
基于分布服务技术的个性化检索系统的研究
2011-01-03 03:42陈冬玲韩晓微
沈阳大学学报(自然科学版) 2011年2期
陈冬玲,韩晓微
(沈阳大学 信息工程学院,辽宁 沈阳 110044)
基于分布服务技术的个性化检索系统的研究
陈冬玲,韩晓微
(沈阳大学 信息工程学院,辽宁 沈阳 110044)
将Web Service技术与个性化技术相结合,提出了基于Web Service的个性化信息检索,并进行了系统设计及关键技术分析·
Web Service;个性化信息检索;分布式检索
随着网络技术的飞速发展,搜索引擎已经成为名副其实的信息枢纽和信息门户,是用户获取网络信息的首选工具[1]·然而,通用搜索引擎一般采用的是集中检索方式·它们试图遍历整个互联网,对所有的文档生成全文索引,供用户检索·这种检索方式在覆盖度低,且负载增大时,用户的查询请求很难得到及时的响应·鉴于此,人们提出了分布式信息检索,它是通过元搜索引擎来实现的,这种方式可充分利用各大搜索引擎的优点,虽然可以在最短时间内获取较全面准确的信息,但是这种检索方式受普通搜索引擎的限制,不能直接从网络上分布的各类数据库中检索信息,而只能从人工事先准备好的静态网页中进行检索,并且,元搜索引擎也无法同时向多个搜索引擎提交高级条件查询,较难获得较高的查准率[1]·这样,针对不同用户提供相应的个性化检索服务便无从可谈·面对如此窘境,人们试图在实现分布式检索的同时,实现个性化信息搜索·
由于Web Service技术具有完好的封装性并具有高度的可集成能力,同时,在分布式的网络结构中,P2P结构可以使用户发现任何形式的数据而备受人们的关注,并且,P2P与 Web Service在某种程度上具有互补的性能,所以,本文提出了将Web Service与P2P相结合的分布式信息检索系统,同时,在此检索系统中,使用概率潜在语义分析的个性化技术进行个性化搜索,最终形成一个分布的个性化的信息检索系统·
1 相关技术
1.1 Web Service
Web Service是目前Web上数据和信息集成的最完美的实现方式[2]·Web Service由3个参与者和3个基本操作构成·3个参与者分别是服务提供者、服务请求者和服务代理,3个基本操作分别为发布(publish)、查找(find)和绑定(bind)·在整个Web service框架实现中,使用了3个基本的协议:服务描述语言(WSDL[3]),简单对象访问协议(SOAP[4]),统一描述、发现及集成协议(UDDI[5])·
1.2 个性化信息检索技术
个性化信息检索的核心技术是用户兴趣(User Profile)的创建与学习,以及对所得的用户兴趣描述的应用(如过滤、推荐)·
(1)用户信息的收集,主要有显式相关性反馈和隐式相关性反馈·研究中,利用隐式相关性反馈来收集用户兴趣和兴趣跟踪成为研究热点·
(2)User Profile的存储和更新有两种存储方式,一种是将 User profile存储在客户端,优点是可以很好地保护用户的隐私,但缺点是用户往往不情愿做一些额外的工作来配合检索系统,并且,User Profile的更新比较困难·所以,本系统将用户兴趣跟踪与描述部分放在服务器端,并采用概率潜在语义分析技术对用户兴趣进行跟踪分析·
2 基于We b S e rvic e的分布式个性化信息检索
基于Web Service的分布式个性化信息检索,其基本思路就是将原来的个性化信息检索的各功能模块均包装成Web服务的形式,即用户兴趣描述文件的创建与更新是Web服务,负责分布式数据检索的是Web服务,检索结果返回并排序的是Web服务,客户端只需要布置一个Proxy即可,它负责向多个Web服务同时发出调用命令并接收返回结果·该检索模式的具体实现细节如下:用户输入查询关键词后,客户端程序先通过UDDI注册中心即查询到一批相关的Web服务·为了更好地实现个性化,也可事先根据User Profile查询一些相关的Web服务,固定显示在客户端程序中(或放在缓存中)让用户选择,经用户选择后,再自动读取相应的服务描述文件(WSDL文档)并进行分析,根据检索条件分别形成相应的SOAP消息请求,然后发送到相应的端口地址,调用这些Web服务;各个Web服务在各自的数据资源中执行检索任务,并将检索结果进行相应的个性化排序操作,以SOAP响应的形式返回调用它的客户端程序;客户端程序接收上述排序结果,并按某事先预定的方式显示给用户·然后根据用户的点击流数据进行User Profile学习和更新·
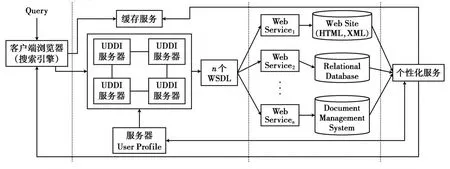
图1 基于Web Service的个性化分布式检索系统
图1为系统的层次结构,自左向右分别为查询提交层、服务查找层、信息检索层、个性化服务层·
(1)查询提交层·基于浏览器实现,其功能是实现用户接口,接受用户提出的查询请求,以及显示最终生成的个性化查询结果·
(2)服务查找层·接受用户提交的查询服务,结合User Profile找到满足查询条件并符合用户兴趣偏好的搜索服务及其相应的服务描述文件,为检索层工作作准备·
(3)信息检索层·根据服务查找层所提供的服务描述文件,利用不同的服务对地理上分布的、异构的数据源进行检索,将检索结果作为个性化服务层的数据输入·
(4)个性化服务层·为了满足个性化需求,该层对检索层所得的数据进行合并,并结合User Profile对结果进行排序,将排序后的结果返回给用户·
3 关键技术的实现
对于系统中的四个层次,查询提交层比较简单,其余的三个层次均是本系统的核心层次,实现基于Web服务的个性化信息检索,这三个层次均是至关重要的·按照自左向右的层次出现顺序,下面依次讨论其实现的关键技术·
3.1 分布式UDDI服务器的管理与遍历
当用户提交查询请求后,客户端 Proxy自动产生一个搜索服务,此服务负责查找与用户请求相匹配的检索服务·首先,为了加快查找速度,在本地服务器中缓存一些以前曾经访问过的服务,如果本地缓存中没有所需要的服务,则到UDDI中去查找其他注册的服务·由于面向Internet的UDDI存储在地理上分布的服务器上,对地理上分布的服务器管理有集中式管理和分布式管理两种方式,可以想象,如果采用集中式管理,那么众多查找UDDI的服务都会聚到同一个服务器上,必定产生“瓶颈”问题·相反,如果只采用分布式管理,那么又存在扩展性差的问题·所以,对分布式UDDI服务器,采用概念上的分级索引的方式进行管理·
由于网络上的各种信息可以按照ODP(Open Directory Project)方式进行分类,所以,用于访问网络信息资源的Web服务也可以按照这个方式进行分类,这一点为管理UDDI服务器提供了很大方便,具体做法如下:将UDDI服务器按照不同的领域,划分成不同的子服务器群,对于各子服务器群依照同样的做法进行划分,就如同ODP分类目录一样,越向上的服务器群结点,其概括性越强,越向下的服务器群结点,其具体性越强,但对于不同的子服务器群,其父结点是该子服务器群的索引,这样,就形成了一棵UDDI服务器群的索引树,见图2·如果到UDDI服务器群中查找符合某查询条件的服务,那么可以按照树的遍历进行逐步向下查找,就可以找到服务所在的UDDI服务器·

图2 服务注册的树型结构
3.2 在UDDI中进行个性化查找
由于目前UDDI只支持关键词和分类查找,所以,在语义上实现个性化查找似乎很难做到,本文中所实现的个性化,实质上是将UDDI服务注册与用户兴趣分开进行,即采用传统个性化搜索的方式进行,只是在搜索过程中,将用户提出的查询与用户兴趣描述文件(User Profile)进行匹配,在获取权值最高的N个关键词后,再到UDDI中查找相应的服务·并且,为了实现在UDDI中的查找与用户兴趣的一致性,User Profile也采用向量空间模型(VSM)加权方式进行存储,这样,就可以实现个性化的服务查找·
3.3 基于Web Service的数据集成
分布式检索过程中,实现大规模分布的、异构的各种数据的透明访问和集成是至关重要的·但由于网络上的数据来源多样,格式不一,没有统一的数据模型,所以,在Web Service框架下实现所有数据的访问及集成,必须为每一个数据源建立一个Web Service,然后使用WSDL向服务中心注册·当用户提出查询请求时,通过服务查找层,找到相应服务的描述文件,传送到信息检索层·
信息检索层的主要任务是进行相应物理位置上数据的访问与集成·利用Web Service屏蔽底层存储资源的异构性,为个性化服务层提供一个统一的数据视图·信息检索层在整个系统中的作用相当于一个系统访问网络数据的一个中间件,它的设计也同样采用层次结构,见图3·
图3中,自下而上分为三层,分别为:数据层,指各种分布的存储资源,如文件系统、数据库系统、文档及元信息库等;接口层,指各种面向具体存储资源的访问接口;服务层,管理多个数据源,进行统一访问管理提供的各种服务,包括安全服务、数据服务、全局命名服务、元数据服务·

图3 信息检索层结构
在服务层中,安全服务考虑的安全策略包括:用户登录系统需要身份的验证,并为该用户产生一个具有时限的用户代理证书;物理资源加入到系统中需要赋予身份,并产生一个代表其身份的资源代理证书;用户使用某个物理资源,双方必须交换证书进行相互认证;它们之间的通信也必须以加密机制来保证通信安全·数据服务主要提供数据的访问优化、调度和服务,管理分布异构存储资源上的数据为一体,提供数据的统一访问,基于XML的数据的集成·元数据服务为系统提供全局资源的信息服务,提供数据的定位和属性查找,数据的注册和发布,安全和授权信息及用户元信息的访问和管理,副本信息的管理和选择等·全局命名服务为系统提供一个全局统一的逻辑文件名·本文设计了三种命名空间,即逻辑文件名、物理文件名和系统内使用的文件名:①物理文件名(PFN,Physical File Name),即在文件实际存储系统上用来标明该文件的唯一标识符,在某个独立文件系统(如NTFS、exe2等)上为该文件的完整路径,在网络文件系统(如NFS、HPSS等)上为可对该文件进行访问的系统路径·②系统内部使用的文件名(SIFN,System Internal File Name),是在本系统内部使用的文件名称,每个SIFN唯一对应一个PFN·③逻辑文件名(LFN,Logical File Name),指面向用户,在用户的逻辑视图中所使用的文件名称,具有全局唯一性·
综合上述各层次功能,数据访问的具体过程为:首先,用户提出一个查询请求,交予搜索引擎,按照用户兴趣描述(User Profile)查找相应的服务描述文件,将服务描述文件传递给信息检索层·由于各功能均被包装成Web服务的形式,所以,即使是在服务查找过程中,服务关键词与 User Profile相匹配的过程也被包装成服务,一切功能的衔接均是通过SOAP消息进行的·其中,在信息检索层的具体操作步骤如下·
(1)在服务查找层找到服务描述文件以后,传递给Data Broker,它按照不同的服务描述文件找到相应的服务,这些服务分别负责相应物理存储位置上的数据的访问·
(2)为了能对不同物理位置上的数据进行访问,Data Broker向元信息库管理器产生一个查询,要求通过LFN得到该文件的URL(FTP协议),这个查询以SOAP envelope的形式传递到元信息库管理器·Data Broker查看此用户是否有权限执行此操作,如果没有权限,则此用户请求被拒绝;如果此用户有权限,则执行该请求·
(3)元信息库管理器从元数据目录中检索所有给定逻辑文件名的SFN,查询远程数据容器,看被分析的文件是否已经准备下载,来决定该文件的最优位置·
(4)在所有收集到的数据中,元信息库管理器决定从哪一个文件位置下载·
(5)元信息库管理器改变元数据目录中该文件的location state,对该文件加写锁,并且返回被选择的数据文件的URL·
(6)将数据库访问的ODBC包装成服务,对该数据源进行访问,得到XML格式的数据,这个结果被返回给Data Broker作为响应·
(7)Data Broker将该数据的模式存入元信息库,若需要与其他数据进行集成,则在元信息库中查找其他数据的模式信息,手工完成模式的映射·
(8)数据进行集成后,返回给用户,同时,将元信息库中该数据源的写锁释放·
3.4 个性化User Profile的构建与学习
User Profile是用户兴趣的描述文件,是用户个性化需要的体现,是个性化搜索的基础设施·通常,User Profile可以被理解为用户模型·构建User Profile时,本系统采用的方法是概率潜在的语义分析(PLSA)方法,应用PLSA进行文档分析时,p(di)表示某关键词出现在特定的文本di中时di出现的概率;p{wj|zk}为在潜在因素zk影响下,关键词wj的概率分布;p{zk|di}为文档di中潜在变量zk发生的后验概率·对文档进行分析时,通常分析联合分布p(di,wj),其实际意义是通过分析文档中共现词的分布来分析文档的语义,这个概率背后,隐藏着潜在的语义空间zk∈{z1,z2,…,zk}·计算时,联合分布可以展开为
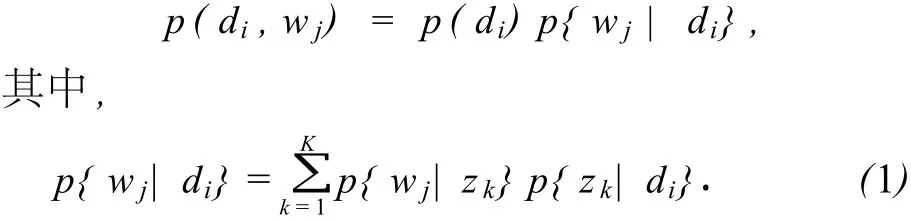
PLSA算法中,潜在变量估计使用的是期望最大算法 Expectation Maximum(EM)算法·EM算法交替进行E步和M步·其中,E步具体的计算如式(2)所示;M步骤中,使完备数据的对数似然函数取最大值,得到p{wj|zk},p{di|zk}·
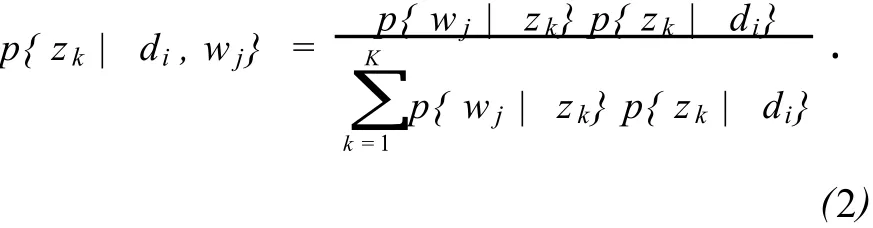
E步与M步迭代,最终可以得到相应文档的潜在语义空间zk·在此潜在语义空间中,按照概率值的大小,可以把语义分为共性与个性,概率值越大的潜在因素,其越具有共性;反之,概率值越小,个性越强·在此空间中,可以将用户兴趣进行相应的聚类,并按照聚类结果建立用户兴趣的User Profile·
所以,本系统中User Profile的结构采用向量空间模型(VSM)加权的方式进行存储,只是向量的关键字为相应的潜在空间的 Topic,即{(Topic1,w1),(Topic2,w2),…,(Topicn,wn)}·最初,User Profile采用注册的方式进行;然后,通过对用户所感兴趣的服务、网页及相应的数据的title关键词提取进行学习与更新·在User Profile中,可以采用斐波那耶数列进行兴趣衰减,当关键词几次未被访问后,其权值自动衰减;当权值低于一定阈值时,此关键词被删除;同理,当关键词被连续访问时,其权值将不断上升,实现兴趣的更新·
4 结 语
本文提出了分布式个性化检索的基于Web服务的实现方式,由于分布式检索覆盖广,数据量大,使得个性化需求尤为突出·本文所提出的基于概率潜在语义建立User profile的方法可以真正解决用户搜索的真正意图,找到其潜在的搜索主题,可以克服元搜索引擎只能进行简单查询的不足·同时,基于 Web Service与 P2P的结合,使得集中式注册与分布式管理相结合,可以充分克服Web Service分布式查找的困难及P2P管理的“瓶颈”问题·同时,一些分布式编程技术,如Ajax+J2EE等[6]的发展,也使分布式个性化检索成为可能,也是使个性化检索跨向成熟一步的关键所在·从发展的角度看,开放、分布式的个性化检索是大势所趋·
下一步的研究工作是将个性化搜索技术中的User Profile的构建与混合P2P的研究更进一步紧密结合,使用户模型与超级结点的选取相结合,提高资源查找的精确度·
[1] 刘婧,袁可,蒋伟.分布式检索中查询结果合并方法研究[J].情报学报,2009(5):685-688.
[2] Telang A,Chakravarthy S,Li C.Querying for information integration:How to go from an imprecise intent to a precise query?[C].International Conference on Management of Data(COMAD),2008:245-248.
[3] Christensen E,Curbera F.Web Service Description Language(WSDL)1.0[EB/OL].[2000-09].http:∥www.06.ibm.com/developer Works/web/library/w-wsd-1.html.
[4] Box D,Enhnebuske D.Simple Access ObjectProtocol(SOAP)(W3C Note 08 May 2000)[EB/OL].[2002-05-08].http:∥www.w3c.org/TR/SOAP.
[5] Clement L,Hately A,Riegen C V,etal.Universal description discovery&integration(UDDI)3.0.2.2004[EB/OL].http:∥uddi.org/pubs/uddi-v3.htm.
[6] 黎宇.Ajax+J2EE开发静态页的组织机构管理系统[J].电脑编程技巧与维护,2010(11):36-43.
Personalized Retrieval System Based on Distributed Services Technology
CHEN Dongling,HAN Xiaowei
(School of Information Science and Engineering,Shenyang University,Shenyang 110044,China)
Web service and personalized technologies are integrated;Web service based personalized information retrieval is proposed;and system design and key technology analysis are further proceeded.
Web service;personalized information retrieval;distributed retrieval
TP 391
A
2010-10-09
辽宁省博士启动基金资助项目(20101074)·
陈冬玲(1973-),女,吉林四平人,沈阳大学讲师,博士·
1008-9225(2011)02-0017-05
【责任编辑:刘乃义】
猜你喜欢
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
新闻传播(2016年18期)2016-07-19
专利代理(2016年1期)2016-05-17
现代计算机(2016年11期)2016-02-28
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
河南科技(2014年11期)2014-02-27
图书馆界(2013年5期)2013-03-11
质量与标准化(2010年5期)2010-05-03
