
软件缺陷检查单的动态生成方法
2010-08-14 01:20陈平黄茂生
电子产品可靠性与环境试验 2010年1期
陈平,黄茂生
(工业和信息化部电子第五研究所,广东 广州 510610)
1 引言
随着我国软件产业的大发展,软件测试机构迅速增多。但新兴机构的测试经验不足,导致测试机构的测试水平低下,难以整体提高。如何高效收集并传承工程经验,如何将项目经验和成果延续不断地传递给后来者的问题就变得越来越重要。
在实际工程的应用中,往往会利用制定标准缺陷检查单的方法来解决这个问题,要求测试人员严格按照缺陷检查单上的内容测试对象软件。但现有预制定的缺陷检查单往往也是根据固定模版及小范围内测试人员的累积经验补充完成的,即跟单位内(小组内)测试人员已做过的项目和发现缺陷的类型有关,单一针对性、依赖性较强;而且固定模版还可能长期不变,或通用性较强,不能够适用于发现多变、复杂的具体工程中的各种缺陷,存在一定的局限性,不便于大范围推广。同时在一些人员变动较频繁的测试单位中,一个经验丰富的测试人员的离开,首先就意味着后续测试过程中可能发现的缺陷的种类、数量和深度的大幅下降,俨然形成了某种测试领域的危机。
2 缺陷检查单动态生成方法原理
首先测试组对外的主要沟通渠道就是问题报告单,其中一个标准的问题报告单应包括缺陷的名称、类型、现象描述、实际输出概述和缺陷等级等属性。对应的缺陷检查单应当也包含缺陷的名称、类型、现象描述、可能输出分析和建议缺陷等级等属性。
我们应当针对缺陷单所应该包含的属性来着手收集、整理缺陷源数据,组织经验丰富人员召开专项会议,分析项目工程中可能存在的缺陷及其属性数据。在建立缺陷源数据库的初始阶段,甚至可以直接收集、整理原有项目中的问题报告单,分析提取出上述各属性数据,同时对每一个入库的缺陷进行标注,对缺陷发生的背景条件及可能出现的概率进行说明,然后存入缺陷源数据库,并在缺陷源数据库中进行结构排列和分类。在进行软件测试时,再根据项目条件利用缺陷源数据库中的对应数据,动态生成缺陷检查单。
3 基于Access的缺陷检查单动态生成方法
3.1 总体思路
针对缺陷属性数据生成的缺陷源数据库,就是将所有的缺陷类型及其名称、定义、建议缺陷等级、预估计出现概率和可能输出分析聚在一起的大集合。它是生成缺陷检查单的必要辅助工具,是通过对测试人员实践工作的总结,将各种可能或已发现的缺陷信息经必要的分析、处理后,并进行统计、汇总所组成的数据库系统。它使得测试经验以数据形式进行传递,同时为新项目建立合理、规范的缺陷检查单提供了有效的统计学数据。
3.2 基于树形表结构的缺陷源数据库表设计
首先缺陷源数据库的基础是由一个简单的Ac cess数据库及若干个表结构构成。其中主要的表结构如表1-4所示:

表1 “缺陷表第一层”数据库字段属性表
可输入内容:文档缺陷、代码缺陷、软件程序缺陷等抽象层面具有概括性、种类性的缺陷类型,其中 “本层类别”为主键。

表2 “缺陷表第二层”数据库字段属性表
可输入内容:文档内容不一致、软件异常退出等具体层面中具有总结性、概括性的缺陷类型,其中外键 “上层类别”为上一层缺陷表中的 “本层类别”,设定 “本层类别+上层类别”为主键。

表3 “缺陷陷表第三层”数据库字段属性表
可输入内容:用户手册与需求不一致、数组下标越界等具体层面中具有详细性、针对性的缺陷类型,其中外键 “上层类别”为上一层缺陷表中的“本层类别”,设定“本层类别+上层类别”为主键。

表4 “缺陷表第四层”数据库字段属性表
可输入内容:用户手册与需求中关于软件运行环境要求不一致等在具体层面中具有详细性、针对性的缺陷类型之上的变种或推进的缺陷类型,一般根据具体项目中要求详细描述缺陷类型时添加,其中外键 “上层类别”为上一层缺陷表中的 “本层类别”,设定 “本层类别+上层类别”为主键。
其总体组织结构如图1所示。

图1 缺陷库结构图
可根据实际项目的需要适当地增加缺陷表层数。由于表中结构只是向上一级追朔,即建立了一个树形结构,每一层新增节点只需和上一级节点建立强联系。因此很容易在原有的数据库基础上扩充新一层分支,同时无需要求每一层缺陷类型之间的级别程度完全一致,每一个新增叶子只需对上一级节点增加一个更小的子节点。
3.3 缺陷源数据库表实现
根据上述设计方法,以及数据库表结构关系,即可利用Access数据库,进行表的生成与关联,其中表实现如图2所示,表关系如图3所示。将分析、标注后的缺陷源数据灌入缺陷源数据库后即可完成动态生成缺陷检查单的所有准备工作。

图2 Access数据库中缺陷源数据库表结构

图3 Access数据库中缺陷源数据库表关系
3.4 缺陷检查单的动态实现
当缺陷源数据库被完整地建立以后,即可利用其动态生成缺陷检查单了。首先,缺陷源数据库中的缺陷信息包括了缺陷类型及其名称、定义、建议缺陷等级、预估计出现概率和可能输出分析等属性,而缺陷检查单则需要缺陷的名称、种类、定义、可能输出分析、建议缺陷等级等属性数据。因而可以综合分析当前被测软件的实际种类和预估计情况,对比缺陷源数据库中记录的缺陷源属性数据,选取合适的缺陷类型,进而形成缺陷检查单,其中在选取缺陷类型时应首先考虑提取对应最佳的叶子结点缺陷源数据,然后再向上一级进行追溯,增加同一父节点下的所有其它叶子节点,进而形成有层次结构、覆盖全面的检查单源数据。最后结合软件需求及对应语言编码规范的实际要求,整理获取最终的缺陷检查单如表5所示。

表5 缺陷检查单模式
4 缺陷检查单的数据分析与应用实践
4.1 缺陷检查单的缺陷信息源数据量分析及其更新策略
如下可以简单地分析得到缺陷检查单对应缺陷源数据库中的缺陷信息源数据量变化情况,如图4、5所示。

图4 预测数据库内缺陷信息源总数据量分析曲线
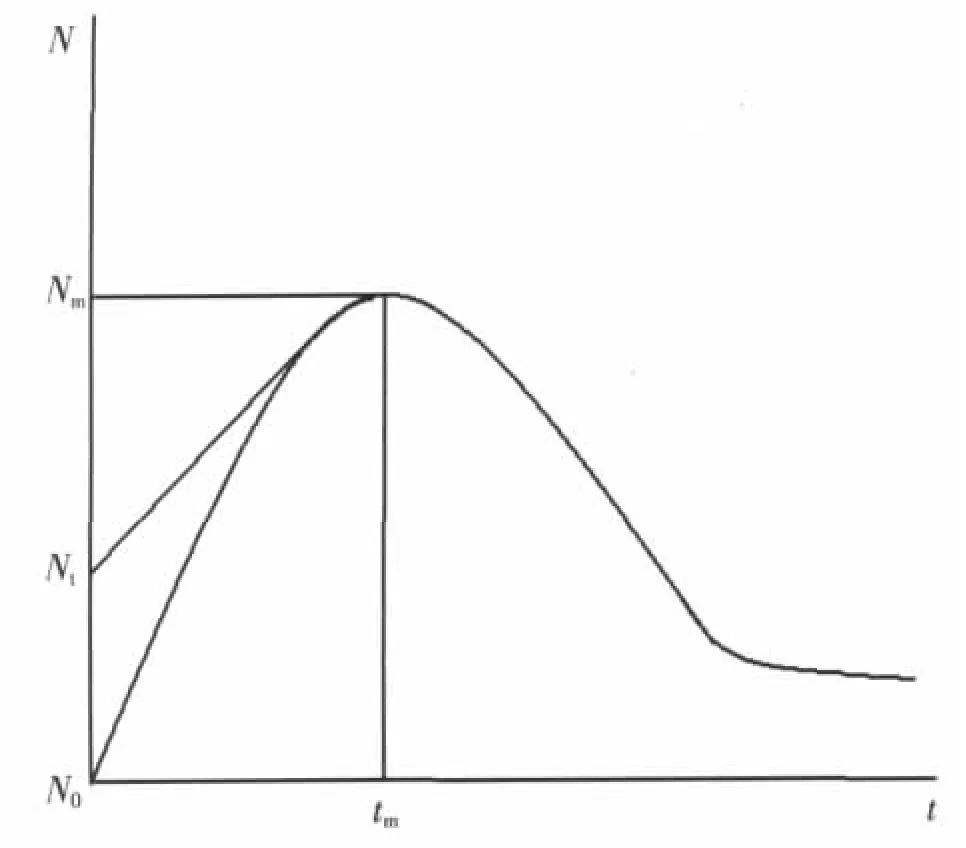
图5 预测数据库内新增缺陷信息源数据量分析曲线
此分析曲线适合以无任何基础的N0个开始入库,或从已有的初步统计缺陷类型Nt入手,建立数据库。分析曲线符合正态分布原理,计划在tm时刻能新发现及确定的缺陷类型数量达到峰值Nm,发现总数超过Nmx,此后由于库内存储的数据趋于成熟、丰富,新入库数据的增长率将会明显地下降,总数量将趋于稳定,但仍会有新增以适应新的缺陷类型。
在上述过程中,Nt值是通过大量总结原有或现用的缺陷检查单、缺陷报告类型列表及现有工程人员的经验而获得的。
建成后的数据库缺陷信息源更新即可以在测试项目组内或测试单位内进行定期汇总、整理当前的库内缺陷数据,再以标准库形式进行发布;其中测试项目组内的数据可按月或季度进行更新,测试单位内的数据可按1~3年为周期进行更新;也可以在测试单位和测试项目组中分工进行,测试单位只针对第一、二、三层缺陷类型进行定义,测试项目组可在其基础上针对具体情况进行扩充,两者数据以单季度或半年为周期进行同步更新。
4.2 缺陷源数据库的数据维护与缺陷检查单的动态生成实例
在日常收集缺陷的过程中,测试人员发现 “新缺陷”时,应首先根据异常现象(缺陷)对缺陷源数据库的所有叶子节点进行查找,当发现完全相符或近似的缺陷节点时,应将现有缺陷的实际输出和现象描述与已记录的缺陷节点的现象描述和预估输出分析进行对比,确定该异常现象(缺陷)的名称、种类、定义、出现原因概述和缺陷等级等属性并划归对应类型,覆盖或添加相应缺陷数据的现象描述和预估输出分析等信息。
当新缺陷在缺陷源数据库的所有叶子节点中无法被精确定位时,应遵循优先在可被概括的父节点下建立新子叶子节点的原则来生成子缺陷类型。当新缺陷在现有的缺陷源数据库中无法查找到任何相符或近似的父节点或叶子节点时,才考虑新增根节点的叶子节点。
同时,应该对整个查找分析过程进行必要的监督和评审,即对确定异常现象(缺陷)属性的过程进行监督,对新增缺陷类型及其定义、建议缺陷等级、预估计出现概率和预估计输出分析等属性进行评审。并对已确定的异常现象(缺陷)的出现情况和此缺陷占本项目整个发现缺陷比例情况进行必要的分析和统计,作为实际数据参数存于数据库中,以缺陷项唯一序列号进行区分——缺陷类别(本层缺陷类别)。其中缺陷库的收集过程及缺陷检查单的生成过程如图6所示。

图6 缺陷库的收集过程及缺陷检查单的生成过程设定图
表6介绍了一个简单的缺陷库生成的数据存储实例,其中所有的缺陷类型均达到了第三层,那么收集第三层数据,即可生成各缺陷检查单,如表7所示。
在软件测试各主要过程(包括文档审查、代码审查、动态测试、工作产品组内互审、工作产品专家审查及项目组人力资源管理等)中,即可利用相应生成的缺陷检查单,高效地进行相关测试或考核工作,并根据检查单结果生成问题报告。

表6 缺陷库数据存储实例
5 结束语
大量收集目标缺陷信息及缺陷发生的背景条件,并以此为基础构建缺陷信息数据库,分析挖掘已有缺陷数据中的有用信息,进而指导软件测试工作,对于提高缺陷发现率和改善软件的质量有着重要意义,必须进行全面、详实的记录。而文中介绍的动态生成方法,只要计算机上安装有Access数据库,即可根据缺陷检查单的基本原理并联系工作实际来建立缺陷源数据库,并在测试项目组或测试单位内简单、方便地生成所需的缺陷检查单。同时,建立完整的缺陷检查单及其对应的缺陷源数据库有利于为各个测试项目组建立相应的标准化机制,统一缺陷名称、适用范围及缺陷等级情况。并有益于测试单位内实践经验的有效传递,测试新手在学习测试方法时,可通过了解前辈建立的缺陷源数据库,更好、更快地适应新的工作岗位。项目管理人员也可以通过对缺陷信息源进行数据统计分析,建立更加合适的、有具体项目条件的缺陷检查单,并对被发现的概率及出现前提进行分析、预测,合理地调配人员,尽可能早地发现缺陷,更好地完成软件测试工作。

表7 缺陷检查单实例
[1]MYERS G J.计算机软件测试技巧[M].周芝英,译.北京:清华大学出版社,1985.
[2]PERRY W E.软件测试的有效方法(原书第二版[M].兰雨晴,译.北京:机械工业出版社,2004.
[3]PATTON R.软件测试[M].周予滨,译.北京:机械工业出版社,2002.
[4]黄茂生.分析测试过程故障数据,提高测试缺陷发现率[J].电子产品可靠性与环境试验,2003,21(4):33-35.
[5]王强.基于缺陷分类的软件缺陷分析方法[J].软件可靠性与测评技术,2005,(12):165-168.
[6]张晓鹏.用于软件行业的数据挖掘[J].计算机工程2003,29(12): 179-181.
[7]杨捷,李欢.软件可靠性工程中的数据挖掘及其应用[J].世界标准化与质量管理,2004,(11):52-55.
[8]梁成才,章代雨,林海静.软件缺陷的综合研究[J].计算机工程,2006,32(19):88-90.
猜你喜欢
计算机教育(2020年5期)2020-07-24
软件(2020年3期)2020-04-20
语文建设·下半月(2019年5期)2019-10-08
电子制作(2018年16期)2018-09-26
民族古籍研究(2018年1期)2018-05-21
特别文摘(2017年15期)2017-11-14
科技视界(2017年9期)2017-09-04
科技视界(2017年7期)2017-07-26
中央民族大学学报(自然科学版)(2016年1期)2016-06-27
新校长(2016年8期)2016-01-10
