
VMD-Stacking集成学习的多特征变量短期负荷预测模型
2024-03-04 12:57王士彬余成波
兵器装备工程学报 2024年2期
王士彬,何 鑫,余成波,张 未,陈 佳
(1.国网重庆市电力公司市南供电分公司, 重庆 401336; 2.重庆理工大学 电气与电子工程学院, 重庆 400054;3.重庆市能源互联网工程技术研究中心,重庆 400054)
0 引言
在电力系统中,电力负荷是重要的组成部分,更准确的负荷预测结果能让电网制定更灵活、经济的调度计划[1],确保电力系统安全、稳定地运行。因此,提高电力负荷预测准确度意义重大。
电力负荷预测主要是通过对历史负荷数据资料进行统计分析,利用数学模型和统计方法,对未来某一时期内电力系统各负荷点的用电情况进行预测,短期负荷预测时间为1天到1个星期。目前,短期电力负荷预测的理论和方法展开了大量研究[2-4]。周莽等[5]对负荷数据及有关天气、节假日信息进行栈式自编码,然后构建门控循环单元神经网络预测电力负荷,实例结果显示这种包含更多信息的模型具有预测误差更小、精度更高的特点。李坤奇等[6]对居民用电进行短期预测时,考虑到了不同用户的用电习惯,并构建了由时间以及气候信息组成的多特征时间序列数据集,使预测误差大幅降低。张宁[7]用集成经验模式分解算法把负荷数据自适应分解后,根据不同分量的特点建立极限学习机模型对电力负荷短期预测,经实验证明,相比于传统极限学习机、支持向量机模型的平均绝对误差降低约0.01。在负荷组成成分更复杂、短时间变化量更大的工业负荷使用单一预测算法结果精度往往较低,亓晓燕等[8]对某钢铁工业地区负荷分解,再使用一种融合长短期记忆网络和支持向量机不同优点的改进算法预测,比单独采用长短期记忆网络、支持向量机算法的模型准确率分别提升了5.15%、6.43%。
可见,在负荷预测过程中使用有效的多特征变量、数据分解、模型融合等方法可以提高预测准确度。为了减小负荷序列波动性影响、学习到更多有效特征信息、对多个算法取长补短,提出了一种VMD-Stacking集成学习的多特征变量短期负荷预测模型。
1 模型原理
1.1 VMD算法
Konstantin Dragomiretskiy和Dominique Zosso在2014年提出了VMD算法[9],这种分解方法使用迭代搜索变分模型最优解来确定每个子模态分量的中心频率及带宽,且每个模态在解调成基带之后是平滑的。分解后的IMF分量能够特征互异,避免模态混叠和端点效应,对采样和噪声有更强的鲁棒性[10-11]。类似的,使用VMD分解电力负荷序列可以得到较为平稳的子序列来提高负荷预测结果的准确度。具体步骤为:
第1步:把电力负荷序列P(t)分解成预设的k个IMF分量,然后,对每个负荷子序列uk(t)做Hilbert变换,得到相应的单边频谱:

(1)
式(1)中:δ(t)为狄拉克函数,*为卷积运算符。
第2步:在每个uk(t)中加入预估的中心频率ωk进行修正,并将其频谱移到基频带上,计算公式为
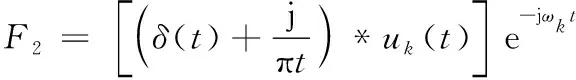
(2)
第3步:计算梯度的L2范数的平方,估计对应负荷子序列uk(t)的基频带宽,为了使得其带宽估计之和最小,构建出带约束条件的变分模型如下:
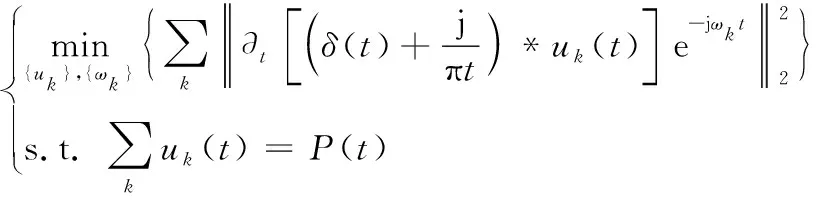
(3)
式(3)中: ∂t为偏导运算符,‖‖2为L2范数。
第4步:为了简化计算式(3)的约束变分问题,引入Lagrange乘子λ(t)和二次惩罚因子α,将其转为无约束条件的变分模型:

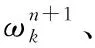
模态变量计算为

(5)
中心频率计算为
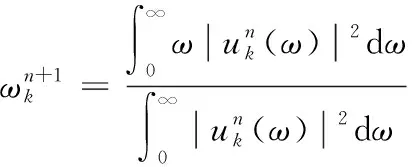
(6)
终止条件为
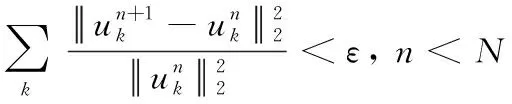
(7)
1.2 Stacking集成学习模型
Stacking集成学习框架可以融合多个算法,使预测结果精度高于单一算法的性能[12-13]。图1所示为该模型框架图,分为两层结构设计。其中,第1层由一个或多个基学习器组成,因融合的学习器越多,模型越复杂,训练时间更长,本文中仅使用2个初级学习器;第2层采用一个简单的算法作为元学习器,不仅强化了学习效果,而且不会造成预测模型过冗余复杂、过拟合现象。

图1 Stacking集成学习模型框架
Stacking集成学习模型构建的具体步骤如下:
第1步:基于交叉验证的思想,将训练集划分为5个大小相等的子集,再依次遍历这5个子集,每次把当前子集作为预测数据,剩余的4个子集作为训练数据,共遍历5次,对应第1~5折。
第2步:把每一折中用于训练的子集导入基学习器1训练,然后基于训练好的基学习器1对测试集和需要预测的子集进行预测,经过5折的训练与预测后,组合每折训练集的预测结果得到新训练集,每折测试集的预测结果取平均值得到新测试集。同理,对基学习器2重复这一步骤。
第3步:利用第一层输出的新训练集训练元学习器,基于训练好的元学习器对新测试集预测,得到最终的预测结果。
1.3 VMD-Stacking集成学习模型
选择Stacking集成学习框架的基学习器方面,考虑到不同算法有不同的原理与特性,XGBoost和LightGBM都是通过优化梯度提升树算法而来[14-17],然而它们的决策树生长策略不同。XGBoost采用带深度限制的level-wise生长策略,不容易产生过拟合现象,但没有对同一层叶子加以区分,造成训练时间和内存消耗方面存在劣势;LightGBM采用leaf-wise生长策略,速度和性能远优于XGBoost,但需要加入一个最大深度限制,否则会产生过拟合。所以,将XGBoost和LightGBM作为基学习器,简单的贝叶斯回归算法作为元学习器,负荷预测结果准确度会有不少提升。
VMD-Stacking集成学习模型具体流程如图2所示,将划分好的负荷序列经过变分模态分解后得到IMF分量和RES分量(总有功功率减去各IMF分量值)导入Stacking集成学习模型得到各分量的预测值,重组预测值后得到预测结果,并设置多无特征算法组和有多有特征算法组作为对比评价。
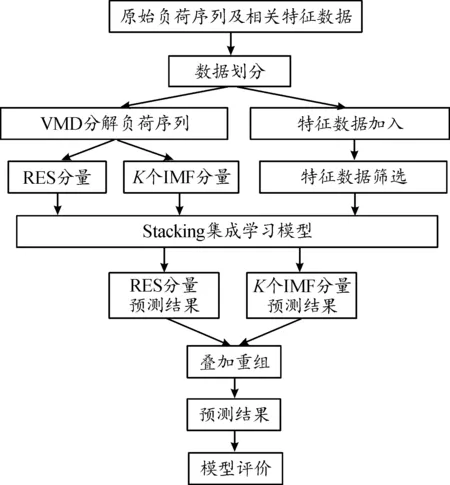
图2 预测模型流程
2 算例分析
本次分析选择某地区2018年1月—2021年8月的负荷总有功功率为实验数据,采样间隔15 min,其中2020年8月以前的数据作为训练数据,且按时间划分为4个季度。使用不同的方法来预测剩下一年中每个季度所对应春分、夏至、秋分、冬至、春节这5天的负荷情况,评估其预测结果来检验所提模型的有效性。
2.1 VMD分解负荷序列
在使用VMD算法前需要确定分解模态数k,如果k值过大会出现模态混叠,相邻模态分量接近中心频率,产生额外的噪声;k值过小会造成欠分解,有效信息被忽略掉,不利于提高预测结果准确度。VMD算法中不同的k值对应分解后子模态分量的中心频率不同,可以用中心频率观察法[18]来确定k值。以负荷序列为分解对象,设定不同的值,得到各IMF分量对应的中心频率如表1所示。

表1 各IMF分量中心频率
当k>4后,最后一个IMF分量的中心频率增量很小,若继续增大k值分解会导致各分量中心频率距离越接近,造成模态混叠。
综上,取k=4对负荷序列进行分解,结果如图3所示。由于分解的是负荷序列,如果直接抛弃信息丰富的RES分量将会限制模型的预测准确性[19],所以本次分解保留了RES分量。
2.2 特征重要性分析
从图3负荷有功功率曲线可以看出该地区夏季用电量大,冬季临近春节时的用电量小,有一定规律性。在日期的基础上收集每天的温度、天气、农历和节假日情况等作为特征变量[20-21],但在预测过程中过多的无关变量反而会影响模型的训练效果。分别用LighGBM和XGBoost算法预测春分、夏至、秋分、冬至、春节这5天的负荷情况,得到每个特征的重要性占比平均值如图4所示。可以看到,这2种算法对特征的重要性比值有所不同,LightGBM算法注重时间变化,XGBoost算法则更偏向温度变化。在预测时去除各自重要性占比小于1%的特征。
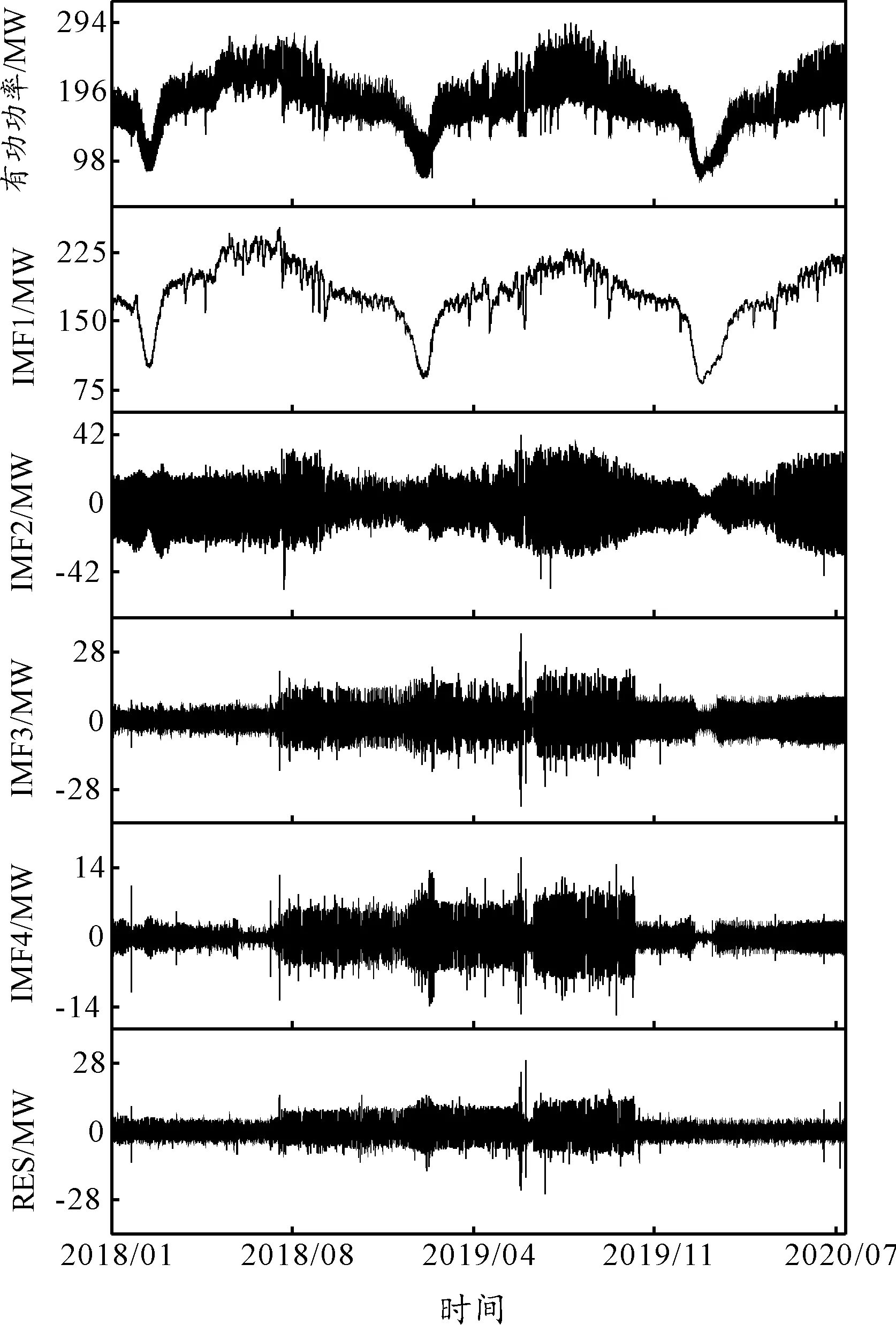
图3 变分模态分解结果

图4 特征的重要性比值情况
2.3 预测模型训练
将变分模态分解后的各分量及相关特征数据前80%划为训练集,剩余的数据作为测试集导入Stacking集成学习模型。使用网格搜索法寻找各学习器最优超参数,并基于最优模型预测负荷有功功率分量数据。最后,把各分量数据的预测值相加即得到预测结果。
2.4 模型评价
评价回归预测类模型以均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)、平均绝对百分比误差(mean absolute percentage error,MAPE)作为评价指标,其计算方法如式(8)—式(10):

(8)

(9)

(10)
其中:ypred和yreal分别表示第s时刻的预测值和实际值,m为样本总数量。
为了更充分体现所提出的短期负荷预测模型的优越性,设置仅有时间特征和有多特征VMD的LightGBM、XGBoost、长短期记忆网络(long short-term memory,LSTM)、反向传播神经网络(back propagation neural network,BPNN)和Stacking集成学习模型作为对比分析,各模型的评价指标如表2所示。
对比结果发现,多特征的VMD-Stacking集成学习预测模型的误差较小。单一模型中LSTM模型结果出现了滞后性,即使加入了多特征变量和VMD后预测结果也较差;BPNN模型总体评价一般,偶尔预测误差比其他模型更小;LightGBM和XGBoost预测误差相差不大,融合后的Stacking集成学习模型误差更小,尤其是加入了多特征变量后MAPE减少约0.68%。有无多特征变量的Stacking模型预测结果如图5、图6所示,可以看出,加入多特征变量后的VMD-Stacking集成学习模型在负荷变化点处预测得更准确,趋势更贴合实际值。

表2 模型预测结果评价指标
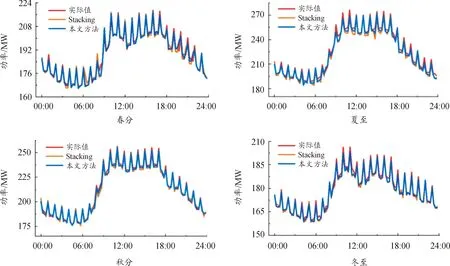
图5 春分、夏至、秋分、冬至预测结果
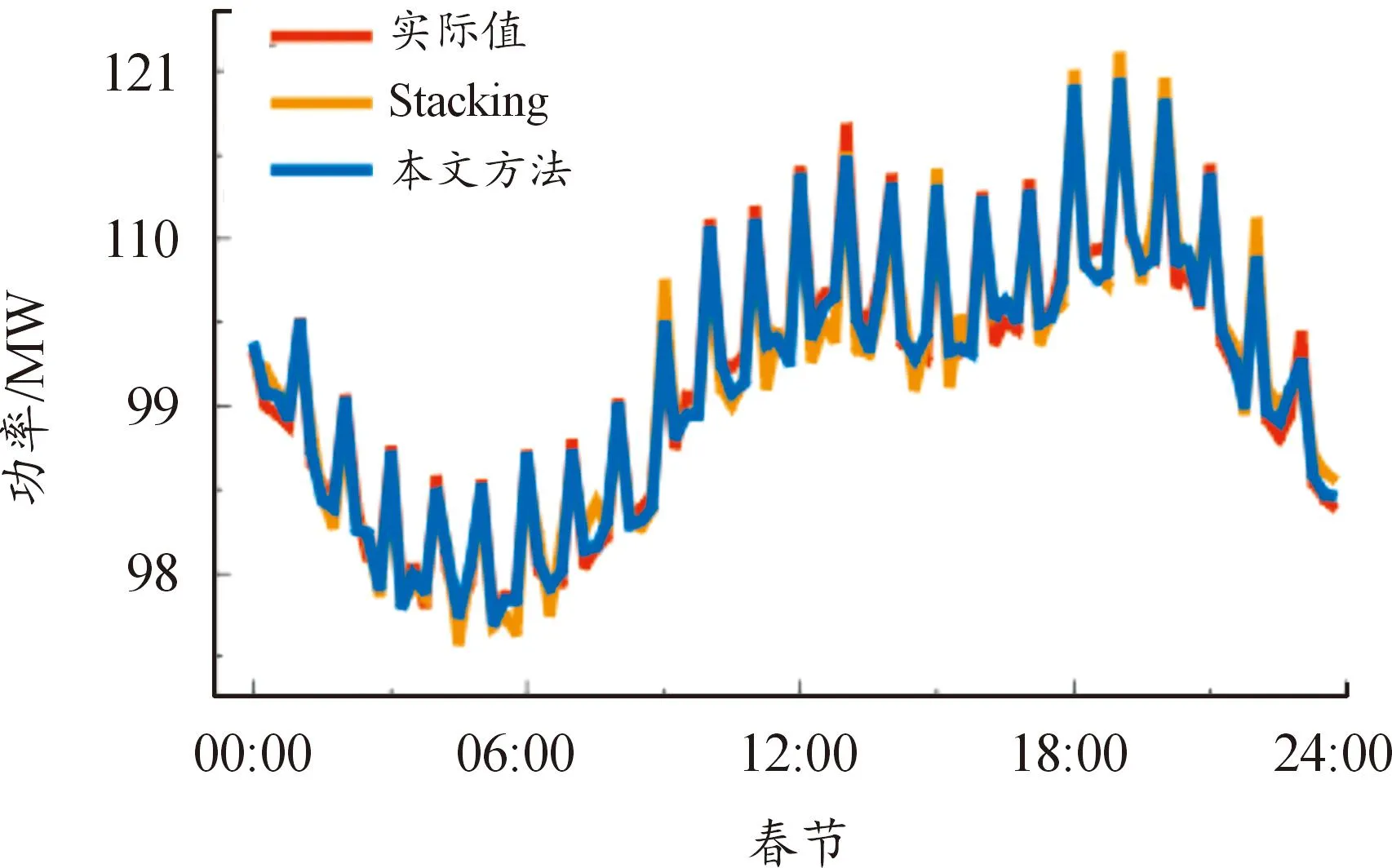
图6 春节预测结果
3 结论
本文中提出了一种VMD-Stacking集成学习的多特征变量短期负荷预测模型,在预测前使用VMD算法将负荷数据分解,然后加入对模型重要性较高的特征变量,再建立由LightGBM与XGBoost融合的Stacking集成学习预测模型,从多种角度来提高预测的准确度,具体体现在:
1) 采用VMD算法分解历史负荷序列,分解后子模态分量的周期性体现了出来,让模型预测波动性较大的负荷时更容易;
2) 温度、天气、农历和节假日情况等影响负荷变化的关键因素有被考虑,模型的准确度得以提高;
3) Stacking集成学习模型对各算法取长补短,泛化能力增强,预测的准确度高于单一模型。
最后,由于融合越多算法的Stacking集成学习模型训练时间越长,文中仅融合了2种算法,未来的研究中可以考虑融合更多算法,或者使用分布式计算来减少模型训练时间、提高准确度。
猜你喜欢
基层中医药(2021年12期)2021-06-05
英美文学研究论丛(2018年1期)2018-08-16
纺织科学研究(2017年6期)2017-07-03
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
核科学与工程(2015年2期)2015-09-26
上海电机学院学报(2015年4期)2015-02-28
电测与仪表(2014年23期)2014-04-04
电测与仪表(2014年14期)2014-04-04
