
本体驱动的数字图书馆信息资源语义互操作研究
2010-08-31 11:26:48鞠彦辉渤海大学信息科学与工程学院辽宁锦州121000
图书馆理论与实践 2010年1期
●鞠彦辉(渤海大学 信息科学与工程学院,辽宁 锦州 121000)
近年来,数字图书馆作为一个综合的研究领域在许多方面得到了很大的发展,然而在对于如何保证在分布式网络环境下,人们能够更准确地获得其所需要的信息方面并没有突破性的进展。“互操作”试图通过建立信息资源之间的互操作机制来解决这一问题。所谓数字图书馆互操作是指数字图书馆系统之间交换和共享数据的能力,具体分为结构互操作、语法互操作和语义互操作 (semantic interoperability)三种类型,[1]其中语义互操作作为一种高层的互操作理念,是数字图书馆信息服务的目的。以前人们提出的互操作技术由于缺乏可理解的语义和共享的形式化基础,异构信息资源间难以共享和互操作。目前在计算机异构应用系统集成、地理信息系统图形信息共享、电子商务管理、数字图书馆等领域,本体技术已成为建立领域共识、实现语义互操作的研究热点。因此,本文提出本体驱动的数字图书馆信息资源语义互操作解决方案,以解决分布式数字图书馆之间异构信息资源的语义互操作问题。
1 本体对数字图书馆信息资源语义互操作的驱动作用分析
本体的本质是通过概念模型对信息作完全的形式化描述,使计算机可以理解网上的信息,建立本体的目的是为了实现领域知识的共享与重用。本体对数字图书馆信息资源语义互操作的驱动作用包括:(1)本体是依靠人的智慧而创建的工程化产品,可在用户间或软件代理间达成对于信息组织结构的共同理解和认识。(2)提供与描述型元数据有关语义描述的知识地图。(3)在本体的帮助下可以实现独立于人工干预的信息互操作,在机器—机器的环境中,本体采用机器可读的方式进行领域概念的表示,这些特点可以用来构建自动化的信息处理机制。(4)本体是数字图书馆系统之间信息通信的中介。通过为不同的领域构建领域本体,然后再在这些领域本体之间建设上层本体,结合其他技术来实现这些系统间的互操作和通信。
2 本体驱动的数字图书馆异构信息资源语义互操作框架
通过上面的分析,本节构建一个本体驱动的数字图书馆信息资源语义互操作框架,主要包括三个部分:(1)数字图书馆各种类型信息资源本体的建立;(2)本体间的映射及合并;(3)语义互操作服务。如图1所示。
2.1 数字图书馆信息资源本体的建立
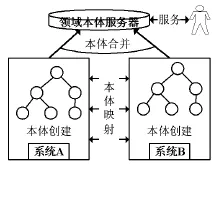
图1 本体驱动的数字图书馆信息资源语义互操作框架
数字图书馆信息资源类型多样,包括文本文献信息资源、多媒体信息资源及知识管理仓库等,因此,数字图书馆信息资源本体的构建包括以下三个层次:(1)基于本体的文本文献信息资源构建,其实质是建立文献之间的等级结构,并定义文献之间的关系。因为文本文献的等级关系在MARC上有较好的体现,所以在MARC数据的基础上构建本体具有较强的可行性和实用性。构建本体的最终目的是实现推理,利用文献的等级结构和定义的属性可以在转化后的MARC上实现推导文献间关系的目标。构建文本文献本体的最后一步是将推理的结果生成知识库。[2](2)基于本体的多媒体信息资源构建。针对多媒体信息所固有的异构性、多分布性、增长性和变化性等特点,语义方法是当前多媒体信息资源本体构建研究的重点。基于本体的语义网(Semantic Web)由于其分层结构的特点,可以满足不同用户群的需要,提供简单的分类方法和关系,附加层的表达性、功能性和复杂性可根据不同的用户需求增加,从而实现可扩展性和语言的表达性之间的平衡。(3)基于本体的知识管理知识库构建。数字图书馆的最终目标是实现对知识的管理。在知识管理的全过程中构建本体,可以实现对知识本身的揭示,实现数字图书馆中信息资源最高层次的构建。在知识管理的过程中构建本体主要由三项工作构成:① 获取知识,根据“知网”建立等级结构;② 按本体规则对知识进行描述、存储,以形成知识库;③ 在推理基础上提供知识的智能检索,以实现知识重用。[3]
2.2 数字图书馆信息资源本体间的映射
在网络环境下,数字图书馆信息资源之间的语义互操作实际上是实现信息资源本体间的映射。本体映射是解决不同本体间的知识共享和重用问题的主要技术,它是指在已生成的本体上建立语义级的概念关联,以便双方能使用通用接口,对同一事物有共同的理解。数字图书馆信息资源本体映射的一般过程为:(1)本体的输入。这里假设只输入描述同一或相似领域的两个不同本体O1和O2,它们可以用不同语言说明,为了能够准确映射,需要把它们转换为相同格式。(2)特征提取。提取用于计算相似度的特征,如概念、属性的名称等。(3)选择用于映射的概念对。(4)进行相似度计算。很多系统使用匹配操作器(半)自动地发现不同本体或模式间的相似度,如果映射过程完全是手动的,这一过程可以略过。相似度的计算是本体映射过程中一个至关重要的步骤,主要包括语义相似度的计算、描述相似度的计算、邻近层次概念相似度的计算等。(5)相似度整合。有多种方法用来衡量本体实体之间的相似度,得出多种相似度值,因此要对各相似度进行综合考虑,从而得到一个整体上的相似度。(6)优化。第(4)步结束后,已经得到待映射的各个实体之间的初始相似度,这时一般需要人工的干预,利用领域知识,对其进行调节。(7)迭代第(2)步到第(6)步,直到得到满意的结果。[4](8)输出映射后的本体。如图2所示。
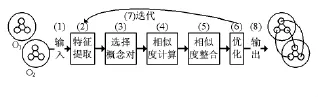
图2 数字图书馆信息资源本体映射的一般过程
目前有多种本体映射方法,按照本体定义模型进行分类,可以分为:(1)基于通用公共上层本体库的本体概念映射。领域本体库基于某个公共上层本体库(如DOLCE)为基础所构建,通过分析领域本体库与公共上层本体库之间的关系来计算本体概念之间的相似度。(2)基于本体概念相似度的本体映射。直接计算概念之间的相似度。其具体的计算方法有多种,如基于自然语言处理的计算方法、基于本体代数的方法等。(3)基于本体概念层次结构相似度的本体映射。以图论方法和本体语言的结构特点来进行相似度分析,如果两个概念的相邻节点(子概念、父概念)是相似的,那么它们的相似性程度增加。[5](4)基于(2)(3)两种方法的扩展映射方法,是这两种方法的加权综合,基于概念及概念的相关内容来综合加权计算概念间的相似度,从而最大限度地提高本体映射的质量。此外还有基于语义的方法、基于概念实例的方法、基于概念定义的方法等。由于数字图书馆信息资源类型多样,所以为了提高映射准确率,本体映射往往是若干方法的综合运用。经过本体间的映射,把数字图书馆系统A中信息资源的本体表达转换为等同语义的数字图书馆系统B中应用的本体表达,A的应用系统可以像处理其他系统内部信息一样处理B系统的信息。
2.3 数字图书馆信息资源语义互操作服务
完成了数字图书馆信息资源本体间的映射后,可以进行本体合并集成,构建领域本体服务器,领域本体服务器是进行信息互操作与集成的核心,是提供语义互操作服务的基础。基于本体的数字图书馆信息资源语义互操作服务的整个过程即信息资源的语义化分析、表达、集成与管理的工作。主要包括以下几方面内容:(1)用户请求分析处理服务。对用户的请求进行分析处理,使本体服务能够被正确地解析。(2)语义冲突消除服务。在领域本体服务器的支持下进行数字图书馆信息资源语义冲突的智能化识别和处理,消除语义冲突和语义分歧的问题。(3)智能推理服务。在已经建立的语义化信息或知识及相关算法的支持下,针对基于RDF(S)/XML与OWL及其扩展描述的信息资源或语义模型,进行数字图书馆信息资源聚类、分类和学习等算法研究;进行信息与知识本体模型的生成、重用、演化(采用软件演化和重用的方法)机制探索工作,并进行相应信息推理引擎的可重配置与重用技术,以及推理任务描述与分解技术研究。为了对语义Web中RDF(S)/XML与OWL及其扩展等元本体所描述的信息资源进行查询,可以在面向XML描述信息的类SQL语言基础上,扩展定义推理查询公式的描述原语,从而构成相应的语义查询机制。[6](4)信息分析处理服务。其任务是完成各种与信息有关的分析处理的服务。它不直接访问信息资源,侧重于向用户提供计算资源。它遵循一定的通信机制,提供一定的处理能力,一次服务可以有若干输入、输出。(5)信息获取与一致化服务。信息获取服务的主要任务是访问一个信息内容实例,并且把该内容以指定的中介格式反馈给用户。一致化服务是将信息获取服务得到的数据转换为统一的XML中介格式数据,即将异构数据同构化。[7]
3 结语
本文针对网络环境下人们较难准确地获取存储在分布式数字图书馆中的信息资源的问题,提出本体驱动的数字图书馆信息资源语义互操作方案,将信息资源互操作和共享的问题转化为本体间的映射问题,从而能有效解决数字图书馆异构信息资源互操作问题,为人们提供更好的信息服务。
[1]刘炜.语义互操作与Linked Data[EB/OL].[2008-12-23].http://www.lib.sjtu.edu.cn/adls/download/12-18/1218AM-C2.pdf.
[2]李培,孙琳.数字图书馆信息资源本体论的构建[J].图书情报工作,2003(6):25.
[3]张敏勤.基于本体的数字图书馆信息资源构建[J].大学图书馆学报,2007(3):44-45.
[4]MarcEhrig,SteffenStaab.QOM-QuickOntologyMapping[C]//ISWC2004,LNCS3298:686.
[5]潘玉娥,等.基于分类的本体映射方法及映射工具实现[J].计算机应用研究,2007,24(10):214.
[6]张维明.语义信息模型及应用[M].北京:电子工业出版社,2003.
[7]杨昆,等.基于本体(Ontology)的空间信息互操作与集成方法研究[J].云南地理环境研究,2006,18(3):23.
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
现代装饰(2022年1期)2022-04-19 13:47:32
中国音乐学(2020年4期)2020-12-25 02:58:06
开放教育研究(2020年2期)2020-03-31 01:54:14
现代装饰(2020年2期)2020-03-03 13:37:44
中学生数理化·高一版(2018年9期)2018-10-09 06:46:48
中学生数理化·高一版(2017年9期)2017-12-19 12:15:14
现代语文(2016年21期)2016-05-25 13:13:44
文学教育(2016年27期)2016-02-28 02:35:15
大连民族大学学报(2015年2期)2015-02-27 08:28:11
