
Nutch中文分词的设计与实现
2010-01-18 10:04:40张敏,杜华
河北北方学院学报(自然科学版) 2010年4期
张 敏,杜 华
(河北北方学院信息科学与工程学院,河北张家口075000)
随着Internet应用的日益普及,搜索引擎作为提供资源检索服务的工具已经成为人们通过网络获取信息的重要渠道,正在深刻影响着我们的生活[1].CNNIC公布的最新数据显示:2009年,搜索引擎的使用率为73.3%,是我国第三大互联网应用[2],将成为我国今后互联网应用的主流.
研究中文搜索引擎必须实现的关键技术之一就是中文分词.现有的分词算法分为三大类:基于字符串匹配的分词方法、基于统计的分词方法和基于理解的分词方法[3].其中,基于字符串匹配的分词方法,又称为机械分词方法,它具有分词效率高、算法实现简单的特点.这种分词方法可以分为正向匹配和逆向匹配.其中最常用的是正向最大匹配和逆向最大匹配.基于统计的分词方法按照文本中字串出现的频率进行统计,这种方法虽能有效地识别新词,但效率没有机械分词方法高,并且对常用词的识别精度差、开销大.基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果.由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段[4-6].
Nutch作为一个开放源代码 (open-source)的通用搜索引擎系统平台受到了众多开发者的青睐.与Google等商业搜索引擎相比,Nutch具有透明度高、扩展性好等特点.利用Nutch,可以方便快速的构造出一个性能良好的搜索引擎.但是,用于构建中文搜索引擎首要解决的是中文分词问题.即中文搜索引擎首先必须对网页原文进行词的切分.如果不进行分词,而是按单字来进行检索,则检索的结果可能与用户的查询要求相差较远.由于Nutch是基于英文的系统,虽然具有默认的中文分词功能,但它采用的分词方法是单字分词,即每个字被认为是一个词.这种方法对中文信息分析和处理的结果远远达不到人们所期望的效果.所以基于Nutch开发搜索引擎的第一步也是关键的一步就是设计合适的中文分词算法模块.本文选择采用基于字典的正向最大匹配分词算法,解决了Nutch系统中的中文分词问题.
1 中文分词器的设计与实现
1.1 中文分词算法设计
本文采用基于字符串匹配的分词方法——最大匹配法.最大匹配法分词需要一个词典,分词过程中文本里的候选词与词典中的词进行匹配,如果匹配成功,则认为候选词是词,予以切分;否则就认为不是词.所谓最大匹配,就是尽可能用最长的词来匹配句子中的汉字串.中文分词的正向最大匹配算法是:对一个字符串从前到后扫描,对扫描的每个字,从词表中逐一找最长匹配,这是一种减字的匹配方法.
假设对字符串S进行正向最大匹配分词,其算法描述如下:设自动分词词库中最长词条的汉字个数为n
Step1:取S中的前n个字作为匹配字段,记为S(n);
Step2:查找分词词库,将S(n)与词库中的词进行匹配,若词库中有这个词,则匹配成功,S(n)作为一个词被切分出来;
Step3:如果词库中找不到与S(n)匹配的词,则匹配失败;
Step4:n=n-1;
Step5:重复Step1—Step4,直到匹配成功.
Step6:从S中的第n+1个字开始,扫描字串S(n),重复Step2—Step5,直到n+1所指向的字为空.
1.2 中文分词模块实现
本文中设计的分词模块实现了正向最大匹配算法 (MM),并提供语料训练功能.
由于MM算法是基于词典的分词算法,所以词典的权威性直接影响算法的分词效果,而分词效果对搜索引擎的性能起着至关重要的作用.本文在研究中通过总结现在流行的词库,自行合并去除重复,最后得到了本系统的中文词库,一个词汇量为36 805的中文词典dic.dat,该词典为通用词汇词典.为了实现对新增词汇的切分,设计了语料训练模块,通过语料训练功能将新词添加到现有的词汇库中.具体的设计结构如图1所示.
Word Segment类对外提供分词接口,该类启动时载入词典类Dictionary,通过相关算法进行分词,并将分词后的结果返回给调用方.
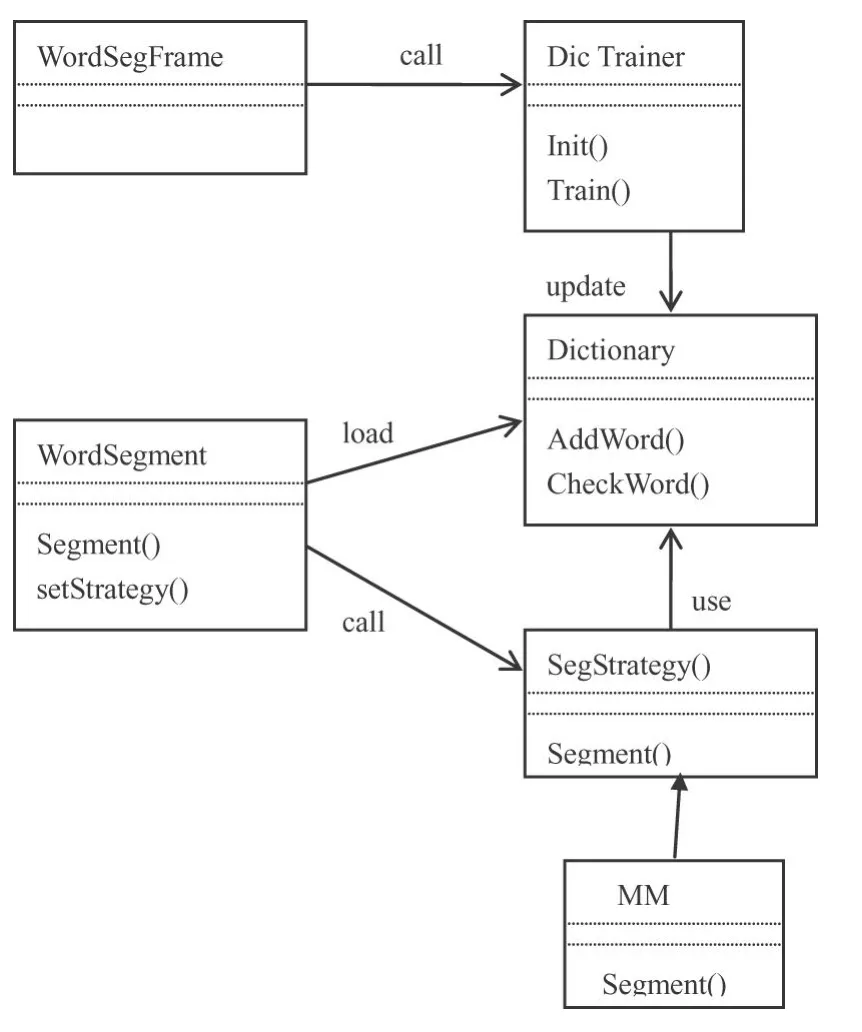
图1 中文分词模块设计类图
Dictionary类是词典类,记录所有的分词.
分词类:包括抽象类SegStrategy及相关实现MM.正向最大匹配算法MM就是在该类中实现的.
新词训练类:包括界面类Word SegFrame和Dic Trainer.他们提供了训练新词的能力,能够将训练好的新词添加到当前词典中,这样就使本系统具有了识别新词的能力.
所涉及的关键代码如下:
public final class RucChineseAnalyzer extends Analyzer{
private static Word Segment seger;
public static Set CHINESE_STOP_WORDS;
static{
seger=new Word Segment();
seger.SetDic("dic.dat");
seger.set Strategy(new MM());
}
public Ruc Chinese Analyzer(){
stop Words=Stop Filter.makeStop Set(CHINESE_ENGLISH_STOP_WORDS);
}
public Token Stream token Stream(String field Name,Reader reader){
Buffered Reader br=new BufferedReader(reader);
String temp=null;
String sentence="";
try{
while((temp=br.readLine())!=null){
sentence+=temp;
}
Vector vec=seger.Segment(sentence);
StringBuffer middleResult=new StringBuffer();
if(vec!=null&&vec.size()>0)
for(int i=0;i<vec.size();i++){
String temp2= (String)vec.get(i);
if(temp2.length()>1)
middleResult.append(temp2+"");
}
String result String=middleResult.toString();
TokenStream result=new RucChinese Tokenizer(new StringReader(result String));
result=new Lower CaseFilter(result);
result=new Stop Filter(result,stop Words);
result=new Porter StemFilter(result);
return result;
}catch(IOException ex){
ex.print Stack Trace();
}
return null;
}
}
为了验证分词效果,使用下面一段话进行了分词试验,例句“大多数搜索引擎在满足搜索全面性要求的同时难以兼顾专业性的需求.垂直搜索引擎面向特定领域,专注于自己的特长,保证了对该领域信息的完全收录与及时更新.与通用搜索引擎不同,垂直搜索的目标是尽可能多的搜集与该主题相关的网页.专业网络蜘蛛抓取到的网页如果与预定义主题相关,就做进一步的处理;如果不相关,则抛弃该网页.”对例句切分的结果为:“大多数/搜索引擎/在/满足/搜索/全面性/要求/的/同时/难以/兼顾/专业性/的/需求/./垂直/搜索引擎/面向/特定/领域/,专注/于/自己/的/特长/,/保证/了/ 对/该/领域/信息/的/完全/收录/与/及时/更新/.与/通用/搜索引擎/不同/,/垂直/搜索/的/目标/是/尽可能/多/的/搜集/与/该/主题/相关/的/网页/./专业/网络/蜘蛛/抓取/到/的/网页/如果/与/预定/义/主题/相关/,/就/做/进一步/的/处理/;/如果/不/相关/,/则/抛弃/该/网页 .”可见,分词的效果比较理想,并没有因分词导致严重的歧异.
2 分词算法性能分析
下面针对上述实现的分词算法,通过相应的测试数据集进行测试比较.在本文中,我们从国家分词规范中选择名词、动词、形容词来进行实验.对2005年SIGHAN国际分词竞赛的文本进行了实验,并对结果进行了分析.
本文通过对来自北京大学 (PKU)、微软研究院 (MSR)和香港城市大学 (CITYU)的测试语料分别进行了实验.
分词评测通常采用三个指标:正确率、召回率、F值.各指标定义如下:
定义1(分词正确率):表示切分出的词语中出现在标准结果中的词语比例,计算公式如下:
分词正确率= (切分出的词语中出现在标准结果中的词语数)∕ (切分出的词语总数)
定义2(分词召回率):表示标准结果中被正确切分出的词语比例,计算公式如下:
分词召回率= (切分出的词语中出现在标准结果中的词语数)/(标准结果中的词语总数)
定义3(F值):正确率和召回率的调和平均数,计算公式如下:
分词F值= (2×分词正确率×分词召回率)∕ (分词正确率+分词召回率)
1)测试环境
实验平台:Intel Centrino Duo 1.66GHz,1G内存,Windows XP,Java JDK1.5.
2)测试结果
(1)名词测试结果
在名词测试中对SIGHAN的CITYU、MSR和PKU的语料进行的测试结果分别如表1、表2和表3:

表1 名词测试结果表
(2)动词测试结果
在动词测试中对SIGHAN的CITYU、MSR和PKU的语料进行的测试结果分别如表2:

表2 动词测试结果表
(3)形容词测试结果及分析
在形容词测试中对SIGHAN的CITYU、MSR和PKU的语料进行的测试结果分别如表3:

表3 形容词测试结果表
3)结论
通过对名词、动词、形容词的测试,基本能够达到预期的中文分词要求.因此,MM算法应用于本系统是切实可行的.
3 结 论
本文在对中文分词技术进行分析的基础之上,在Nutch中设计并实现了具有中文分词功能和新词识别功能的分词器.实验测试结果表明,算法的分词效果能够达到预期的中文分词的要求.当然,现有分词算法的效率还有待提高,在今后的工作中将做进一步的研究.
[1] 中国互联网络信息中心.第二十四次中国互联网发展状况统计报告 [EB].http://www.cnnic.net.cn,2009.7
[2] 中国互联网络信息中心.第二十五次中国互联网发展状况统计报告 [EB].http://www.cnnic.net.cn,2010.1
[3] 邓宏涛.中文自动分词系统的设计模型 [J].计算机与数字工程,2005,33(04):1-4
[4] 肖红,许少华,李欣.具有三级索引词库结构的中文分词方法研究 [J].计算机应用研究,2006,25(08):49-51
[5] 徐华中,徐刚.一种新的汉语自动分词算法的研究和应用 [J].计算机与数字工程,2006,34(02):135-138
[6] 张民,李生,王海峰.基于知识评价的快速汉语自动分词 [J].系统情报学报,1996,15(02):4-13
猜你喜欢
智富时代(2019年6期)2019-07-24 10:33:16
高中生·天天向上(2016年9期)2016-11-22 09:10:34
英语知识(2016年1期)2016-11-11 07:07:54
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
电脑迷(2014年14期)2014-04-29 00:44:03
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
电脑迷(2012年15期)2012-04-29 17:09:47
外语学刊(2011年3期)2011-01-22 03:42:20
