
基于条件随机场的分词工作流研究与应用
2010-06-13 11:32乔长兵
微处理机 2010年3期
乔长兵
(江苏省邮电规划设计院有限责任公司,南京210006)
1 引言
在中文信息处理中进行一些相关的研究,比如信息抽取,指代消解等,首要进行的工作就是分词。而分词过程又是非常耗时的,执行时间过长导致效率低下。
利用条件随机场(Conditional Random Field:CRF)[1]模型来进行分词处理是最近研究的热点。它没有马尔可夫模型那样严格的独立假设,同时克服了最大熵马尔可夫模型的标记偏置的缺点;但却存在训练速度比较慢的缺点。
为了更加方便的进行分词研究和自然语言处理,提高分词处理的执行效率,作者将工作流引入到具体的分词处理中,设计实现了基于CRF模型的分词工作流。通过将分词流程分解成若干个执行过程,并将这些执行过程包装成网格服务,最终将服务部署到网格中的资源节点上。
2 CRF分词处理流程分析
条件随机场是一种条件概率模型,它定义了整个标签序列的联合概率,而不是为每一个状态都规定一个概率分布,各状态是非独立的,彼此之间可以交互,因此可以更好的模拟现实世界的数据。
为了便于构建CRF模型,首先必须使用一个标准化过程,将原始语料转换成标准的形式。这里使用的标准语料形式规定语料库中每行只包含一个字,与这个字相关的信息用制表符间隔依次标在字的后面。其次再进行特征提取,使之生成CRF模型工具所能识别的训练语料和测试语料,其格式为:每行包括一个字以及与字相关的一些特征和标记,字与特征之间、特征与特征之间与特征与标记之间都用制表符间隔开。然后对训练语料进行训练,训练生成一个CRF模型,其训练过程中加入了一些如迭代次数等的训练参数。利用训练所生成的CRF模型,对测试语料进行测试,获得一个预测结果。
根据上面的分析,可以得出基于CRF模型的分词处理流程图。如图1所示。分词处理大约由四个步骤组成,每个步骤具体描述如下:
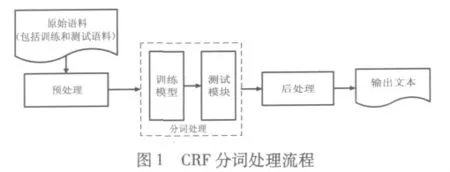
预处理主要负责的工作有:将原始语料文本的编码方式统一转换成GBK编码;加入特征并使之生成特定格式的文本文件,作为整个处理流程的中间文件;然后标准化该中间文件,使得CRF模型识别,即生成Train.tagged作为训练语料,Test.tagged作为测试语料。
训练模型:即CRF模型,它接收预处理生成的训练语料文件Train.tagged文件以及系统的参数文件option.txt。Train.tagged文件的大小一般有几十到几百兆,造成执行时间特别长,一般需要几个小时的时间,效率非常低,option.txt参数文件为CRF模型提供相关的参数信息,用来决定迭代次数,迭代次数越多,执行时间也越长。训练之后会生成相应的Model文件。
测试模型:它接收测试文件Test.tagged、系统参数文件option.txt和训练模型生成的Model文件。处理之后生成相应的初步分词结果。
后处理:它负责将经过CRF模型处理的初步分词结果进行筛选,筛选的过程就是根据自己定义的特征将一些明显不符合特征的分词结果去除,使分词结果更加合理。经过后处理过程,将获得最终的分词结果。
3 CRF分词工作流的设计与实现
3.1 CRF分词工作流的描述
借助参考文献[2]提出的一种可扩展的网格服务工作流语言——GSWL(Grid Service Workflow Language),描述CRF分词工作流,借助强大的标签功能来描述各成员服务之间的数据依赖关系和控制依赖关系。具体的描述文档片段如下所示。
<!--定义工作流的名字-->
<definitions name="GSWLforSegWord"scope="session">
<!--列出工作流的服务提供者列表 -->
<serviceProvider name="PreTxt"type="PreService"/>
<serviceProvider name="CRFTrain"type="CRFTrainService"/>
<serviceProvider name="CRF"type="CRFService"/>
<serviceProvider name="Opt"type="OptService"/>
<!--列出工作流中包含的活动 -->
……
<!--数据流模型 -->
<dataModel dataInTo="OutputDataA"dataOut-From="OutputDataD">
……
</dataModel>
……
一方面,训练模型中用到的算法时间复杂度高,随着迭代次数和特征数目的增加,执行时间也相应增加;另一方面,训练模型需要处理几百兆的数据信息,执行时间将变得十分漫长。同样的,测试模块和后处理模块都需要处理大型的数据文件。
数据流模型中 <dataLink label=”link1”>和<dataLink label=”link2”>的Self_Sched属性设定为true。因此,在调度执行 CRFTrainServie服务和CRFService服务时要执行GSPSS算法,将大的文本文件分解成若干个小的文本文件,并协调网格中所有可用的功能相同的服务资源来并行执行。
3.2 CRF分词工作流的设计
根据上面的分析,将分词处理过程描述成一个网格服务工作流应用。CRF分词工作流的设计如图2所示。

图2 分词工作流设计图
其中,PreService服务对应于流程中的预处理过程,CRFTrainServie服务对应于训练模型,CRFSer-vice服务则对应测试模型,获得基于CRF模型的粗分词结果;OptService服务对应流程中的后处理过程,对前面获取的分词结果进行一定的筛选和优化,获得最终的分词结果。
3.3 工作流成员服务的实现
在具体实现服务的过程中,使用的开发工具是Magic C++.NET+Eclipse+GT4软件开发包。算法实现使用C++作为编程语言,服务封装使用Java编程语言。集成开发环境Magic C++.NET支持远程基于Unix/Linux/BSD服务器的开发以及本地基于Windows的开发,通过它就可以获得Linux和Windows下的可执行命令或程序;借助Eclipse+GT4软件包将命令和程序封装成网格服务,并最终利用GT4提供的命令将网格服务部署在各个网格节点上。下面以PreService服务为例来说明具体的实现过程。
在Magic C++.NET中,新建工程Preprocess,建立Preprocess.cpp文件,给出该文件的代码片段,如下所示:
……
//特征化文本
void replace(char*r,char*w)
{
……
}
//转换成GBK字符编码
void convert(char*r,char*w)
{
……
}
fclose(rf);
fclose(wf);
}
……
void main()
{
……
}
代码片段给出了函数convert(char*r,char*w)和函数replace(char*r,char*w)实现的部分代码,前者用来将原始语料文本的编码方式统一转换成GBK编码,后者用来标准化加入特征后的中间文件。
为了使程序既能在Linux上执行,又能在Windows上执行,通过Magic C++.NET可以很方便的在Linux上生成可执行的 shell命令:../usr/seg/Preprocess,在 Windows 平台上生成 Preprocess.exe作为可执行文件。
算法实现之后,下一步就是利用Java和GT4提供的API来封装成网格服务PreService。在Eclipse新建一个GT4工程PreService,实现的关键代码如下所示。
package org.zhhz.gt4.example.impl;
……
import org.globus.wsrf.ResourcePropertySet;
importorg.globus.wsrf.impl.SimpleResourcePropertySet;
……
public class PreService implements Resource,ResourceProperties{
……
/* Constructor.Initializes RPs*/
public PreService()throws RemoteException{
this.propSet=new SimpleResourcePropertySet
(PreServiceQNames.RESOURCE_PROPERTIES);
……
}
……
//判断操作系统的类别
private boolean checkosversion(){
……
}
//进行预处理
public TxtnameResponse preservice(Txtname tname){
}
return null;
}
……
}
4 实验分析
实验搭建的网格环境为:1个主机作为调度节点,12个性能不同的主机作为资源节点,并且每个节点上都部署了PreService服务、CRFTrainServie服务、CRFService服务和OptSevice服务。其中8个资源节点的性能列表见表1,其他4个节点的操作系统是Linux,CPU 频率为3.0GHz,内存大小是512兆。
分词处理采用的语料有两个,一个是PKU训练语料和测试语料,该语料来自北京大学语料库,其规模为110万词,编码方式采用国标码,语料库内容主要来源于报纸新闻,其语料格式由被空格标记的词组成的句子段落构成。另一个语料是SIGHAN的MSRA语料,该语料同样采用国标码编码,且语料格式跟PKU一样,但语料库相对大一些。因为分词处理执行效率比较低,在实验过程中通常利用高性能的集群环境来处理。
为了证明调度模型的有效性和实用性。作者对分词处理程序在集群环境中的运行时间与分词处理工作流在网格中的执行时间进行了比较分析,如图3所示。

表1 资源节点性能表
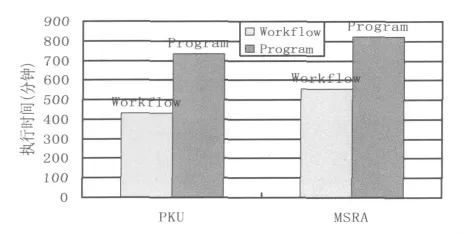
图3 分词处理程序执行时间与分词工作流执行时间比较图
从图3可以看出,分词处理程序处理MSRA语料的执行时间略高于处理PKU语料的时间。分词处理程序的执行时间比分词工作流的执行时间高很多,工作流的引入,大大提高了分词应用的执行效率;另一方面执行时间并没有因为多个节点并行执行而成倍的缩短。
5 结束语
通过结合分词的应用,作者针对基于条件随机场分词程序训练速度比较慢的缺点,通过在分词处理应用中引入工作流机制,提出了基于条件随机场的分词工作模型。最后实验结果表明,该模型能有效地提高分词处理的执行效率,分词工作流的执行时间远低于分词处理程序的执行时间。
[1]Lafferty J,McCallum A,Pereira F.Conditional random fields:probabilistic models for segmenting and labeling sequence data[A].Processing of the International Conference on Machine Learning(ICML -2001)[C].Williams MA,2001:282 -289.
[2]郭文彩.面向服务的网格工作流关键技术研究[D].北京:北京科技大学,2005.
[3]XueNW.Chinese word segmentation as character tagging[J].Computational Linguistics and Chinese Language Processing,2003,8(1):29 -48.
[4]John Lafferty,Andrew McCallum,Fernando Pereira.Conditional random fields:Probabilistic models for segmenting and labeling sequence data[C].Proc of ICML,2001:282-289.
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
校园英语·月末(2021年13期)2021-03-15
数学年刊A辑(中文版)(2019年3期)2019-10-08
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
北京航空航天大学学报(2017年6期)2017-11-23
海外华文教育(2016年1期)2017-01-20
浙江大学学报(工学版)(2016年10期)2016-06-05
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
