
文本数据挖掘系统原型方案研究
2008-07-14 10:05奠石镁
电脑知识与技术 2008年18期
关键词:系统
奠石镁
摘要:本文在研究文本数据挖掘技术发展基础上,对文本数据挖掘系统设计进行深入分析,在此基础上,论文设计实现文本数据挖掘系统原型方案,该方案将文本分析、数据库和文本数据挖掘技术有机地结合起来,实现了文本特征值提取、特征值清理入库和关联规则挖掘等功能。
关键词:文本数据挖掘;系统;原型方案
中图分类号:TP311文献标识码:A文章编号:1009-3044(2008)18-20ppp-0c
The Study on Text Data Mining Antetype Solution
DIAN Shi-mei
(Yunnan Medical College, Yunnan 650031, China)
Abstract: Based on the analysis of text data mining technology, the paper makes deep study about text data mining system design. Then the paper puts forward and designs a text miner antetype solution , which combines text analysis, data base and text data mining technology and realizes such functions as text eigenvalue extraction ,association rule mining and so on.
Key words: text data mining; system; antetype solution
1 引言
文本数据挖掘是近几年才引起大家的关注并发展起来的一个数据挖掘领域的新兴分支,与机器学习、统计、模式识别等前缘理论方法密切相关。面对这样的挑战,数据挖掘和知识发现技术应运而生,并得以蓬勃发展,越来越显示出其强大的生命力,成为数据库研究的一个新领域。文本数据挖掘是通过自动提取文本信息在大量文本数据中发现未知的知识的过程,与自然语言密切相关,其关键是把提取的信息组合起来发现未知知识。文本数据挖掘不同于Web搜索,Web搜索是人们事先己知要查找什么,而文本数据挖掘是发现未知知识,事先可能并不存在。文本数据挖掘也不同于常规意义上的数据挖掘,常规数据挖掘是在数据库中发现感兴趣的模式,而文本数据挖掘是从自然语言文本中发现模式。
2 文本数据挖掘技术发展研究
文本数据挖掘可分为基于单文档的数据挖掘和基于文档集的数据挖掘阁。单文档数据挖掘对文档的分析不涉及其它文档,主要挖掘方向有文本自动摘要、文档知识总结发现、信息提取。信息提取又包括名字提取、短语提取和关系提取等,涉及到较深的语言学的知识。文档集数据挖掘对大规模的文档数据进行模式抽取,既可以文本自动摘要、文档总结,又可以进行文本分类、文本聚类、相似性分析、个性化文本过滤和信息检索。文本数据挖掘目前主要运用特征信息提取、聚类分析方法对文本进行分类,主要应用在信息学和图书信息检索方面提高信息检索效率,有少部分运用语言学的语法结构知识来分析文本内容,但进展缓慢不大。
传统数据挖掘所处理的数据是结构化的,如关系的、事务的数据库和数据仓库的数据,其特征项数目相对较少且结构单一;而文本数据没有结构,转换为特征矢量后特征项数目达到几万甚至十几万个。随着信息技术的发展,需要处理的文本信息也日益增加,传统的信息检索和处理技术已经不能满足大数据量文本处理的需要。文本数据挖掘既融合了很多传统数据挖掘的技术,如挖掘算法思想、挖掘流程构架等,又有自己独特的处理方法,表现在数据抽取、清洗及巨量数据挖掘算法的改进等方面。
文本可分为纯文本和超文本,超文本不仅有纯文本的性质,还含有各种标记和链接引入的结构对象(如声音、图片甚至应用程序等)。对纯文本和超文本中纯文本部分都可以进行内容挖掘。文本内容挖掘又可分为有背景知识挖掘和无背景知识挖掘。有背景知识挖掘是通过分析文本的语法特征和少量语义特征来进行挖掘,使用的背景知识主要是自然语言知识,如主谓宾及修饰性词句语法分析、通过辅助词进行语义分析等,主要挖掘结果是文本的语法结构性和语义性特征。无背景知识挖掘则主要是通过统计方法提取文本特征数据,再对这些提取出的数据进行挖掘,挖掘的数据主要是文本的描述性特征,挖掘的结果根据业务需求千差万别,如可以通过比较提取出的特征数据的相似程度对文本进行分类,可以在文件检索中提供给检索者相关特征词的文件,还可以对文本进行自动文档摘要处理等。
文本数据挖掘与目前数据挖掘热点Web数据挖掘也有较大的差别。Web数据挖掘属于点击流数据挖掘,主要关注网页的链接,如Google用“PageRank”来度量网页重要(兴趣)程度,还对网页使用者的个人信息、使用习性等进行挖掘,以更好的检索信息、改进Web内容结构等,从理论上讲还包括文本数据挖掘,但在目前应用中还对文本数据内容本身关注较少。文本数据挖掘主要关注于文本内容本身,先对文本信息进行结构化处理,再利用挖掘算法发现文本中的未知知识或找出文本之间的关联信息等。文本数据挖掘也与Web搜索不同,Web搜索是查找事先已知的内容,而文本数据挖掘则是发现文本中的相关知识,这些相关知识是事先未知的。
3 文本数据挖掘系统设计分析
文本数据是一种仅具有有限结构甚至是根本没有结构的数据体,文本的格式可能存在着段落、缩进以及正文与图形表格等形式的差别,但对内容而言是完全不同的。对一个纯文本进行无背景知识关联规则数据挖掘第一步是通过完全统计文本中二字词、三字词、……、n字短语出现的频率提取文本中的特征数据。所谓“特征数据”在中文文本中主要指按字数分词处理后得到的词汇。其前提依据是出现的频率越高,这些特征词就对该文本越具有文本语义上的特征描述性,这些高频率的词就在一定程度上代表全文的主题思想。通过分析还发现文本数据的存储结构方面,每个汉字和标点符号等文本数据占两个字节,而文本中的英文字符则占一个字节:汉字和标点符号文本数据之间没有间隔符,而每个英文单词的文本数据之间则有间隔符来分隔。由于文本数据之间的这些特性造成了对中文文本文件数据进行无背景知识统计分析容易引入一些乱码,这些乱码一方面可以通过频率值门限值清除,另一方面还要通过数据清理清除。文本数据挖掘的第二步就是要对统计出的数据进行清理,把乱码数据和一些达到统计频率门限值的特征数据清除掉,保证提取出的特征数据既能表达文本的特征信息,又能保证数据挖掘数据正确性的要求,最后把提取出的特征数据加入到数据库中。
文本特征值提取是文本关联挖掘系统中的一个关键步骤,而文本关联挖掘系统的困难之一便是特征值空间的维数过高,特征值的维数对应着文本中不同词汇的个数。数量巨大的特征值维数一方面导致挖掘算法的代价过高,另一方面导致无法准确地提取文档的特征信息,造成挖掘效果不佳。需要在不牺牲提取特征质量的前提下尽可能地降低特征项空间的维数。“特征选取”的任务就是要将信息量小、“不重要”的词汇从特征项空间中删除,从而减少特征项的个数。特征值提取是一个维数归约的过程,即删除不重要的特征值从而减少特征空间的维数。文本特征值提取中,不同的词在文本文件中出现的次数是不相等的,对文本内容的贡献也就有大有小,因此还要考虑词在文本中的权重。把文本特征数据提取出来并加载到数据库以后,就要对这些特征数据进行数据挖掘以发现这些特征数据之间的关联规则。关联规则数据挖掘是通过以每个文件名作为标识号,以文本的特征数据及其权重值作为文件名标识号下的数据项,对这些数据项进行关联分析可以发现文本中隐含的信息和这一组文本文件之间的一些关系。关联分析算法通过统计交易数据库中每项交易记录中每个候选集出现的次数作为该项集的支持计数,然后比较支持计数和其支持度期望,得到频繁项集,最后生成关联规则。本系统原型采用加权关联规则算法。这些挖掘结果既可以用于单文档的自动关键字提取:还可用于信息关联检索,提供给用户信息检索时更广阔的密切相关的信息,帮助人们提高处理大量文本数据的效率;以及发现隐藏在文本文件之间的语义内容知识。
4 文本数据挖掘系统原型方案
本文在对分析文本数据挖掘相关理论算法基础之上,设计实现文本数据挖掘系统原型TextMiner方案。TextMiner将文本分析、数据库和文本数据挖掘技术有机地结合起来,实现了文本特征值提取、特征值清理入库和关联规则挖掘等功能。TextMiner主要由数据抽取、特征值清理、特征值入库、关联规则数据挖掘和规则应用几部分构成。
(1)确定目标样本:由用户选择确定挖掘目标的文本样本,用于数据抽取模块进行文本特征值的提取。
(2)数据抽取:对用户指定的纯文本文档集,按照用户指定的特征值最低统计计数提取文本中的特征值。特征值抽取是采用无背景知识的抽取方法,对文本的二字词组、三字词组、……、n字词组出现的次数进行统计,若出现次数超过指定的最低计数则把这个词组作为该文本的一个特征值。
(3)特征值清理:对数据抽取得到的特征值进行清洗。文本文件的抽取是在文本中按位置读出,一些位置上出现一些无自然语义的控制符也被读入形成无意义的乱码,若这些乱码超过最低统计计数,则也被加入到特征值中,所以有必要对特征值中这些无意义的乱码进行清洗,以保证数据库中数据的一致性和准确性。
(4)特征值入库:把数据清理后的特征值加入到数据库中,同时入库的还有文本文件的相关属性值,如文件名、文件路径、创建时间、最后修改日期、入库时间等。
(5)关联规则挖掘:特征值装载入数据库后,每一个文本文件对应一个特征值向量,与商品交易数据库中交易标识号和交易记录类似。运用加权关联规则算法对这些特征值向量进行关联挖掘,得到关联规则。
(6)应用:TextMiner主要考虑把系统挖掘出的关联规则用于未知知识发现、文本内容检索,其它扩展应用还有文本聚类、自动文本关键字提取、自动文本摘要等。
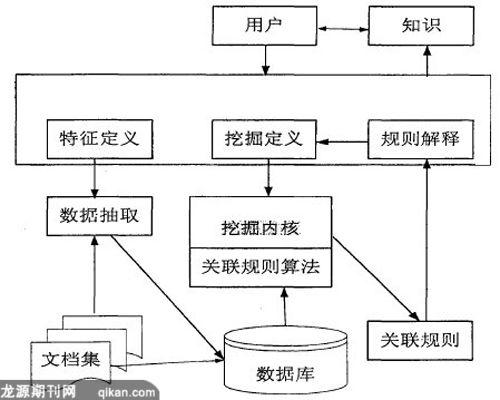
图1 文本数据挖掘系统原型方案
5 结束语
文本内容挖掘才刚刚起步,其前景十分广阔,将成为信息检索和情报分析中的一个重要课题,同时把文本内容挖掘的研究成果应用到搜索技术中将为人们提供更准确的有价值的搜索结果。
参考文献:
[1] 钟艳花,余伟红,余永权.web文本挖掘系统及其关键技术研究[J].计算机工程与应用,2006(34):167.
[2] 湛燕,陈昊,袁方.文本挖掘研究进展[J].河北大学学报(白然科学版).2005,23(2):221.
[3] 薛为民,陆玉昌.文本挖掘技术研究[J].北京联合大学学报(自然科学版),2005,19(4).
[4] 范亚芹,刘颖,李兴男.web数据挖掘原理及实现[J].吉林大学学报,2004(21).
[5] 高洁,吉根林.文本分类技术研究[J].计算机应用研究.2006.7.
收稿日期:2008-04-13
猜你喜欢
工业设计(2022年8期)2022-09-09
军民两用技术与产品(2021年10期)2021-03-16
装备制造技术(2019年12期)2019-12-25
制造技术与机床(2019年10期)2019-10-26
中国洗涤用品工业(2019年4期)2019-05-11
铁道通信信号(2018年5期)2018-06-28
家庭影院技术(2017年9期)2017-09-26
知识经济·中国直销(2017年5期)2017-06-15
通信电源技术(2016年6期)2016-04-20
西北工业大学学报(2015年1期)2016-01-19
