
创新型多核处理器的发展
2006-07-27 10:49董立平胡苏太
计算机世界·技术与应用 2006年21期
董立平 胡苏太
布线延迟将影响目前主流商用超标量和VLIW技术的长远发展。目前,一些新型多核处理器结构初露端倪,它们依赖于开发指令级并行性以外的其他更粗粒度的并行性,如数据级并行性和线程级并行性,以实现更高性能和应用效能。
仅靠扩充目前占主流的超标量和VLIW技术,要实现新一代处理器是十分困难的,其中一个主要原因是布线延迟问题。随着芯片制造技术的发展,一个时钟周期中信号在芯片内所能传输的范围越来越小。特别当未来采用35纳米以下设计技术时,在一个时钟周期内信号所能传输的范围仅为芯片面积的1%。在采用传统架构的处理器中,为使信号传遍芯片的各个角落往往需要很大的延迟,在进行距离最远的两点间通信时,会产生数十个周期的延迟,因而引起性能的急剧下降。为此,在考虑未来5~10年的处理器设计时,必须从结构设计顶层就充分考虑布线延迟问题。这要求体系结构和微体系结构进行根本的变革。
目前,一些新型CMP结构初露端倪,它们依赖于开发指令级并行性以外的其他更粗粒度的并行性,如数据级并行性和线程级并行性,以实现更高性能和应用效能。
Tile 结构处理器
我们把无布线延迟问题的小尺寸功能块,按一定规则排列构成高速处理器的方式称为Tile结构。这种方式由于受到小尺寸功能块的制约,可以大大减轻在Tile内部产生的布线延迟问题。此外,由于信息传输仅在物理位置相距很近的几个Tile间进行,因而也使Tile间的通信延迟得以缓解。
Tile结构与超标量处理器最大的不同就在于,Tile处理器是由多个采用相同设计的功能块按一定规则排列构成的,其功能部件主要有计算单元、Tile间连接布线和路由器等。它与采用总线或环网连接的多核处理器有许多共同点,然而其设计思想却有很大差别。多核处理器尽量沿用了传统处理器设计技术,只是对高速缓存和互连网络进行了优化以谋求更高的性能。而Tile处理器为了克服布线延迟,在传统处理器从未采用过的Tile内部结构上下足了工夫,即在芯片上配置多个结构完全相同的Tile单元,以提高设计的可重用性,减轻验证等作业的负担。这种Tile结构大多采用在增加Tile单元数时,不降低工作频率的就近连接网络。

旨在提高大量视频和音频数据处理速度的专用多媒体处理器,也有采用类似Tile结构这种将多个处理器配置于二维网格结构的。然而,Tile结构面临的最大挑战是,作为通用处理器它必须能高效地处理各种应用。为了有效利用与传统处理器有很大差异的Tile结构,多数Tile处理器采用了独特的指令集结构,因而放弃了与传统的CISC和RISC处理器的代码互换性。此时,应用程序要用C或Fortran等高级语言描述,并用独特的编译器生成Tile处理器专用的目标代码。下面介绍两种典型的Tile结构处理器。
1)Raw处理器
美国马萨诸塞大学正在开发的Raw处理器可以说是Tile结构的先驱,除克服布线延迟外,用活Tile结构丰富的硬件资源,充分利用处理器有限的管腿也是Raw追求的目标。目前,Raw正在进行芯片试制和系统级评价。
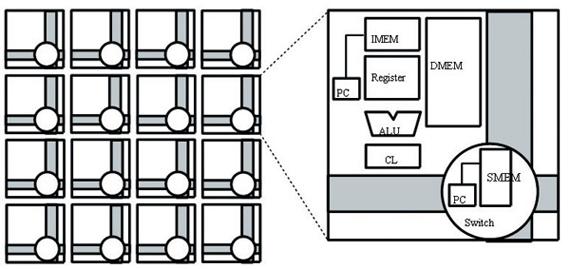
如图1所示,Raw处理器由16个结构相同的Tile单元构成,而每个Tile单元由近似MIPS处理器的单指令发射内部处理计算流水线和静态、动态网络构成。每个Tile单元可作为具有独立程序计数器的处理器工作,当指令或数据缓存发生错误时,则从配置在芯片外的主存获取数据。

Tile单元间的通信必须借助寄存器,所有布线均被设计为短于Tile单元单边的长度。因此,即使是根据应用的性能要求或可用晶体管数的提高,而增加集成的Tile单元数也不会降低芯片的工作频率。假使试制芯片经过每个Tile单元时产生1个周期的延迟,则右下Tile单元要使用左上Tile单元生成的数据,会产生6个周期的通信延迟。
Tile单元中的运算流水线由8级指令流水线构成,每条运算流水线都采用单指令发射的简单结构。尽管一个Tile单元每个时钟周期只能处理一条指令,但16个Tile单元可同时进行运算,因而每个芯片一个时钟周期就可完成16条指令的处理,从而达到较高的峰值性能。
为了缩短Tile单元间的通信延迟,在运算流水线的数据通路中嵌入了专门的通信机构,这样无需特殊指令就可进行Tile单元间的数据传送。
Raw处理器的硬件结构十分精炼,即使对最复杂的通信和计算也能提供可明确描述的指令集,在运算流水线的数据通路上还设有专门的通信机构,从而大大缩短了Tile单元间必要的通信延迟。

2) TRIPS处理器
IBM和德克萨斯大学也正在开发一款采用Tile结构的TRIPS处理器。该处理器由网状配置的多个运算结点(Tile单元)构成,其运算结点则由单指令发射的简单整数运算、浮点运算部件和指令缓存、操作数缓存及操作数路由器构成。采用大数据流执行方式是TRIPS处理器的一大特征。
将运算结点按4×4网状配置的TRIPS处理器的结构如图2所示,由于只能在邻近结点间进行数据传送,因而有效缓解了布线延迟问题,这点与Raw处理器相同。而与Raw处理器不同的是,配置了指令缓存、数据缓存和寄存器文件的运算结点可自动检测数据的到达,并从运算数据齐全的指令开始执行。
TRIPS处理器不是以单个指令为单位,而是以块为单位向运算结点分配指令。它给16个运算结点分别装上识别符,编译器利用这一信息静态地将块内的指令分配给每个运算结点。TRIPS处理器以块为单位取出指令,当构成块的所有指令处理完毕时,才释放该块所使用的资源。每个运算结点拥有多个指令缓存,可取出多个指令块。各运算结点可在从多个指令缓存所要取出的多条指令中,将可处理的指令激活。
TRIPS处理器与Raw处理器一样,所有Tile单元都未采用缓存结构,而是在Tile单元周围配置了一些指令和数据缓存,因而为了取出必要的指令和数据势必产生延迟。例如TRIPS处理器在进行向量加法运算时,从一个块开始处理到结束需要80个时钟周期,光取指令就需要10个时钟周期。为了隐藏块处理的较长延迟,TRIPS设法使处理器最多可同时并行执行8个块的处理。
目前德克萨斯大学正在积极推进集成有32个Tile单元的TRIPS处理器的设计,并已于2005年12月开发出了可使用4个这种芯片(集成有128个Tile单元)的原型系统。
面临的课题和今后展望
随着布线延迟问题的日益突出,能有效减轻布线延迟影响的Tile结构开发方兴未艾。目前,关于Tile结构的研究正处于包括常规应用、伺服应用和多媒体处理等各种应用的基本方法开发阶段。
下一步如何引入目前正在超标量处理器中研究的存储器访问延迟隐藏技术和投机技术,并对Tile单元的功能及尺寸进行最优化是今后面临的主要研究课题。此外,在保持高速处理的同时,如何减少功耗,提高芯片的可靠性也是需要重点研究的问题。Tile结构的本质就是在保持较高工作频率的同时,使配置的多个Tile单元能并行工作,以达到较高的处理性能。因此,有助于从应用中抽出内在并行性的编程手法及通用并行程序的开发和普及也是未来的长期研究课题。
Tile结构是一种采用特殊指令集的崭新结构,尽管在其实现和普及的过程中,仍有很多需要研究解决的课题,但作为一种面向未来10年的处理器结构,Tile结构无疑是一种魅力十足的选择。
PIM结构处理器
超标量、超流水线处理器的设计正日趋复杂,而这种复杂性很大程度上是为了隐藏存储器访问延迟。为了摆脱这一趋势,研究人员提出了PIM结构。
PIM(Processor-In-Memory),将一个或多个处理器与大容量、高带宽的片上DRAM存储器集成在一起,从而大大缩短访存延迟,提高了数据带宽。PIM的处理器本身可以是一个简单的或普通的超标量标准处理器,也可包括一个向量部件。PIM非常适合于数据密集型运算。
Intelligent RAM(IRAM)
美国加州大学伯克利分校的Patterson等人提出了IRAM结构(如图3所示),与传统的结构相比,有以下的技术优势:
● 更大带宽和更低延迟: 重新设计存储接口以及片上存储器的邻近性,存储延时改进5%~10%,存储带宽提高50%~100%;
● 更高的能效: 减少与片外的联系,改善存储能效2%~4%;
● 低成本: 复制存储器来填充芯片,而不是定制逻辑,可成倍降低成本;
● 在单芯片上集成更多部件,减少板的面积4%甚至更多;
● 可以调整存储器的大小和组织使之更适合工作负载;
● 用高速、点到点的线替换IO总线,改进IO带宽4%~8%。
但IRAM还存在很多缺陷,其中最重要的一点就是系统的可扩展性不好,从IRAM中能得到的最大存储容量只有128MB。
Active Pages
Active Pages是加州大学Davis分校的Oskin等人提出的一种基于页的计算模型,它赋予存储器每一页简单的功能。与其他PIM方案相比,Active Pages有三个主要特性:
● 增强PIM结构中微处理器的性能,与IRAM用单芯片结构替换传统结构不同,它更注重桌面应用对存储的需求。应用在处理器和Active Pages之间进行划分,如果应用中有很多浮点操作,则试图提供给处理器更多的操作,使得它保持在峰值速度。反之,如果应用中有很多数据操作和整数运算,则划分的目标是开发更高的并行度,尽可能使用更多的Active Pages;
● 使用与传统存储系统类似的接口,包括标准的存储接口功能,提供给页面的一组用来计算的功能集合和给每个Active Page分配虚拟地址功能中的数据可以用传统的存储器读和写命令来修改,其包含的功能通过存储映射的写来调用;
● 高并行度: 包含物理存储器中成百上千的页,支持这些页中的同时计算。
Active Pages用可重构结构的DRAM(RADRAM)来实现,对于数据密集型计算,可以获得1000倍于传统存储系统的加速比。
DIVA
很多应用有高存储带宽的需求。比较规则的应用,如涉及大数据量的密集矩阵运算,可以通过开发局部性、编译优化和延迟隐藏等技术获得很好的性能。对于不规则的应用,比如稀疏矩阵和基于指针的运算,它们一样有高存储带宽的需求,但由于程序控制和数据访问不能静态预测以及不能有效利用Cache,存储器访问等待时间很长,利用传统的实现方法不能获得理想的性能。为此,美国南加州大学的Hall等人将PIM结构与PIM-PIM之间的互连结合起来,提出了DIVA(Data-Intensi Ve Architecture)结构,它主要通过两种机制来提高存储带宽:
● 在存储器中执行选择计算,减少通过处理器-存储器之间的接口传输数据的次数;
● 为数据和计算在整个存储器中移动提供称为parcels的通信机制,可以旁路处理器/存储器总线。
DIVA的结构如图4所示。与其他PIM结构一样,在单个PIM芯片中,存储带宽的提高和访存延迟的降低都很显著。更重要的意义在于,DIVA中多个存储芯片可以并行工作,操作相对独立的数据,执行PIM间的通信而不需要经过处理器/存储器总线。
图4中,Host处理器通过Host-Memory接口执行标准的读写操作,而PIM则是具有通用和专用计算目的的硬件结构。一个PIM芯片包含多个结点、一个PIM路由协处理器(PiRC)和一个host接口。每个结点又由一个处理逻辑和几MB的存储器组成,其中处理逻辑是一个标准的标量微处理器,包括一个浮点单元和一个At-the-Sense-Amps Processor(ASAP),ASAP对保存在本地存储器一行中的数据进行宽位操作,在一个时钟周期内可以处理256位数据。通过对三个不规则应用的模拟测试,DIVA结构可以取得比较好的性能。
PIM的未来
从上述多种采用PIM技术的处理器开发情况可看出,PIM作为量产商用处理器使用仍然有待时日。第一个PIM芯片是1993年推出的EXECUBE芯片; 1996年,第一款商用的PIM芯片M32R/D诞生,但至今10年过去,PIM仍然没有成为量产的通用处理器。其原因除了传统处理器仍有很大发展空间外,PIM自身还存在工艺上的问题,因为制作处理器的工艺不同于制作存储器,存储器过低的时钟频率不能满足逻辑电路的高速需要; 另外,PIM在构成系统时仍没有统一标准的通信机制; PIM和非PIM系统之间的接口也不兼容。
仍处在探究阶段的PIM技术可能首先会在一些超级计算机上得到成功应用,如美国HPCS计划中的Cray Cascade、Sun Hero 和IBM的BlueGene项目都采用了PIM技术。但是,如何让数百万个PIM处理器协同求解单个并行应用问题,需要寻找不同于MPP结构的大规模并行处理和存储平衡的体系结构方法。
猜你喜欢
环球市场信息导报(2018年21期)2018-07-27
科技创新导报(2016年28期)2017-03-14
中小企业管理与科技·下旬刊(2016年10期)2016-11-18
小学科学(2016年7期)2016-05-14
环球时报(2014-06-18)2014-06-18
计算机世界(2009年27期)2009-07-30
电子设计应用(2004年10期)2004-06-28
