TUCAKLV V.Distance-based outliers:algorithms and applications[EB/OL].[2010-10-25].http://portal.acm.org/citation.cfm?id=764218.
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
科学与财富(2018年30期)2018-12-28 20:41:40
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子测试(2017年15期)2017-12-18 07:19:27
数学学习与研究(2017年3期)2017-03-09 18:12:42
计算机应用(2016年9期)2016-11-01 17:57:12
体育科技(2016年2期)2016-02-28 17:06:21
中国老区建设(2016年1期)2016-02-28 09:32:00
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
