
基于分类回归树模型的商业网站营业数据分析与探讨
2010-04-16 09:15武峰
电脑与电信 2010年6期
武峰
(广州大学华软软件学院,广东广州510990)
1.引言
我国的电子商务近年来飞速发展,尤其基于网络的电子交易越来越普及,典型的C2C模式的淘宝网交易金额2009年上半年已经达到1000亿,每天的浏览量超过900万人次,注册淘宝网的用户数目前已经达到7200万[1]。这样一个庞大的购物群必然蕴含着无限商机。
分类和回归树(CART Classification and Regression Trees)技术是一种用于数据集分类决策树技术,也可称为二元回归分解技术[2]。它的输入量可以是连续特征和离散特征的变量,变量之间可以是模拟非线性的关系。利用分类回归树可以自动探测出高度复杂数据的潜在结构、重要模式和关系;探测出的知识又可用来构造精确和可靠的预测模型,应用于分类客户、保险诈骗和信用风险管理等。本文主要从网络商家的角度研究商家店铺信誉、商品价位、所在地域等,从而探讨其与商品销售量的关联度及哪一些因子是影响网络营销中的关键因子。
2.建立模型
本文应用SPSS公司的商业智能分析软件Clementine构建分类回归树模型,对C2C模式的淘宝家饰精品类的网站店铺半年营业数据进行分析建模。
2.1 数据采集
利用Topfisher工具软件将某网站的交易记录采集到指定数据库中,难点是对超链接网页中的重要属性及信息的选择和自动存取的过程。这需要亲自编写脚本工具程序实现,最后的采集结果见表1。

表1 利用Topfisher工具从网上精品店采集到的销售原始记录
2.2 数据预处理
对原始数据进行筛选、分类合并、汇总及数据格式的转换等。目的是为了让数据挖掘软件Clementine中的CART算法建立模式更准确。
2.2.1 数据准备
数据挖掘最后成功与否,是否能够起到决策支持作用,关键在于数据预处理。由于在ACCESS数据库中对数据筛选排序等方面操作复杂,而SPSS的Clementine软件对Excel数据的导入有更好的支持,所以将数据导出到Excel数据表中,在数据导入SPSS的Clementine之前,可以先人工对变量进行初步处理,删除一些明显不必要的变量以及在数据采集过程中某些不完整的记录,这样有助于提高模型的运行效率及结果的精确度[3]。
根据研究目标,进一步分析成交记录中哪一些价位的网络商品在家饰精品类属于热销品或对于同样的商品哪一些因素是影响成交量的主要因子。本文对销售记录中的一些属性以及商家的有关属性进行汇总整理出数值属性表,如表2所示。采用分类汇总的方法将各自店铺不同价位商品按一个价位划分标准进行分级量化,表3定义了商品单价划分层次,将价格统一化,容易比较与归类。
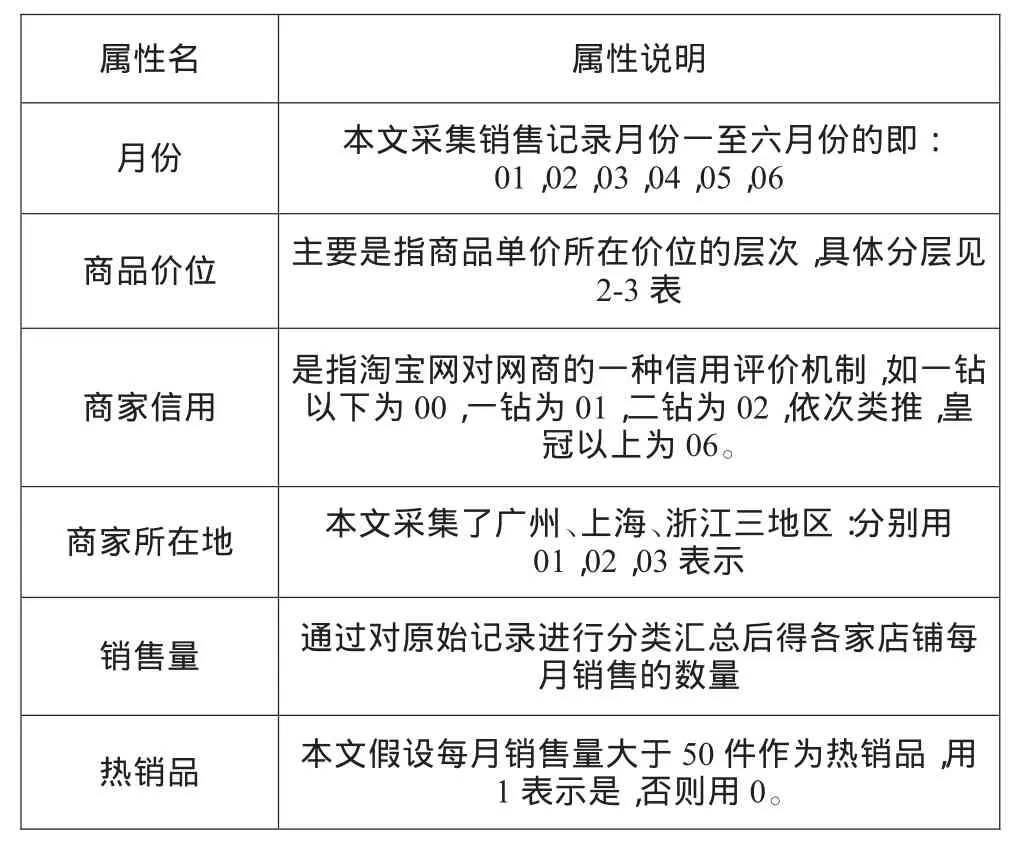
表2 分类汇总之后的数据属性表

表3 商品单价划分层次定义
2.2.2 数据转换
作为数据预处理的重要部分,数据转换是应用简单的数学公式或学习曲线变换度量方法,将数据转换到一个统一的度量范围内,达到数据分析的目的。在进行分类回归建模时,输入的变量既可以是连续变量,又可以是分类变量,但本文研究的是分类决策树的问题,所以输出变量为分类变量,所以要将输出的每月销售量这个连续变量转变为分类变量。根据网络家饰精口的销售经验平均量对每种价位层次的商品数量进行定义:每月销售量大于50件的为热销品,少于50件的定义为非热卖品,这样可以将连续型数据转化为分类型数据。另外,还要将文本型的商家所在地转化为数值类型数据,从而提高模型的运行效率。图1是数据转换后在Clementine软件的属性类型节点定义。
2.3 建模
主要采用分类回归树CART算法建立数据模型,参数设置中基于树生长的“基尼系数”(GINI)[4],后剪枝策略,评估方面采用K-折交叉验证的方法来优化树,设置最大生长深度为5层,且叶子节点中的对象个数少于总对象个数的1%,父节点中的对象个数少于总对象个数的2%。建模的过程如图2。

图1 C l e m e n t i n e软件建模所用数据类型

图2 CART算法模型建立图
3.模型运行结果及分析
3.1 CART算法模型运行结果
通过对240条汇总的数据记录(既作为训练集又作为预测集)进行分析建模,运行结果如图3:

图3 基于CART算法模型结果树型图及IF-THEN规则图
从CART算法的树状模型结果图可以清晰看到整个模型的大致结构,整个模型有5个叶节点,总共有11个节点,从根节点向下一共有四层,即此树模型的的深度为4,根节点以及每个内部节点下面都标明了进行分支的依据变量及其阈值,且每个节点都标明了此节点所包含热销品与非热销品的每月销售量大于50件的个数和这些个数占总个数的百分比,以及此节点总的个数和占总数的百分比。从CART算法模型运行的IF-THEN规则图中发现共生成六条规则,其中规则用于0的包含4条规则,即用于非热销品的规则;用于1的包含2条规则,即用于是热销品的规则。从根节点到叶节点的每条路径都对应着一条(IF-THEN)语句规则,IF后指代的是影响销售商品的一些特征属性,例如有商品价位、商家信誉、销售月份,THEN表示预测出该价位商品是否为热销品。
3.2 CART算法模型运行结果分析
大部分的分支都是非热销品的规则,只有两条是我们想要预测的热销商品的规则。第一条是:假如商品价位在低于200元情况下,商家信用是四钻等级,且在2,3,4,5月份所卖低于10元的商品则会成为热销品。第二条是:如果商品价位在低于200元情况下,商家信用是五钻以上等级,且所卖介于10元到30元或介于50元到100元的商品则会成为热销品。其余四条是非热销品规则,值得注意的是有一条规则比较有参考价值,即:如果商品价格大于200元,在家饰精品类这样的商品很难成为热销品。
决策树模型建立的过程也是参数变量重要性评定的一个过程。从图3左图可以看出影响销售量的影响因子是价格、商家信用、月份,这三个因子是按重要性依次递减。原因是商品价位在两层分类重复出现,说明商品价格是影响热销品的一个重要影响因子。其次是商家信用,从规则中可以看出低信誉度网络商家卖低价位商品容易成为热卖品,高信誉度网络商家卖中、高价位的商品容易成为热销品。最后是月份,它是影响因子中最小影响销售量的一个因子,但也能看出一些规则,在非热销品的月份中有1月和6月是属于淡季月份。最无关因子是商家所在地,也就是网络销售量无关乎所在地域不同,不存在地域性差异,当然也许我们所选的只有三个地区来源,没有明显的区分性。
3.3 CART算法模型评估
在完成基于分类回归树算法的建模和结果分析后,我们将利用预测集的数据来检验此模型的准确度,执行观测集数据流的结果评估,如图4:

图4 基于CART算法模型准确率分析图
由图可知,用CART算法对预测集进行检测后,此模型的准确率为84.58%,数据为203个,错误率为15.42%,数据为37个。从模型运行结果分析可以看出此模型对网络热销商品的识别方面具有一定的参考意义。只有数据信息量足够大,结果的准确率才会更高,而本文中所汇总后的销售记录数偏少。在现实生活中,销售的记录数要远远大于这些。另外,还有其它影响销售量的主要因素,比如广告、打折促销等都是影响网络销售量的重要因子。由于我们所采集到的数据中缺乏这样的信息,而且实际中影响因子也都是不同的,这些都是影响模型结果准确率的主要原因。
4.结束语
通过CART模型结果分析影响网络销售量的重要影响因子及得到网络热销品的有用规则,是一次很有意义的理论结合实践的尝试。一方面通过建立CART模型得到一些有价值的商业营业规则,可以帮助网络经营商经营决策;另一方面,通过数据建模也验证了CART算法的正确性、优越性和易用性。
[1]2009年上半年中国网络购物市场发展报告[EB/OL].http://down.iresearch.cn/Reports/Free/1306.html
[2]Jiawei Han Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰译.北京:机械工业出版社,2008.
[3]戴维·奥尔森.商业数据挖掘导论[M].石勇,吕巍等译.北京:机械工业出版社,2007.
[4]陈燕燕,许青松.分类回归树及其在个人信用评估中的应用[D].湖南:中南大学,2007.
猜你喜欢
文萃报·周五版(2022年17期)2022-05-05
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
公民与法治(2020年9期)2020-05-30
销售与市场(营销版)(2020年3期)2020-03-24
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
Coco薇(2017年11期)2018-01-03
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
