
基于FPGA的32位MIPS-CPU平台开发
2010-02-26 09:40孙建辉王春栋
电子与封装 2010年4期
孙建辉,王春栋
(中国电子科技集团公司第58研究所,江苏 无锡 214035)
1 介绍
本文设计的OPS1-CPU是RISC的一种,其只将最常用的指令在RISC处理器中实现,其他指令由编译器综合实现。这样RISC的硬件结构相对CISC比较简单,通过解决流水线引入的竞争与冒险,将CPI(Cycles Per Instruction)推到最大。通过研究与改善其编译系统,可以用编译器对整个CPU系统进行优化。本文的编译系统可以实现对设计的OPS1-CPU进行编译及优化。
MIPS[1]是RISC处理器中的一种。MIPS即无内部互锁流水级的微处理器(Microprocessor without interlocked piped stages),其机制是尽量避免流水线中的各种相关问题,使流水线得以顺畅地实现。可以通过研究指令的具体执行情况以及根据流水线的具体执行情况,增加竞争与冒险检测模块,使设计的流水线得以顺畅实现。
2 OPS1-CPU5级流水线与对应指令处理
MIPS-CPU包含5级流水线,如图1所示,分别是:
(1)IF/ID(Istruction Fetch&Instruction Decode),指令取指,根据程序存储器寻址计数器PC来对应读取程序数据,PC指向下一条指令,并且对取出的指令进行解码,解码后的信号为控制信号,这些控制信号被送到EX级以及其他级,指令在执行级需要来自寄存器堆的两个操作数,这两个操作数在译码级被送到ALU的a和b入口,同时译码级还把ALU运算操作信号送到ALU;译码器一旦识别出非条件跳转后,立即通知取指级IF。识别条件跳转后,根据标志位判别跳转结果并决定是否立即通知取指令级IF。
(2)RF(Register Fetch /generate next pc(branch included)),进行寄存器文件获取以及下一条PC地址的获取或产生,其中包括分支跳转情况。
(3)EX(Execution),指令执行,主要通过ALU运算。
(4)MA(Memory Access),存储器与外部设备访问级:数据存储器或外设的读写(仅load/store指令)。
(5)WB(Write-Back),写回寄存器堆。
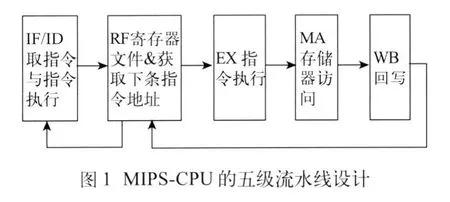
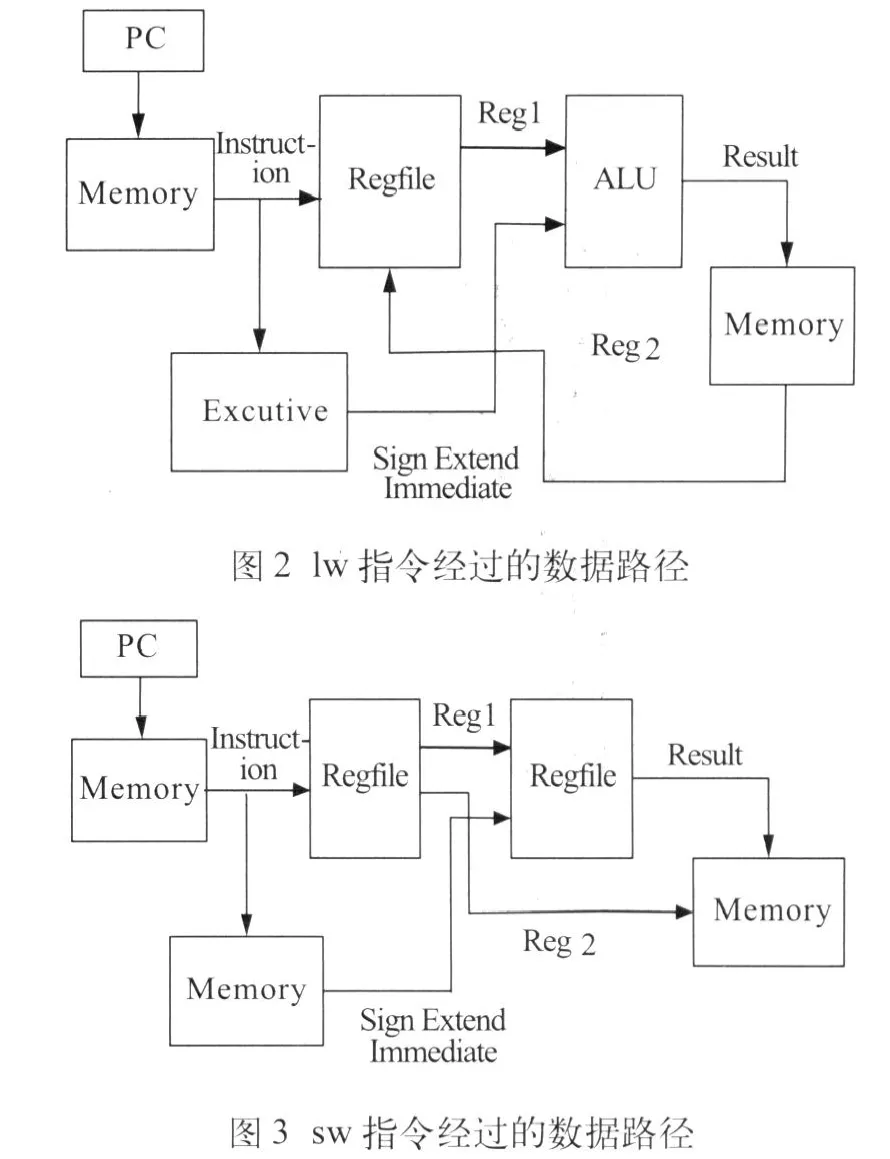
第4级流水线是专门为load/store指令设计的,如图2、3所示,指令load/stotre执行过程中的数据通道仍然要经过:(1)取指令&译码模块;(2)计算下一条指令的程序存储器的地址;(3)寄存器堆中的寄存器rs到ALU的输入数据A,指令中的立即数到ALU的输入数据B;(4)ALU执行加运算,计算数据存储器的访问地址;(5)ALU的运算结果R到通往数据存储器的地址总线;(6)来自数据存储器的数据总线通往寄存器堆的寄存器rt。
可见,load/store指令也会像非存储器访问指令(比如add指令)一样经过相同的流水线数据通道,因而本文设计的MIPS-CPU将存储器访问指令与非存储器访问指令统一于5级流水线来实现。
同时需要考虑“冒险”检测电路以及前馈电路设计。由于每个时钟周期获取的指令数量为1条,因而本文设计的MIPS-CPU是单发射极的MIPS-CPU。
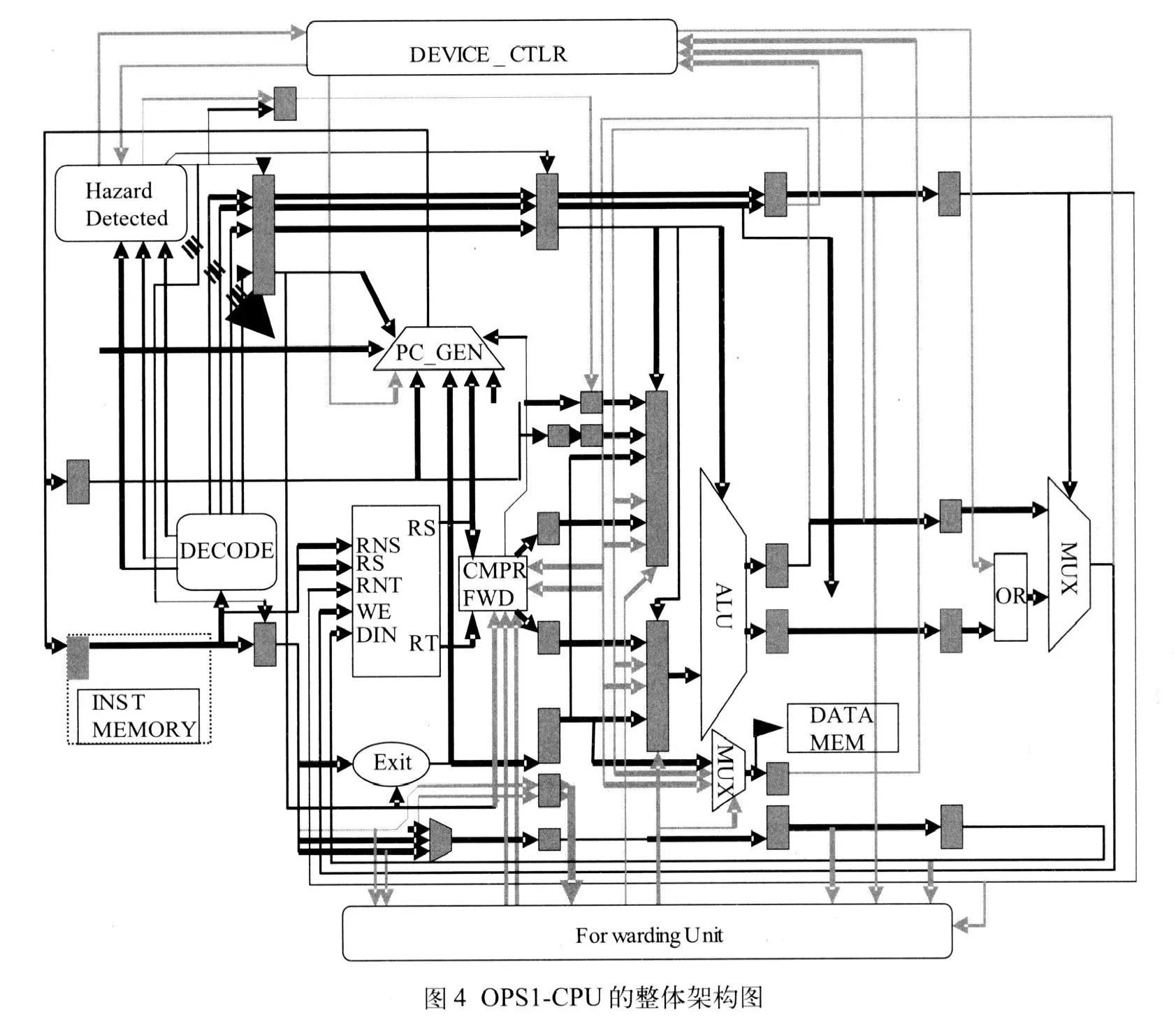
图4是本文设计的MIPS-CPU的整体架构图[2],在本图中标明了各个模块的名字。采用此种架构的原因是为了配合5级流水线结构以及冒险检测、数据前馈模块而设计的。主要由Device_Ctrl(控制模块)、Hazard_Detection_Unit(竞争检测模块)、P C_G E N(程序存储器地址产生模块)、Instruct_Memory(指令存储器模块)、Decode(译码模块)、CMPR&FWD(比较跳转与前馈检测模块)、Data_Memory_ctrl(数据存储器控制模块)、ALU(算术运算单元)、Forwarding_Unit(前馈模块)、Ext(执行模块)以及其他MUX模块、门级模块、数据总线、地址总线、控制总线等组成。
3 OPS1-CPU5级流水线及控制冒险处理
流水线程序转移将会产生一个很严重的问题,即程序必须在解码后才知道是转移指令,而程序的执行是在第3个级的执行周期才跳转到所要转移到的地址。若不加以判断处理而继续处理下去,会将原本要转移而不执行的指令继续执行下去,这种现象称为“冒险”。本文设计的MIPS-CPU的转移执行采用的处理方式是:把下面两个程序冲刷掉(FLUSH)。也就是说将转移指令后的指令改为00H指令的NOP不处理运算,而所有的控制信号都要被禁止。
流水线对应于数据序列执行的数据冒险(HAZARD)处理,由于流水线的级数引起的数据写回或者数据存储器内容的读取或者存取的延迟使得后续指令在译码级所获取的数据操作数内容不是立即更新的,因而造成了数据冒险。为了解决数据冒险,可以把数据写回或者数据存储器内容的写回在第三流水线级EXT级执行,而不经过流水线的底级存储器读取、写回或者流水线的第5级数据写回级,而不是等其将数据写入寄存器的MEM/WB管线处理后才予以读取,而改在程序执行到EXT级就将数据前馈给下面才程序的正在读取寄存器的ID/EXT流水线路径。
4 OPS1-CPU的编译与仿真模拟
本文设计的MIPS-CPU硬件系统完全被GNU所兼容,所以完全可以适用(并且本文设计的MIPSCPU的软件编译与调试系统符合GNU标准)用已经存在的基于GNU的编译系统进行高级或中级编程语言的编写,比如C与C++语言,来完成应用程序的开发,然后通过gccmips_elf仿真器来进行高层架构分析、程序编译、软件调试、程序运行结果以及代码效率分析[3]。利用该平台提供的C语言库文件,可以实现基于OPS1-CPU应用程序的开发。比如,对于计算∏的应用程序cal_PI.c,使用基于Windows-x86-DOS的gccmips_elf仿真器进行编译与执行,并且通过COM1口传输到终端显示,如图5所示。
图5 cal_PI-2函数的批处理过程
该仿真器要编译并且产生向量文件,即16进制的机器码,并且产生Modelsim下载的存储器RTL级的向量模型文件。并且同时产生QUARTUS II下载验证的QU2_RAM0~3.MIF文件。
再比如,通过使用编译器对中断函数执行批处理文件得到的RTL(sim_ram.v)文件进行Modelsim仿真,得到结果如图7所示。

图6 Pi的精确计算结果

图7 中断函数的仿真结果
通过仿真器的验证,表明本文设计的MIPS-CPU可以实现正常的功能,对其指令集中的绝大部分指令进行了验证,并且提供了一个编译、执行、优化与评估的平台,可以用来指导MIPS-CPU硬件架构的优化设计与实现。
5 MIPS-CPU的FPGA实现结果
本文设计的MIPS-CPU耗尽了3 457个LE,3 457/5 980×150 000=89 589,因而该MIPS-CPU大约为9万门的设计[4]。时钟频率设定为50MHz,建立时间余量为2.503ns,保持时间余量为0.662ns,均满足时序要求。由于编译时建立时间考虑的是最坏情况,而保持时间考虑的是最好的情况,也就是说采用的是保守编译,并且建立时间与保持时间的时序余量均为大于0的数值,因而本文时序满足要求。
整个OPS1-CPU占FPGA芯片面积为34.6×34.6mm2,本文设计的MIPS-CPU占整个芯片面积的70%~80%,即CPU面积约为831~957mm2。把输入的所有信号翻转率设置为12.5%,并且将不用的I/O设置为高阻态输入,其总理论功耗为261.68mW,动态理论功耗为194.13mW,静态理论功耗为67.55mW,符合预期的功耗要求。
6 结论
设计的OPS1-CPU可以实现5级流水线高效率运转,解决了竞争与冒险。gccmips_elf编译系统可以实现指令编译与优化。最终实现FPGA的电路映射,并且借助配合该编译系统的C库文件,开发基于C语言的运算等应用程序,最终板级指令调试成功,验证了该32位MIPS-CPU软硬件平台的正确性。
[1]MIPS Technologies, Inc. MIPS32™ Architecture For Programmers Volume II[M].The MIPS32™ Instruction Set,2003,7(9).
[2]http://www.opencores.org[EB/OL].
[3]陈曦,倪继利,李挥.CPU源代码分析与芯片设计及Linux移植[M].北京:电子工业出版社,2007.
[4]林容益编. CPU/SOC及外围电路应用设计:基于FPGA/CPLD[M].北京:北京航空航天大学出版社,2004.
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
小学科学(学生版)(2020年2期)2020-03-03
意林·全彩Color(2019年4期)2019-05-11
小学生优秀作文(低年级)(2017年9期)2017-08-07
中国资源综合利用(2016年9期)2016-01-22
儿童故事画报·智力大王(2015年2期)2015-05-20
福建人(2015年10期)2015-02-27
环球时报(2014-06-18)2014-06-18
自动化博览(2014年6期)2014-02-28
电子设计工程(2014年23期)2014-02-27
